目录
一. 前言
二. Canal 简介和使用场景
2.1. Canal 简介
2.2. Canal 使用场景
三. Canal Server 设计
3.1. 整体设计
3.2. EventParser 设计
3.3. CanalLogPositionManager 设计
3.4. CanalHAController 类图设计
3.5. EventSink 类图设计和扩展
3.6. EventStore 类图设计和扩展
3.7. MetaManager 类图设计和扩展
四. Canal Client 设计
4.1. 整体设计
4.2. Server/Client交互协议
五. Canal 配置信息
5.1. Canal 配置方式
5.2. canal.properties
5.3. instance.properties
5.4. instance.xml 配置文件
六. Canal 使用
6.1. Canal 下载
6.2. MySql 配置
6.3. canal-server 使用
6.4. canal-adapter 使用
6.5. canal-admin 使用
6.6. 数据同步演示
一. 前言
Canal 是阿里开源的一款基于 MySql 数据库 binlog 的增量订阅和消费组件,通过它可以订阅数据库的 binlog 日志,然后进行一些数据消费,如数据镜像、数据异构、数据索引、缓存更新等。相对于消息队列,通过这种机制可以实现数据的有序化和一致性。
Canal 主要用途是对 MySql 数据库增量日志进行解析,提供增量数据的订阅和消费,简单说就是可以对 MySql 的增量数据进行实时同步,支持同步到 MySql、ElasticSearch、HBase 等数据存储中去。
二. Canal 简介和使用场景
2.1. Canal 简介


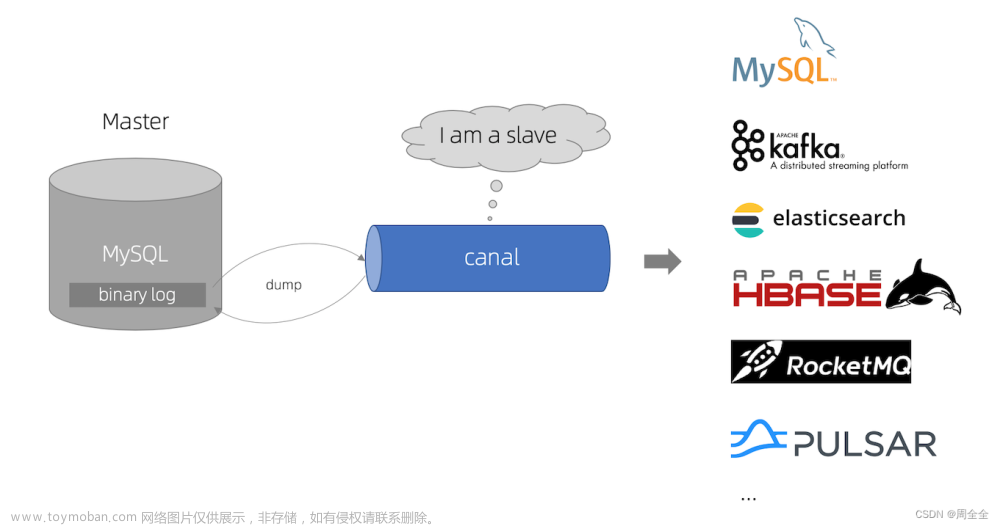
由上面两张图片可知:
- Canal 模拟 MySql Slave 的交互协议,伪装自己为 MySql Slave ,向 MySql Master 发送dump 协议。
- MySql Master 收到 dump 请求,开始推送 binary log 给 Slave (即 Canal )。
- Canal 解析 binary log 对象(原始为 byte 流)。
- Canal 对外提供增量数据订阅和消费,提供 Kafka、RocketMQ、RabbitMq、Es、Tcp 等组件来消费。
2.2. Canal 使用场景
1. 同步缓存 Redis/全文搜索 ES:Canal 一个常见应用场景是同步缓存/全文搜索,当数据库变更后通过 binlog 进行缓存/ES 的增量更新。当缓存/ES 更新出现问题时,应该回退 binlog 到过去某个位置进行重新同步,并提供全量刷新缓存/ES 的方法。
2. 下发任务:另一种常见应用场景是下发任务,当数据变更时需要通知其他依赖系统。其原理是任务系统监听数据库变更,然后将变更的数据写入 MQ(比如 Kafka) 进行任务下发,比如商品数据变更后需要通知商品详情页、列表页、搜索页等相关系统。这种方式可以保证数据下发的精确性,通过 MQ 发送消息通知变更缓存是无法做到这一点的,而且业务系统中不会散落着各种下发 MQ 的代码,从而实现了下发归集。
3. 数据异构:在大型网站架构中,DB 都会采用分库分表来解决容量和性能问题,但分库分表之后带来的新问题。比如不同维度的查询或者聚合查询,此时就会非常棘手。一般我们会通过数据异构机制来解决此问题。所谓的数据异构,那就是将需要 join 查询的多表按照某一个维度又聚合在一个DB 中,让你去查询。Canal 就是实现数据异构的手段之一。
三. Canal Server 设计
3.1. 整体设计

