前言
博主主页👉🏻蜡笔雏田学代码
专栏链接👉🏻【前端面试专栏】
今天继续学习前端面试题相关的知识!
感兴趣的小伙伴一起来看看吧~🤞

Doctype 作用,严格模式与混杂模式如何区分,有何意义
作用是Doctype 声明于文档最前面,告诉浏览器以何种方式来渲染页面。
这里有两种模式,严格模式和混杂模式。
- 严格模式的排版和 JS 运作模式是 以该浏览器支持的最高标准运行。
- 混杂模式,向后兼容,模拟老式浏览器,防止浏览器无法兼容页面。
Cookie 如何防范 XSS 攻击
XSS(跨站脚本攻击)是指攻击者在返回的 HTML 中嵌入 javascript 脚本,为了减轻这些攻击,需要在 HTTP 头部配上set-cookie:
httponly-这个属性可以防止 XSS,它会禁止 javascript 脚本来访问 cookie。
secure- 这个属性告诉浏览器仅在请求为 https 的时候发送 cookie。 结果应该是这样的:Set-Cookie=
<
<
<cookie-value
>
>
>…
cookie 和 session 的区别,localStorage 和 sessionStorage 的区别
HTTP 是一个无状态协议,因此 Cookie 的最大的作用就是存储sessionId 用来唯一标识用户。
- cookie 数据存放在
客户的浏览器上,session 数据存放在服务器上。- cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗,所以 cookie 一般用来存放不敏感的信息,比如 用户设置的网站主题,敏感的信息用 session 存储,比如用户的登陆信息,
考虑到安全应当使用 session。- session 会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,
考虑到减轻服务器性能方面应当使用 cookie。- 单个 cookie 保存的数据不能超过 4K,很多浏览器都限制一个站点最多保存 20 个 cookie。
- session 可以存放于文件,数据库,内存中都可以,cookie 可以在服务器端响应的时候设置,也可以客户端通过 JS 设置
下面从几个方向区分一下 cookie,localStorage,sessionStorage 的区别。
生命周期:
Cookie:可设置失效时间,否则默认为关闭浏览器后失效
LocalStorage:除非被手动清除,否则永久保存
SessionStorage:仅在当前网页会话下有效,关闭页面或浏览器后就会被清除
存放数据:
Cookie:4k 左右
LocalStorage 和 SessionStorage:可以保存 5M 的信息
http 请求:
Cookie:每次都会携带在 http 头中,如果使用 cookie 保存过多数据会带来性能问题
LocalStorage 和 SessionStorage:仅在客户端即浏览器中保存,不参与和服务器的通信
易用性:
Cookie:需要程序员自己封装,原生的 cookie 接口不友好
LocalStorage 和 SessionStorage:即可采用原生接口,亦可再次封装
应用场景:
从安全性来说,因为每次 http 请求都会携带 cookie 信息,这样子浪费了带宽,所以 cookie 应该尽可能的少用,此外 cookie 还需要指定作用域,不可以跨域调用,限制很多,但是用户识别用户登陆来说,cookie还是比storage好用,其他情况下可以用storage,localstorage 可以用来在页面传递参数,sessionstorage 可以用来保存一些临时的数据,防止用户刷新页面后丢失了一些参数。
一句话概括 RESTFUL
就是用 URL 定位资源,用 HTTP 描述操作。
讲讲 viewport 和移动端布局
可以参考这篇文章: 响应式布局的常用解决方案对比(媒体查询、百分比、rem 和 vw/vh)
addEventListener 参数
addEventListener(event, function, useCapture):其中,event 指定事件名;function 指定要事件触发时执行的函数;useCapture 指定事件 是否在捕获或冒泡阶段执行。
http 常用请求头
Authorization:用于表示 HTTP 协议中需要认证资源的认证信息Cookie:由于之前服务器通过Set-Cookie设置的一个HTTP协议CookieContent-Type:请求体的 MIME 类型 (用于 POST 和 PUT 请求中)Origin:发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个 Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)Proxy-Authorization:用于向代理进行认证的认证信息User-Agent:浏览器的身份标识字符串
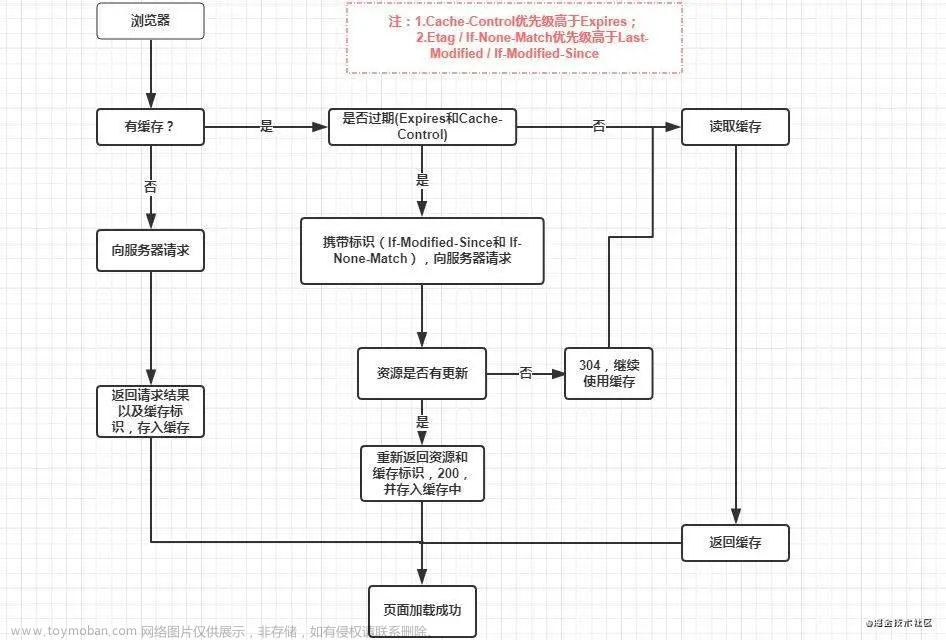
强缓存和协商缓存
缓存分为两种:强缓存和协商缓存,根据响应的 header 内容来决定。
| 缓存类型 | 获取资源形式 | 状态码 | 发送请求到服务器 |
|---|---|---|---|
| 强缓存 | 从缓存取 | 200(from cache) | 否,直接从缓存取 |
| 协商缓存 | 从缓存取 | 304(not modified) | 是,通过服务器来告知缓存是否可用 |
强缓存相关字段有 expires,cache-control。如果 cache-control 与 expires 同时存在的话, cache-control 的优先级高于 expires。
协商缓存相关字段有 Last-Modified/If-Modified-Since,Etag/If-None-Match
强缓存、协商缓存什么时候用?
