inet_init是如何被调用的?从start_kernel到inet_init调用路径
在 Linux 内核启动过程中,inet_init 函数是通过以下路径被调用的:
1.start_kernel 函数是内核的入口点,它位于 init/main.c 文件中。
2.在 start_kernel 函数中,会调用 rest_init 函数来初始化系统的剩余部分。
3.rest_init 函数中会调用 kernel_init 函数,该函数位于 init/main.c 文件中。
4.在 kernel_init 函数中,会调用 do_basic_setup 函数来进行一些基本的系统设置。
5.在 do_basic_setup 函数中,会调用 device_initcall 宏,该宏会依次调用一系列设备初始化函数。
6.其中,device_initcall 宏会调用 do_initcalls 函数。
7.在 do_initcalls 函数中,会调用 __do_initcall_level 函数来执行各个级别的初始化函数。
8.在初始化级别为 SUBSYS_FINAL 的阶段,__do_initcall_level 函数会调用 inet_init 函数。
9.在 inet_init 函数中进行了网络子系统的初始化。
asmlinkage __visible void __init start_kernel(void)
{
char *command_line;
char *after_dashes;
set_task_stack_end_magic(&init_task);
smp_setup_processor_id();
debug_objects_early_init();
cgroup_init_early();
local_irq_disable();
early_boot_irqs_disabled = true;
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them.
*/
boot_cpu_init();
page_address_init();
pr_notice("%s", linux_banner);
setup_arch(&command_line);
mm_init_cpumask(&init_mm);
setup_command_line(command_line);
setup_nr_cpu_ids();
setup_per_cpu_areas();
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
boot_cpu_hotplug_init();
build_all_zonelists(NULL);
page_alloc_init();
pr_notice("Kernel command line: %s\n", boot_command_line);
/* parameters may set static keys */
jump_label_init();
parse_early_param();
after_dashes = parse_args("Booting kernel",
static_command_line, __start___param,
__stop___param - __start___param,
-1, -1, NULL, &unknown_bootoption);
if (!IS_ERR_OR_NULL(after_dashes))
parse_args("Setting init args", after_dashes, NULL, 0, -1, -1,
NULL, set_init_arg);
/*
* These use large bootmem allocations and must precede
* kmem_cache_init()
*/
setup_log_buf(0);
vfs_caches_init_early();
sort_main_extable();
trap_init();
mm_init();
ftrace_init();
/* trace_printk can be enabled here */
early_trace_init();
/*
* Set up the scheduler prior starting any interrupts (such as the
* timer interrupt). Full topology setup happens at smp_init()
* time - but meanwhile we still have a functioning scheduler.
*/
sched_init();
/*
* Disable preemption - early bootup scheduling is extremely
* fragile until we cpu_idle() for the first time.
*/
preempt_disable();
if (WARN(!irqs_disabled(),
"Interrupts were enabled *very* early, fixing it\n"))
local_irq_disable();
radix_tree_init();
/*
* Set up housekeeping before setting up workqueues to allow the unbound
* workqueue to take non-housekeeping into account.
*/
housekeeping_init();
/*
* Allow workqueue creation and work item queueing/cancelling
* early. Work item execution depends on kthreads and starts after
* workqueue_init().
*/
workqueue_init_early();
rcu_init();
/* Trace events are available after this */
trace_init();
if (initcall_debug)
initcall_debug_enable();
context_tracking_init();
/* init some links before init_ISA_irqs() */
early_irq_init();
init_IRQ();
tick_init();
rcu_init_nohz();
init_timers();
hrtimers_init();
softirq_init();
timekeeping_init();
time_init();
/*
* For best initial stack canary entropy, prepare it after:
* - setup_arch() for any UEFI RNG entropy and boot cmdline access
* - timekeeping_init() for ktime entropy used in random_init()
* - time_init() for making random_get_entropy() work on some platforms
* - random_init() to initialize the RNG from from early entropy sources
*/
random_init(command_line);
boot_init_stack_canary();
perf_event_init();
profile_init();
call_function_init();
WARN(!irqs_disabled(), "Interrupts were enabled early\n");
early_boot_irqs_disabled = false;
local_irq_enable();
kmem_cache_init_late();
/*
* HACK ALERT! This is early. We're enabling the console before
* we've done PCI setups etc, and console_init() must be aware of
* this. But we do want output early, in case something goes wrong.