Server 代表一个 Canal 运行实例,对应于一个 JVM。
Instance 对应于一个数据队列(1个 Canal Server 对应 1..n 个 Instance),Instance 下的子模块:
- EventParser:数据源接入,模拟 slave 协议和 master 进行交互,协议解析;
- EventSink:Parser 和 Store 链接器,进行数据过滤,加工,分发的工作;
- EventStore:数据存储;
- MetaManager:增量订阅 & 消费信息管理器。
整体类图设计:

- CanalLifeCycle:所有 Canal 模块的生命周期接口;
- CanalInstance:组合 Parser、Sink、Store 三个子模块,三个子模块的生命周期统一受 CanalInstance 管理;
- CanalServer:聚合了多个 CanalInstance。
3.2. EventParser 设计

每个 EventParser 都会关联两个内部组件:
- CanalLogPositionManager : 记录binlog 最后一次解析成功位置信息,主要是描述下一次canal启动的位点
- CanalHAController: 控制 EventParser 的链接主机管理,判断当前该链接哪个mysql数据库
目前开源版本只支持 MySql binlog , 默认通过 MySql binlog dump 远程获取 binlog,但也可以使用 LocalBinlog - 类 relay log 模式,直接消费本地文件中的 binlog。
3.3. CanalLogPositionManager 设计

- 如果 CanalEventStore 选择的是内存模式,可不保留解析位置,下一次 Canal 启动时直接依赖 CanalMetaManager 记录的最后一次消费成功的位点即可(最后一次 ack 提交的数据位点)。
- 如果 CanalEventStore 选择的是持久化模式,可通过 Zookeeper 记录位点信息,Canal Instance 发生 failover 切换到另一台机器,可通过读取 Zookeeper 获取位点信息。
- 可通过实现自己的 CanalLogPositionManager,比如记录位点信息到本地文件 /nas 文件实现简单可用的无 HA 模式。
3.4. CanalHAController 类图设计

- 失败检测常见方式可定时发送心跳语句到当前链接的数据库,超过一定次数检测失败时,尝试切换到备机。
- 如果有一套数据库主备信息管理系统,当数据库主备切换或者机器下线,推送配置到各个应用节点,HAController 收到后,控制 EventParser 进行链接切换。
3.5. EventSink 类图设计和扩展


- 数据过滤:支持通配符的过滤模式,表名,字段内容等。
- 数据路由/分发:解决 1:n(1个 Parser 对应多个 Store 的模式)。
- 数据归并:解决 n:1(多个 Parser 对应1个 Store)。
- 数据加工:在进入 store 之前进行额外的处理,比如 join。
数据 1:n 业务:
为了合理的利用数据库资源, 一般常见的业务都是按照 schema 进行隔离,然后在 MySql 上层或者 dao 这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过 cobar/tddl 来解决数据源路由问题。所以,一般一个数据库实例上,会部署多个 schema,每个 schema 会有1个或者多个业务方关注。
数据 n:1 业务:
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个 Store 进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局Id 进行排序归并。
3.6. EventStore 类图设计和扩展

