一、motivation
作者这里认为传统个目标检测的anchor/anchorpoint其实跟detr中的query作用一样,可以看作query
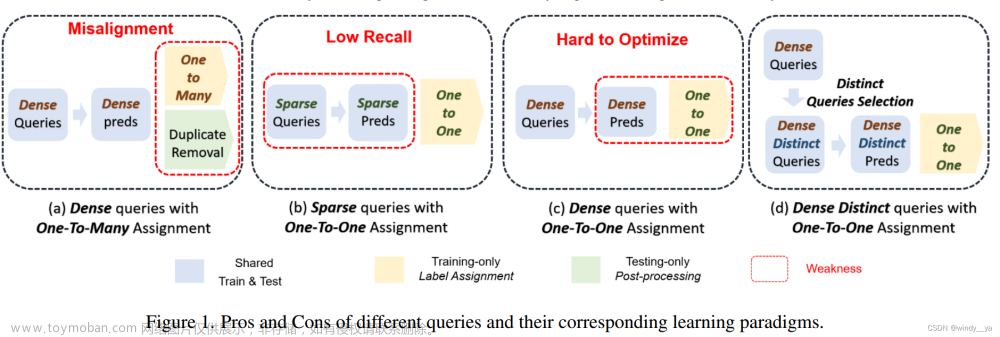
(1)dense query:传统目标检测生成一堆密集anchor,但是one to many需要NMS去除重复框,无法end to end。
(2)spare query 在one2one:egDETR,100个qeury,数量太少造成稀疏监督,收敛慢召回率低。
(3)dense query在one2one:密集的query会有许多的相似的query,会导致相似的query却分配矛盾的label的情况,优化困难低效。
从下面的图(针对one2one)也可以观察【黑色的线,spare-RCNN】:
(1)从50-2000左右,随着query数量增多,AP增大 --> spare query数量太少导致稀疏监督,会影响召回率精度较低(可以看到spareRCNN里300个是不够的);即dense的重要性
(2)2000之后AP随query增大而停滞甚至下降 --> dense query的情况,相似的query很难优化。即distinct的重要性
【补充】相似的query难优化是因为在one2one的匹配中,一个GT对应一个pre,(以detr来说,100个query去学位置信息,decoder输出后要和N个GT去做 二分图匹配,那么就有N个query去分别对应N个GT,剩下的qeury就是no object)。那么在两个相似的query下,一个query对应GT,另一个query就有可能对应的是no object,二者label矛盾,影响优化。

二、innovation:
生成密集的但是不同的query.
三、网络
(一)COMPONENT
1)dense query:
直接从feature map的每一个点来初始化query(其实就是follow传统目标检测,在feature map上铺设一堆平移不变形的anchor)【用卷积/线性 & 滑动窗口】
2)distinct query:
用单类NMS去去除掉相似的query,后续只对保留下的query做loss,用来减轻一对一分配的负担,设置了比较激进的IOU threshold(0.7DDQ-FCN,DDQ-RCNN;0.8DDQ-DETR)
看到这突然在想,那不就是把NMS前置了来实现one2ine吗???但是这个非常妙的地方在于,实现end2end,因为在这里NMS是放到训练里来除掉相似query解决难优化问题的,训练与推理阶段一致,但是传统目标检测的one2many则是在训练结束后的推理阶段加上NMS。
3)loss:
1.二分图匹配来进行one to one
2.辅助损失for dense(leaf query,对密集查询采用软一对多赋值,以允许密集梯度和更多正样本来加速训练??)

(二)将DDQ放到不同范式【FCN、RCNN、DETR】
(1)DDQ in FCN
这里用FPN得到密集query的同时,作者认为密集query是逐卷积处理得到的,所以不同层的query之间缺少交互,所以提出了金字塔洗牌(参考shufflenet通道洗牌),i和i-1、i+1交换,不同大小的采用双线性插值。


1)dense query由FPN得到的不同尺度特征图以及通过滑窗得到dense
2)在cls和reg分支最后两个和一个卷积层做金字塔洗牌来融合不同level之间query的信息。
3)取top1000得到中间黄绿橘(这里取top1000是每个level都取1000?)
4)DDQ:用NMS去保证distinct,这个过程为DQS(dense distinct selection).
5)用DDQ做点积??
6)最后用二分图匹配 one2one
(2)DDQ in R-CNN


1)通过FCN DDQ找到的dense distinct query选取top300作为query【这里就是DQS】。
2)将cls和reg得到的融合为embedding(作为content的输入),然后和proposal一起构成query。
3)将上述query放入sparse-rcnn中的refine head做进一步细化。--> 只需要2stage的细化头,原先sparse要6stage,因为sparsercnn的稀疏查询不能覆盖所有实例,并且可能存在相似的query难区分所以迭代次数多。
(3)DDQ in detr