*/
console_init();
if (panic_later)
panic("Too many boot %s vars at `%s'", panic_later,
panic_param);
lockdep_init();
/*
* Need to run this when irqs are enabled, because it wants
* to self-test [hard/soft]-irqs on/off lock inversion bugs
* too:
*/
locking_selftest();
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && !initrd_below_start_ok &&
page_to_pfn(virt_to_page((void *)initrd_start)) < min_low_pfn) {
pr_crit("initrd overwritten (0x%08lx < 0x%08lx) - disabling it.\n",
page_to_pfn(virt_to_page((void *)initrd_start)),
min_low_pfn);
initrd_start = 0;
}
#endif
kmemleak_init();
debug_objects_mem_init();
setup_per_cpu_pageset();
numa_policy_init();
acpi_early_init();
if (late_time_init)
late_time_init();
sched_clock_init();
calibrate_delay();
arch_cpu_finalize_init();
pid_idr_init();
anon_vma_init();
#ifdef CONFIG_X86
if (efi_enabled(EFI_RUNTIME_SERVICES))
efi_enter_virtual_mode();
#endif
thread_stack_cache_init();
cred_init();
fork_init();
proc_caches_init();
uts_ns_init();
buffer_init();
key_init();
security_init();
dbg_late_init();
vfs_caches_init();
pagecache_init();
signals_init();
seq_file_init();
proc_root_init();
nsfs_init();
cpuset_init();
cgroup_init();
taskstats_init_early();
delayacct_init();
acpi_subsystem_init();
arch_post_acpi_subsys_init();
sfi_init_late();
if (efi_enabled(EFI_RUNTIME_SERVICES)) {
efi_free_boot_services();
}
/* Do the rest non-__init'ed, we're now alive */
rest_init();
prevent_tail_call_optimization();
}static noinline void __ref rest_init(void)
{
struct task_struct *tsk;
int pid;
rcu_scheduler_starting();
/*
* We need to spawn init first so that it obtains pid 1, however
* the init task will end up wanting to create kthreads, which, if
* we schedule it before we create kthreadd, will OOPS.
*/
pid = kernel_thread(kernel_init, NULL, CLONE_FS);
/*
* Pin init on the boot CPU. Task migration is not properly working
* until sched_init_smp() has been run. It will set the allowed
* CPUs for init to the non isolated CPUs.
*/
rcu_read_lock();
tsk = find_task_by_pid_ns(pid, &init_pid_ns);
set_cpus_allowed_ptr(tsk, cpumask_of(smp_processor_id()));
rcu_read_unlock();
numa_default_policy();
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
rcu_read_lock();
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
rcu_read_unlock();
/*
* Enable might_sleep() and smp_processor_id() checks.
* They cannot be enabled earlier because with CONFIG_PREEMPT=y
* kernel_thread() would trigger might_sleep() splats. With
* CONFIG_PREEMPT_VOLUNTARY=y the init task might have scheduled
* already, but it's stuck on the kthreadd_done completion.