1. 抽象 CanalStoreScavenge , 解决数据的清理,比如定时清理,满了之后清理,每次 ack 清理等。
2. CanalEventStore 接口,主要包含 put/get/ack/rollback 的相关接口。put/get 操作会组成一个生产者/消费者模式,每个 Store 都会有存储大小设计,存储满了,put 操作会阻塞等待 get 获取数据,所以不会无线占用存储,比如内存大小:
- EventStore 目前实现了 memory 模式,支持按照内存大小和内存记录数进行存储大小限制。
- 后续可开发基于本地文件的存储模式。
- 基于文件存储和内存存储,开发 mixed 模式,做成两级队列,内存 buffer 有空位时,将文件的数据读入到内存 buffer 中(可以通过配置进行配置)。
- mixed 模式实现可以让 Canal 落地消费/订阅的模型,取 1 份 binlog 数据,提供多个客户端消费,消费有快有慢,各自保留消费位点。
3.7. MetaManager 类图设计和扩展

- MetaManager 目前支持了多种模式,最顶层 Memory 和 Zookeeper 模式,然后是 mixed 模式-先写内存,再写 Zookeeper。
- 可通过实现自己的 CanalMetaManager,比如记录位点信息到本地文件 /nas 文件,简单可用的无 HA 模式。
四. Canal Client 设计
4.1. 整体设计
在了解具体 API 之前,需要提前了解下 Canal Client 的类设计,这样才可以正确的使用好 Canal。

大致分为几部分:
- ClientIdentity:Canal Client 和 Server 交互之间的身份标识,目前 clientId 写死为1001。(目前 Canal Server 上的一个 Instance 只能有一个 Client 消费,ClientId 的设计是为1个Instance 多 Client 消费模式而预留的,暂时不需要理会)。
- CanalConnector:SimpleCanalConnector/ClusterCanalConnector 是两种 Connector 的实现,Simple 针对的是简单的 ip 直连模式,Cluster针对多 ip 的模式,可依赖CanalNodeAccessStrategy 进行 failover 控制。
- CanalNodeAccessStrategy:SimpleNodeAccessStrategy/ClusterNodeAccessStrategy 是两种 failover 的实现,Simple 针对给定的初始 ip 列表进行 failover 选择,Cluster 基于Zookeeper上的 Cluster 节点动态选择正在运行的 Canal Server。
- ClientRunningMonitor/ClientRunningListener/ClientRunningData:Client Running 相关控制,主要为解决 Client 自身的 failover 机制。Canal Client 允许同时启动多个 Canal Client,通过 Running 机制,可保证只有一个 Client 在工作,其他 Client 做为冷备。当运行中的Client 挂了,Running 会控制让冷备中的 Client 转为工作模式,这样就可以确保 Canal Client 也不会是单点,保证整个系统的高可用性。
4.2. Server/Client交互协议

get/ack/rollback 协议介绍:
-
Message getWithoutAck(int batchSize),允许指定 batchSize,一次可以获取多条,每次返回的对象为 message,包含的内容为:
a. batch id:唯一标识;
b. entries:具体的数据对象,可参见下面的数据介绍。 -
getWithoutAck(int batchSize, Long timeout, TimeUnit unit),相比于 getWithoutAck(int batchSize),允许设定获取数据的 timeout 超时时间:
a. 拿够 batchSize 条记录或者超过 timeout 时间;
b. timeout=0,阻塞等到足够的 batchSize。 - void rollback(long batchId),顾命思议,回滚上次的 get 请求,重新获取数据。基于 get 获取的 batchId 进行提交,避免误操作。
- void ack(long batchId),顾命思议,确认已经消费成功,通知 Server 删除数据。基于 get获取的 batchId 进行提交,避免误操作。
Canal 的 get/ack/rollback 协议和常规的 jms 协议有所不同,允许 get/ack 异步处理,比如可以连续调用 get 多次,后续异步按顺序提交 ack/rollback,项目中称之为流式 API。
流式 API 设计的好处:
- get/ack 异步化,减少因 ack 带来的网络延迟和操作成本(99%的状态都是处于正常状态,异常的 rollback 属于个别情况,没必要为个别的 case 牺牲整个性能)。
- get 获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询 get 数据,不停的往后发送任务,提高并行化。(作者在实际业务中的一个 case:业务数据消费需要跨中美网络,所以一次操作基本在 200ms 以上,为了减少延迟,所以需要实施并行化)。
流式 API 设计:

- 每次 get 操作都会在 meta 中产生一个 mark,mark 标记会递增,保证运行过程中 mark 的唯一性;
- 每次的 get 操作,都会在上一次的 mark 操作记录的 cursor 继续往后取,如果 mark 不存在,则在 last ack cursor 继续往后取;
- 进行 ack 时,需要按照 mark 的顺序进行数序 ack,不能跳跃 ack。ack 会删除当前的 mark 标记,并将对应的 mark 位置更新为 last ack cursor;
- 一旦出现异常情况,客户端可发起 rollback 情况,重新置位:删除所有的 mark,清理 get 请求位置,下次请求会从 last ack cursor 继续往后取。
流式 API 带来的异步响应模型:

五. Canal 配置信息

5.1. Canal 配置方式
Canal 配置方式有两种:
- ManagerCanalInstanceGenerator:基于 Manager 管理的配置方式,目前 Alibaba 内部配置使用这种方式。大家可以实现 CanalConfigClient,连接各自的管理系统,即可完成接入。
- SpringCanalInstanceGenerator:基于本地 spring xml 的配置方式,目前开源版本已经自带该功能所有代码,建议使用。
Spring 配置:
Spring 配置的原理是将整个配置抽象为两部分:
- xxxx-instance.xml(Canal 组件的配置定义,可以在多个 Instance 配置中共享);
- xxxx.properties(每个 Instance 通道都有各自一份定义,因为每个 MySql 的 ip,帐号,密码等信息不会相同)。
通过 Spring 的 PropertyPlaceholderConfigurer 机制将其融合,生成一份 Instance 实例对象,每个Instance 对应的组件都是相互独立的,互不影响。
properties 配置文件分为两部分:
- canal.properties(系统根配置文件),下面详细说明;
- instance.properties(Instance 级别的配置文件,每个 Instance 一份)。
5.2. canal.properties
Canal 配置主要分为两部分定义:
1. instance 列表定义,(列出当前 Server 上有多少个 Instance,每个 Instance 的加载方式是Spring/Manager 等) 以下选一些重要的参数说明一下:
| 参数名字 | 参数说明 | 默认值 |
|---|---|---|
| canal.auto.scan | 开启instance自动扫描 如果配置为true,canal.conf.dir目录下的instance配置变化会自动触发: a. instance目录新增: 触发instance配置载入,lazy为true时则自动启动 b. instance目录删除:卸载对应instance配置,如已启动则进行关闭 c. instance.properties文件变化:reload instance配置,如已启动自动进行重启操作 |
true |
| canal.instance.global.spring.xml | 全局的spring配置方式的组件文件 | lasspath:spring/memory-instance.xml (spring目录相对于canal.conf.dir) |
2. common 参数定义,比如可以将 instance.properties 的公用参数,抽取放置到这里,这样每个Instance 启动的时候就可以共享。【instance.properties 配置定义优先级高于 canal.properties】以下选一些重要的参数说明一下:
| 参数名字 | 参数说明 | 默认值 |
|---|---|---|
| canal.register.ip | canal server注册到外部zookeeper、admin的ip信息 (针对docker的外部可见ip) | 无 |
| canal.zookeeper.flush.period | canal持久化数据到zookeeper上的更新频率,单位毫秒 | 1000 |
| canal.instance.memory.batch.mode | canal内存store中数据缓存模式 1. ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量 2. MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录的大小 |
MEMSIZE |
| canal.instance.memory.buffer.size | canal内存store中可缓存buffer记录数,需要为2的指数 | 16384 |
| canal.instance.memory.buffer.memunit | 内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小 | 1024 |
| canal.instance.filter.druid.ddl | 是否使用druid处理所有的ddl解析来获取库和表名 | true |
| canal.instance.filter.query.dml | 是否忽略dml语句 (mysql5.6之后,在row模式下每条DML语句也会记录SQL到binlog中,可参考MySQL文档) |
false |
| canal.instance.parser.parallel | 是否开启binlog并行解析模式 (串行解析资源占用少,但性能有瓶颈, 并行解析可以提升近2.5倍+) |
true |
| canal.admin.manager | canal链接canal-admin的地址 (v1.1.4新增) | 无 |
5.3. instance.properties
在 canal.properties 定义了 canal.destinations 后,需要在 canal.conf.dir 对应的目录下建立同名的文件。