因为服务器上的资源不是一直固定不变的,大多数情况下它会更新,这个时候如果我们还访问本地缓存,那么对用户来说,那就相当于资源没有更新,用户看到的还是旧的资源;所以我们希望服务器上的资源更新了浏览器就请求新的资源,没有更新就使用本地的缓存,以最大程度地减少因网络请求而产生的资源浪费。
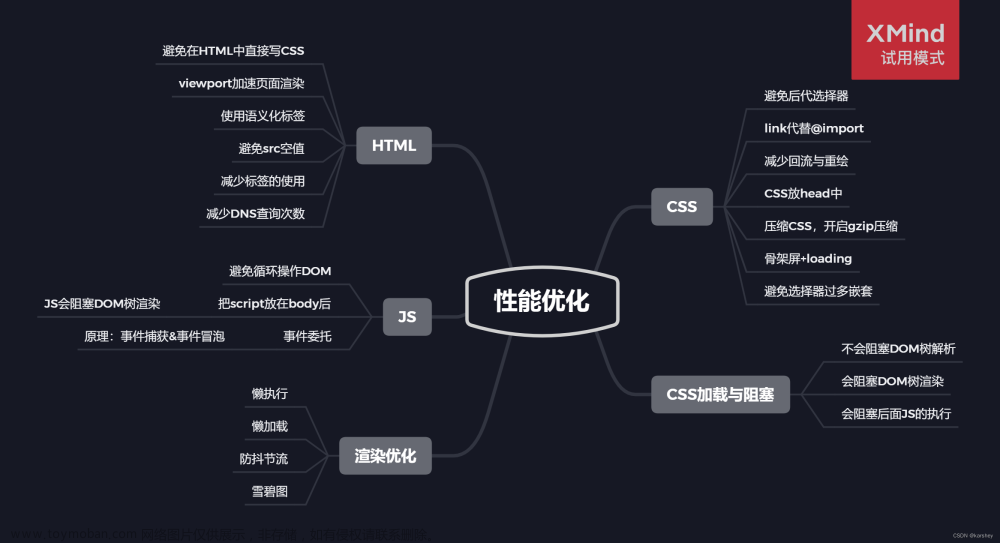
前端优化
降低请求量:合并资源,减少 HTTP 请求数,minify / gzip 压缩,webP,lazyLoad。加快请求速度:预解析 DNS,减少域名数,并行加载,CDN 分发。缓存:HTTP 协议缓存请求,离线缓存 manifest,离线数据缓存 localStorage。渲染:JS/CSS 优化,加载顺序,服务端渲染,pipeline。
GET 和 POST 的区别
get 参数通过 url 传递,post 放在 request body 中。
get 请求在 url 中传递的参数是有长度限制的,而 post 没有。
get 比 post 更不安全,因为参数直接暴露在 url 中,所以不能用来传递敏感信息。
get 请求只能进行 url 编码,而 post 支持多种编码方式。get 请求参数会被完整保留在浏览历史记录里,而 post 中的参数不会被保留。
get 和 post 本质上就是 TCP 连接,并无差别。但是由于 HTTP 的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
get 产生一个 TCP 数据包;post 产生两个 TCP 数据包。
HTTP 支持的方法
GET, POST, HEAD, OPTIONS, PUT, DELETE, TRACE, CONNECT
HTML5 新增的元素
首先 html5 为了更好的实践 web 语义化,增加了 header,footer,nav,aside,section 等语义化标签,在表单方面,为了增强表单,为 input 增加了 color,emial,data,range 等类型, 在存储方面,提供了 sessionStorage,localStorage,和离线存储,通过这些存储方式方便数据在客户端的存储和获取,在多媒体方面规定了音频和视频元素 audio 和 vedio,另外还有地理定位,canvas 画布,拖放,多线程编程的 web worker 和 websocket 协议。文章来源:https://www.toymoban.com/news/detail-822611.html
今天的分享就到这里啦✨ \textcolor{red}{今天的分享就到这里啦✨} 今天的分享就到这里啦✨
原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
🤞 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{green}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{green}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!
文章来源地址https://www.toymoban.com/news/detail-822611.html
到了这里,关于【学姐面试宝典】—— 前端基础篇Ⅱ(HTTP/HTML/浏览器)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!