1)follow DINO-deformable(删掉CDN和mix qeury selection)得到dense query
2)content embedding和deformable不一样(DINO-deformable是通过变换后的四维坐标来的content embedding,但这样只有位置会导致query相似),这里采用个ddq-rcnn一样,把featuer的映射作为content/,使查询更不同;把feature map embedding特征融合到坐标中,让query更不同。
混合查询选择通过额外初始化内容嵌入来增加查询的不同性,但位置嵌入仍然是从top-k密集回归预测创建的,这些预测可能非常相似,仍然阻碍了优化。
3)用单类NMS来选取不同的query
4)蓝色框的DQS:为了和defomabledetr做对比,选取K个query,类似于定量对比吧。
5)选1.5Kquery来做辅助loss。
四、实验
1、
(1)DDQ FCN
【FCOS*表示用二分图匹配,此时实验结果很不稳定24.5-36.5,这里选了最优结果;PS金字塔洗牌,结果稳定且提点;DQS,说明查询的不同对一对一匹配的重要性;DDQ FCN还加了辅助损失】

(2)DDQ R-CNN
【sparsercnn是300query;+7000表示dense query稍微提点,可以看到F非常大,很繁重;+DQS显著提点,不同的重要性;DDQ R-CNN表示前四个refine stage follow FCN,得到了一个性能好且更轻量级的结构】

(3)DDQ DETR
【D-DETR,deformable;TStwosatge??初始化位置;+Dense?加了feature;AUX辅助训练;DQS不同的查询;DDQ DETR,加上了DINO的CDN即去噪训练】

在crowd上的效果
查一下mCR是啥

2、消融
(1)distinct的IOU:
【对于DDQ FCN/R-CNN】可以看到,0.6-0.8鲁棒性较好;0.5抑制太多了,召回率低,影响精度;大于0.8表示要很像才会被抑制,所以删的少了,有部分相似的没被抑制导致难优化精度下降。
还拿ATSS做对比,可以看到ATSS对于参数的敏感,相比之下DDQ更稳定。

对于DDQ DETR
(2)
sparse只有300个query明显低于7000&DQS的recall;
DDQRCNN的设计使的在较小的延迟下取得了和7000个查询相当的性能

--- BASIC ---
1、NMS:详解目标检测NMS算法发展历程(收藏版) - 知乎 (zhihu.com)
如果IOU的threshold太小,会导致一些框被删掉(eg两个离得很近但对应不同物体的预测框,置信度较小的那个框可能会被删掉,导致召回率下降);如果太大最后留下来的框比较多,即可能有假阳的情况。
2、DeFCN(end2end)
这里再看一遍FOCS。

1)backbone提取图像特征,用FPN【这里FPN有两个作用1.不同尺度的特征融合;2.分而治之】得到不同尺度特征图,GT会根据匹配到对应尺度的特征图,可以达到在不同尺度特征图上对应不同大小的目标进行分而治之,即P3可能对应小目标,P7可能对应大目标;
2)放到不同的head中去做类分类(H*W*C,C对应总类别),centerness,回归:先两个cls和reg分支(x4),然后最后接三个分支的一层卷积,分别做分类、回归、cente rness。
3)上图回归出来的centerness是为了得到一个权重,用来抑制哪些离中心点偏远的低质量预测点。(如下图,橘色比绿色效果更好,所以一致绿色这些低质量点)

3.RetonaNet
感觉这里可以参考一下RwtinaNet,忽略前面FPN跟上面的FOCS-like不一样,但是分类和回归的子网络跟上面FCN很类似。

4、sparse RCNN

1)学习position:可学习proposal Boxes(N*4,N一般取100-300)
2)学习feature:可学习的proposal feature(N*d,d代表维度)文章来源:https://www.toymoban.com/news/detail-822552.html
由上面的proposal Box和proposal feature得到ROI feature 去做分类和回归。文章来源地址https://www.toymoban.com/news/detail-822552.html
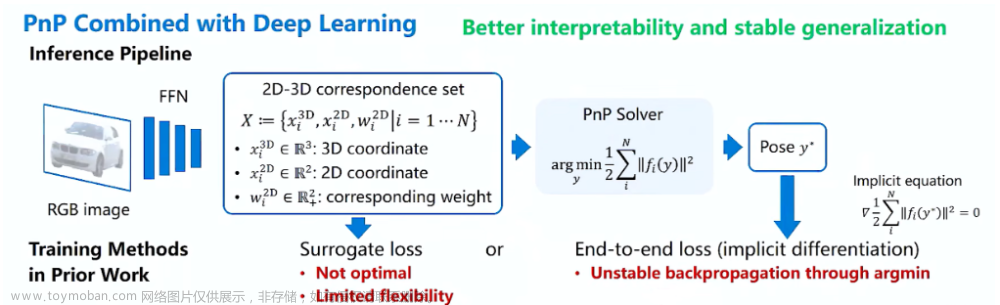
到了这里,关于《Dense Distinct Query for End-to-End Object Detection》论文笔记(ing)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ...](https://imgs.yssmx.com/Uploads/2024/02/435594-1.png)