如果 canal.properties 未定义 instance 列表,但开启了 canal.auto.scan 时:
- Server 第一次启动时,会自动扫描 conf 目录下,将文件名做为 instance name,启动对应的instance;
- Server 运行过程中,会根据 canal.auto.scan.interval 定义的频率,进行扫描:
1. 发现目录有新增,启动新的 Instance;
2. 发现目录有删除,关闭老的 Instance;
3. 发现对应目录的 instance.properties 有变化,重启 Instance。
instance.properties 参数列表(部分):
| 参数名字 | 参数说明 | 默认值 |
|---|---|---|
| canal.instance.mysql.slaveId | mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 (v1.1.x版本之后canal会自动生成,不需要手工指定) |
无 |
| canal.instance.filter.regex | mysql 数据解析关注的表,Perl正则表达式. 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
1. 所有表:.* or .*\\..* 5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔) |
.*\\..* |
| canal.instance.filter.black.regex | mysql 数据解析表的黑名单,表达式规则见白名单的规则 | 无 |
| canal.instance.master.journal.name | mysql主库链接时起始的binlog文件 | 无 |
| canal.instance.master.position | mysql主库链接时起始的binlog偏移量 | 无 |
| canal.instance.master.timestamp | mysql主库链接时起始的binlog的时间戳 | 无 |
几点说明:
1. MySql 链接时的起始位置
- canal.instance.master.journal.name + canal.instance.master.position:精确指定一个 binlog位点,进行启动。
- canal.instance.master.timestamp:指定一个时间戳,Canal 会自动遍历 mysql binlog,找到对应时间戳的 binlog 位点后,进行启动。
- 不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
2. MySql 解析关注表定义
- 标准的Perl正则,注意转义时需要双斜杠:\\。
3. MySql 链接的编码
- 目前 Canal 版本仅支持一个数据库只有一种编码,如果一个库存在多个编码,需要通过filter.regex 配置,将其拆分为多个 canal instance,为每个 Instance 指定不同的编码。
5.4. instance.xml 配置文件
目前默认支持的 instance.xml 有以下几种:
- spring/memory-instance.xml
- spring/default-instance.xml
- spring/group-instance.xml
在介绍 instance 配置之前,先了解一下 Canal 如何维护一份增量订阅&消费的关系信息:
- 解析位点(Parse 模块会记录,上一次解析 binlog 到了什么位置,对应组件为:CanalLogPositionManager)。
- 消费位点(Canal Server 在接收了客户端的 ack 后,就会记录客户端提交的最后位点,对应的组件为:CanalMetaManager)。
对应的两个位点组件,目前都有几种实现:
- Memory(memory-instance.xml 中使用)。
- Zookeeper。
- Mixed。
- Period(default-instance.xml 中使用,集合了 Zookeeper+Memory 模式,先写内存,定时刷新数据到 Zookeeper 上)。
memory-instance.xml 介绍:
所有的组件(parser、sink、store)都选择了内存版模式,记录位点的都选择了 Memory 模式,重启后又会回到初始位点进行解析。
特点:速度最快,依赖最少(不需要 Zookeeper)。
场景:一般应用在 quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境。
default-instance.xml 介绍:
Store 选择了内存模式,其余的 parser/sink 依赖的位点管理选择了持久化模式,目前持久化的方式主要是写入 Zookeeper,保证数据集群共享。
特点:支持 HA。
场景:生产环境,集群化部署。
group-instance.xml 介绍:
主要针对需要进行多库合并时,可以将多个物理 Instance 合并为一个逻辑 Instance,提供客户端访问。
场景:分库业务。比如产品数据拆分了4个库,每个库会有一个 Instance,如果不用 Group,业务上要消费数据时,需要启动4个客户端,分别链接4个 Instance 实例。使用 Group后,可以在 Canal Server 上合并为一个逻辑 Instance,只需要启动1个客户端,链接这个逻辑 Instance即可。
六. Canal 使用
接下来我们来学习下 Canal 的使用,以 MySql 实时同步数据到 ElasticSearch为例。
6.1. Canal 下载
首先我们需要下载 Canal 的各个组件 canal-server、canal-adapter、canal-admin。
下载地址:https://github.com/alibaba/canal/releases。
Canal 官方文档:https://github.com/alibaba/canal/wiki。

Canal 的各个组件的用途各不相同,下面分别介绍下:
- canal-server(canal-deploy):可以直接监听 MySql 的 binlog,把自己伪装成 MySql 的从库,只负责接收数据,并不做处理。
- canal-adapter:相当于 Canal 的客户端,会从 canal-server 中获取数据,然后对数据进行同步,可以同步到 MySql、ElasticSearch 和 HBase 等存储中去。
- canal-admin:为 Canal 提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI 操作界面,方便更多用户快速和安全的操作。
由于不同版本的 MySql、ElasticSearch 和 Canal 会有兼容性问题,所以我们先对其使用版本做个约定:
| 应用 | 端口 | 版本 |
|---|---|---|
| MySql | 3306 | 5.7 |
| ElasticSearch | 9200 | 7.6.2 |
| Kibanba | 5601 | 7.6.2 |
| canal-server | 11111 | 1.1.15 |
| canal-adapter | 8081 | 1.1.15 |
| canal-admin | 8089 | 1.1.15 |
6.2. MySql 配置
由于 Canal 是通过订阅 MySql 的 binlog 来实现数据同步的,所以我们需要开启 MySql 的 binlog写入功能,并设置 binlog-format 为 ROW 模式,我的配置文件为 /mydata/mysql/conf/my.cnf,改为如下内容即可:
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=row
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062配置完成后需要重新启动 MySql,重启成功后通过如下命令查看 binlog 是否启用:
show variables like '%log_bin%'
+---------------------------------+-------------------------------------+
| Variable_name | Value |
+---------------------------------+-------------------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/mall-mysql-bin |
| log_bin_index | /var/lib/mysql/mall-mysql-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+-------------------------------------+再查看下 MySql 的 binlog 模式:
show variables like 'binlog_format%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+接下来需要创建一个拥有从库权限的账号,用于订阅 binlog,这里创建的账号为 canal:canal:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;创建好测试用的数据库 canal-test,之后创建一张商品表 product,建表语句如下:
CREATE TABLE `product` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`sub_title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`price` decimal(10, 2) NULL DEFAULT NULL,
`pic` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;6.3. canal-server 使用
将我们下载好的压缩包 canal.deployer-1.1.5-SNAPSHOT.tar.gz 上传到 Linux 服务器,然后解压到指定目录 /mydata/canal-server,可使用如下命令解压:
tar -zxvf canal.deployer-1.1.5-SNAPSHOT.tar.gz解压完成后目录结构如下:
├── bin
│ ├── restart.sh
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
├── conf
│ ├── canal_local.properties
│ ├── canal.properties
│ └── example
│ └── instance.properties
├── lib
├── logs
│ ├── canal
│ │ └── canal.log
│ └── example
│ ├── example.log
│ └── example.log
└── plugin修改配置文件 conf/example/instance.properties,按如下配置即可,主要是修改数据库相关配置:
# 需要同步数据的MySQL地址
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# 用于同步数据的数据库账号
canal.instance.dbUsername=canal
# 用于同步数据的数据库密码
canal.instance.dbPassword=canal
# 数据库连接编码
canal.instance.connectionCharset = UTF-8
# 需要订阅binlog的表过滤正则表达式
canal.instance.filter.regex=.*\\..*使用 startup.sh 脚本启动 canal-server 服务:
sh bin/startup.sh启动成功后可使用如下命令查看服务日志信息:
tail -f logs/canal/canal.log
2020-10-26 16:18:13.354 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[172.17.0.1(172.17.0.1):11111]
2020-10-26 16:18:19.978 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is r启动成功后可使用如下命令查看 instance 日志信息:
tail -f logs/example/example.log
2020-10-26 16:18:16.056 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
2020-10-26 16:18:16.061 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]
2020-10-26 16:18:18.259 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2020-10-26 16:18:18.282 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
2020-10-26 16:18:18.282 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$
2020-10-26 16:18:19.543 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2020-10-26 16:18:19.578 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
2020-10-26 16:18:19.912 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just last position
{"identity":{"slaveId":-1,"sourceAddress":{"address":"localhost","port":3306}},"postion":{"gtid":"","included":false,"journalName":"mall-mysql-bin.000006","position":2271,"serverId":101,"timestamp":1603682664000}}
2020-10-26 16:18:22.435 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbou如果想要停止 canal-server 服务可以使用如下命令:
sh bin/stop.sh6.4. canal-adapter 使用
将我们下载好的压缩包 canal.adapter-1.1.5-SNAPSHOT.tar.gz 上传到 Linux 服务器,然后解压到指定目录 /mydata/canal-adpter,解压完成后目录结构如下:
├── bin
│ ├── adapter.pid
│ ├── restart.sh
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
├── conf
│ ├── application.yml
│ ├── es6
│ ├── es7
│ │ ├── biz_order.yml
│ │ ├── customer.yml
│ │ └── product.yml
│ ├── hbase
│ ├── kudu
│ ├── logback.xml
│ ├── META-INF
│ │ └── spring.factories
│ └── rdb
├── lib
├── logs
│ └── adapter
│ └── adapter.log
└── plugin修改配置文件 conf/application.yml,按如下配置即可,主要是修改 canal-server 配置、数据源配置和客户端适配器配置:
canal.conf:
mode: tcp # 客户端的模式,可选tcp kafka rocketMQ
flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效
zookeeperHosts: # 对应集群模式下的zk地址
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数, -1为无限重试
timeout: # 同步超时时间, 单位毫秒
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111 #设置canal-server的地址
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources: # 源数据库配置
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/canal_test?useUnicode=true
username: canal
password: canal
canalAdapters: # 适配器列表
- instance: example # canal实例名或者MQ topic名
groups: # 分组列表
- groupId: g1 # 分组id, 如果是MQ模式将用到该值
outerAdapters:
- name: logger # 日志打印适配器
- name: es7 # ES同步适配器
hosts: 127.0.0.1:9200 # ES连接地址
properties:
mode: rest # 模式可选transport(9300) 或者 rest(9200)
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch # ES集群名称添加配置文件 canal-adapter/conf/es7/product.yml,用于配置 MySql 中的表与 ElasticSearch 中索引的映射关系:
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # canal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: canal_product # es 的索引名称
_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
sql: "SELECT
p.id AS _id,
p.title,
p.sub_title,
p.price,
p.pic
FROM
product p" # sql映射
etlCondition: "where a.c_time>={}" #etl的条件参数
commitBatch: 3000 # 提交批大小使用 startup.sh 脚本启动 canal-adapter 服务:
sh bin/startup.sh启动成功后可使用如下命令查看服务日志信息:
tail -f logs/adapter/adapter.log
20-10-26 16:52:55.148 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: logger succeed
2020-10-26 16:52:57.005 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## Start loading es mapping config ...
2020-10-26 16:52:57.376 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## ES mapping config loaded
2020-10-26 16:52:58.615 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 succeed
2020-10-26 16:52:58.651 [main] INFO c.alibaba.otter.canal.connector.core.spi.ExtensionLoader - extension classpath dir: /mydata/canal-adapter/plugin
2020-10-26 16:52:59.043 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal-client mq topic: example-g1 succeed
2020-10-26 16:52:59.044 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ......
2020-10-26 16:52:59.057 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Start to connect destination: example <=============
2020-10-26 16:52:59.100 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8081"]
2020-10-26 16:52:59.153 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2020-10-26 16:52:59.590 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8081 (http) with context path ''
2020-10-26 16:52:59.626 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 31.278 seconds (JVM running for 33.99)
2020-10-26 16:52:59.930 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Subscribe destination: example succeed <=============如果需要停止 canal-adapter 服务可以使用如下命令:
sh bin/stop.sh6.5. canal-admin 使用
将我们下载好的压缩包 canal.admin-1.1.5-SNAPSHOT.tar.gz 上传到 Linux 服务器,然后解压到指定目录 /mydata/canal-admin,解压完成后目录结构如下:
├── bin
│ ├── restart.sh
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
├── conf
│ ├── application.yml
│ ├── canal_manager.sql
│ ├── canal-template.properties
│ ├── instance-template.properties
│ ├── logback.xml
│ └── public
│ ├── avatar.gif
│ ├── index.html
│ ├── logo.png
│ └── static
├── lib
└── logs创建 canal-admin 需要使用的数据库 canal_manager,创建 SQL 脚本为 /mydata/canal-admin/conf/canal_manager.sql,会创建如下表:

修改配置文件 conf/application.yml,按如下配置即可,主要是修改数据源配置和 canal-admin 的管理账号配置,注意需要用一个有读写权限的数据库账号,比如管理账号 root:root:
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin接下来对之前搭建的 canal-server 的 conf/canal_local.properties 文件进行配置,主要是修改canal-admin 的配置,修改完成后使用 sh bin/startup.sh local 重启 canal-server:
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =使用 startup.sh 脚本启动 canal-admin 服务:
sh bin/startup.sh启动成功后可使用如下命令查看服务日志信息:
tail -f logs/admin.log
020-10-27 10:15:04.210 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8089"]
2020-10-27 10:15:04.308 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2020-10-27 10:15:04.534 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8089 (http) with context path ''
2020-10-27 10:15:04.573 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - Started CanalAdminApplication in 31.203 seconds (JVM running for 34.865)访问 canal-admin 的 Web 界面,输入账号密码 admin:123456 即可登录,访问地址:http://192.168.3.101:8089

登录成功后即可使用 Web 界面操作 canal-server:

6.6. 数据同步演示
经过上面的一系列步骤,Canal 的数据同步功能已经基本可以使用了,下面我们来演示下数据同步功能。
首先我们需要在 ElasticSearch 中创建索引,和 MySql 中的 product 表相对应,直接在 Kibana 的Dev Tools 中使用如下命令创建即可:
PUT canal_product
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"sub_title": {
"type": "text"
},
"pic": {
"type": "text"
},
"price": {
"type": "double"
}
}
}
}
创建完成后可以查看下索引的结构:

之后使用如下 SQL 语句在数据库中创建一条记录:
INSERT INTO product ( id, title, sub_title, price, pic ) VALUES ( 5, '小米8', ' 全面屏游戏智能手机 6GB+64GB', 1999.00, NULL创建成功后,在 ElasticSearch 中搜索下,发现数据已经同步了:

再使用如下 SQL 对数据进行修改:
UPDATE product SET title='小米10' WHERE id=5修改成功后,在 ElasticSearch 中搜索下,发现数据已经修改了:

再使用如下 SQL 对数据进行删除操作:
DELETE FROM product WHERE id=5删除成功后,在 ElasticSearch 中搜索下,发现数据已经删除了,至此 MySql 同步到 ElasticSearch的功能完成了!文章来源:https://www.toymoban.com/news/detail-822714.html
 文章来源地址https://www.toymoban.com/news/detail-822714.html
文章来源地址https://www.toymoban.com/news/detail-822714.html
到了这里,关于Canal —— 一款 MySql 实时同步到 ES 的阿里开源神器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!