*/
system_state = SYSTEM_SCHEDULING;
complete(&kthreadd_done);
/*
* The boot idle thread must execute schedule()
* at least once to get things moving:
*/
schedule_preempt_disabled();
/* Call into cpu_idle with preempt disabled */
cpu_startup_entry(CPUHP_ONLINE);
}
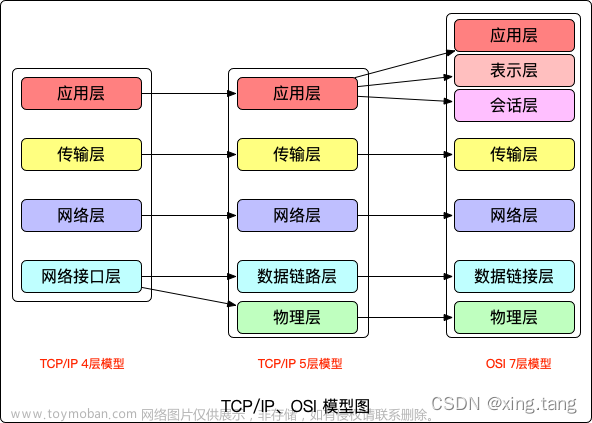
跟踪分析TCP/IP协议栈如何将自己与上层套接口与下层数据链路层关联起来的
TCP/IP协议栈通过套接字接口(Socket API)与上层应用程序进行交互,并通过网络设备驱动程序与下层的数据链路层进行通信。具体的关联过程如下:
上层套接口和协议栈的关联:应用程序通过套接字API(如socket、bind、listen等)与协议栈进行交互。协议栈提供了一组函数和数据结构,使应用程序能够发送和接收网络数据。
协议栈和传输层的关联:协议栈使用传输层协议(如TCP或UDP)将数据从应用层传递到网络层。协议栈会相应地解析和处理传输层的头部信息,并提供相应的函数和数据结构供传输层使用。
协议栈和网络层的关联:协议栈使用网络层协议(如IP)来封装数据,并确定数据包的路由。协议栈会解析和处理网络层的头部信息,并提供相应的函数和数据结构供网络层使用。
协议栈和数据链路层的关联:协议栈通过网络设备驱动程序与下层的数据链路层进行通信。数据链路层负责将数据帧从一个网络接口发送到另一个网络接口。协议栈会使用适当的数据链路层协议(如以太网)来封装数据,并提供相应的函数和数据结构供数据链路层使用。
通过这些关联,TCP/IP协议栈能够在不同层级之间传递和处理网络数据。
TCP的三次握手源代码跟踪分析,跟踪找出设置和发送SYN/ACK的位置,以及状态转换的位置
TCP的三次握手是指在建立TCP连接时,客户端和服务器端进行的一系列交互过程。具体来说,三次握手的过程如下:
1.客户端向服务器端发送SYN包,表示请求建立连接。
2.服务器端收到SYN包后,向客户端发送SYN/ACK包,表示确认建立连接。
3.客户端收到SYN/ACK包后,向服务器端发送ACK包,表示连接已经建立。
下面我们通过跟踪TCP协议栈的源代码,来分析三次握手的具体实现过程。
首先,在Linux系统中,TCP协议栈的相关代码位于net/ipv4/tcp_ipv4.c文件中。在该文件的tcp_v4_connect函数中,实现了TCP连接的建立过程。具体来说,当客户端调用connect函数向服务器端发起连接请求时,会调用tcp_v4_connect函数。在该函数中,会执行以下代码:
sk = tcp_v4_syn_recv_sock(net, saddr, daddr, dport, O_NONBLOCK, &err);
if (!sk)
goto out;
inet_sk(sk)->daddr = daddr;
inet_sk(sk)->dport = dport;
tcp_connect(sk);其中,tcp_v4_syn_recv_sock函数用于创建一个用于接收SYN/ACK包的套接字,tcp_connect函数用于执行三次握手过程。
接下来,我们来看一下tcp_connect函数的实现。在该函数中,会执行以下代码:
tcp_send_syn(sk, GFP_KERNEL);
tcp_write_wakeup(sk);
set_bit(TCPF_SYN_SENT, &sk->sk_tcp_state);
sk->sk_sndbuf = tcp_initial_cwnd(sk);其中,tcp_send_syn函数用于发送SYN包,并设置SYN包的相关信息,如序列号、窗口大小等;set_bit函数用于将TCP状态设置为SYN_SENT状态,表示已经发送了SYN包;tcp_initial_cwnd函数用于计算初始的拥塞窗口大小。
接下来,我们来看一下tcp_send_syn函数的实现。在该函数中,会执行以下代码:
tcp_init_nondata_skb(skb, sk);
tcp_syn_build_options(skb, sk);
tcp_set_skb_tso_segs(skb, 1);
tcp_transmit_skb(skb, sk, 1, GFP_ATOMIC);其中,tcp_init_nondata_skb函数用于初始化SKB,并设置TCP头部的一些基本信息,如源IP地址、目的IP地址、源端口号、目的端口号等;tcp_syn_build_options函数用于设置TCP协议选项,如MSS、SACK等;tcp_set_skb_tso_segs函数用于设置TCP分段的数量;tcp_transmit_skb函数用于将SKB发送出去。
当服务器端收到客户端发送的SYN包后,会向客户端发送SYN/ACK包。具体来说,在服务器端的tcp_v4_do_rcv函数中,会执行以下代码:
if (req != TCP_CONN_ESTABLISHED)
sk = tcp_check_req(sk, req, skb);
tcp_v4_send_synack(sk, skb, tcp_time_stamp(skb));其中,tcp_check_req函数用于检查连接请求,返回一个新的套接字;tcp_v4_send_synack函数用于发送SYN/ACK包,并设置SYN/ACK包的相关信息,如序列号、窗口大小等。
当客户端收到服务器端发送的SYN/ACK包后,会向服务器端发送ACK包,表示连接已经建立。具体来说,在客户端的tcp_v4_do_rcv函数中,会执行以下代码:
if (th->syn && th->ack) {
if (sk->sk_state == TCP_SYN_SENT) {
inet_sk(sk)->inet_dport = th->source;
tcp_finish_connect(sk, skb);
} else
goto discard;
} else
goto discard;其中,tcp_finish_connect函数用于完成TCP连接建立过程,并将TCP状态设置为ESTABLISHED状态,表示连接已经建立成功。
综上所述,三次握手过程中,客户端发送SYN包的位置在tcp_send_syn函数中,服务器端发送SYN/ACK包的位置在tcp_v4_send_synack函数中,客户端发送ACK包的位置在tcp_finish_connect函数中。同时,TCP状态的转换也可以通过在代码中设置标志位来实现,如在客户端发送SYN包时,需要将TCP状态设置为SYN_SENT状态。
send在TCP/IP协议栈中的执行路径
send操作涉及应用程序调用套接字接口发送数据,并通过协议栈将数据传递到网络层。
用户空间调用send函数;
send函数通过系统调用进入内核空间,调用sock_sendmsg函数;
sock_sendmsg函数中会调用sock_sendmsg_nosec函数进行实际的发送操作;
sock_sendmsg_nosec函数首先会调用sock_sendmsg_check_size函数判断发送的数据是否超出了网络拥塞窗口大小和socket缓冲区大小的限制;
如果发送数据量过大,sock_sendmsg_check_size函数会返回一个错误码,否则继续执行;
sock_sendmsg_nosec函数会调用inet_sendmsg函数对待发送数据进行封装(添加TCP头部、IP头部等),并将数据送到tcp_sendmsg函数中;
tcp_sendmsg函数中会判断当前TCP连接的状态,如果处于CLOSED或LISTEN状态,则返回错误码;
如果处于SYN_SENT状态,表示正在进行三次握手,此时发送的数据会被放到SYN包里一起发送;
如果处于SYN_RECEIVED、ESTABLISHED或CLOSE_WAIT状态,则可以正常发送数据;
tcp_sendmsg函数中会调用tcp_transmit_skb函数将封装好的数据包交给网络设备发送;
网络设备将数据包发送出去后,会触发中断处理程序,中断处理程序会调用tcp_ack函数对发送的数据包进行确认。
recv在TCP/IP协议栈中的执行路径
recv操作涉及从网络接收数据,并通过协议栈将数据传递给应用程序。
用户空间调用recv函数;
recv函数通过系统调用进入内核空间,调用sock_recvmsg函数;
sock_recvmsg函数会调用sock_recvmsg_nosec函数进行实际的接收操作;
sock_recvmsg_nosec函数首先会调用skb_recv_datagram函数从接收缓冲区中获取一个数据报(包);
如果接收缓冲区为空,则进入等待状态,等待数据到达或超时;
当有数据到达时,sock_recvmsg_nosec函数会继续执行,调用skb_copy_datagram_msg函数将数据从内核空间复制到用户空间;
复制完成后,sock_recvmsg_nosec函数返回接收到的数据的长度给recv函数;
recv函数返回接收到的数据给用户程序。
路由表的结构和初始化过程
Linux内核的路由表使用一些数据结构来表示每个路由项。这些结构定义在include/net/route.h和net/ipv4/route.c中。
struct rtable {
struct dst_entry dst;
int rt_genid;
unsigned int rt_flags;
__u16 rt_type;
__u8 rt_is_input;
__u8 rt_uses_gateway;
int rt_iif;
/* Info on neighbour */
__be32 rt_gateway;
/* Miscellaneous cached information */
u32 rt_mtu_locked:1,
rt_pmtu:31;
struct list_head rt_uncached;
struct uncached_list *rt_uncached_list;
};初始化过程如下:
初始化路由缓存:在内核启动时,会创建一个全局的路由缓存(route cache)。路由缓存用于加速查找过程,避免每次都需要进行完整的路由表查找。路由缓存的初始化通过调用ip_rt_init()函数完成。
注册路由协议:内核支持多种路由协议,如IPv4的RIP、OSPF、BGP等。在初始化过程中,通过调用register_pernet_device()函数注册路由协议。
添加路由项:用户可以通过命令行工具(如ip route add)或系统调用(如rtnetlink)来添加路由项。添加路由项时,会调用ip_rt_insert()函数,该函数会调用fib_table_lookup()函数查找目标路由项,并将其插入到路由表中。
路由查找:当内核需要发送数据包时,需要根据目标IP地址查找对应的路由项。路由查找通过调用ip_route_output_slow()函数完成,该函数会依次查找本地路由表、主机路由表、默认路由表等,直到找到匹配的路由项。
路由更新:当网络拓扑发生变化时,内核需要更新路由表。路由更新通过调用fib_table_lookup()函数和fib_table_update()函数完成。fib_table_lookup()函数用于查找目标路由项,fib_table_update()函数用于更新路由项的下一跳信息。
通过目的IP查询路由表的到下一跳的IP地址的过程
通过目的IP地址查询路由表的到下一跳IP地址的过程主要涉及以下几个步骤:
调用ip_route_output_slow()函数:这是一个路由查找的慢路径函数,用于查找目标IP地址对应的路由项。该函数定义在net/ipv4/route.c文件中。
调用fib_lookup函数执行路由查找操作。
fib_lookup函数内部会调用fib_table_lookup函数来执行实际的路由表查找操作。fib_table_lookup函数位于net/ipv4/fib_semantics.c文件中
在fib_table_lookup函数中,它将根据flowi4结构体中的信息从路由表中查找匹配的路由项。关键的查找逻辑包括以下步骤:
根据flp->daddr和flp->flowi4_scope选择要查询的路由表。
使用fib_lookup_1函数从选定的路由表中查找匹配的路由项。fib_lookup_1函数会逐级查找路由表,并根据目的IP地址和掩码进行匹配。
如果找到匹配的路由项,将相关信息填充到res结构体中,包括下一跳IP地址和出接口。
返回查找结果。
static int ip_route_input_slow(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev,
struct fib_result *res)
{
struct in_device *in_dev = __in_dev_get_rcu(dev);
struct flow_keys *flkeys = NULL, _flkeys;
struct net *net = dev_net(dev);
struct ip_tunnel_info *tun_info;
int err = -EINVAL;
unsigned int flags = 0;
u32 itag = 0;
struct rtable *rth;
struct flowi4 fl4;
bool do_cache = true;
/* IP on this device is disabled. */
if (!in_dev)
goto out;
/* Check for the most weird martians, which can be not detected
by fib_lookup.
*/
tun_info = skb_tunnel_info(skb);
if (tun_info && !(tun_info->mode & IP_TUNNEL_INFO_TX))
fl4.flowi4_tun_key.tun_id = tun_info->key.tun_id;
else
fl4.flowi4_tun_key.tun_id = 0;
skb_dst_drop(skb);
if (ipv4_is_multicast(saddr) || ipv4_is_lbcast(saddr))
goto martian_source;
res->fi = NULL;
res->table = NULL;
if (ipv4_is_lbcast(daddr) || (saddr == 0 && daddr == 0))
goto brd_input;
/* Accept zero addresses only to limited broadcast;
* I even do not know to fix it or not. Waiting for complains :-)
*/
if (ipv4_is_zeronet(saddr))
goto martian_source;
if (ipv4_is_zeronet(daddr))
goto martian_destination;
/* Following code try to avoid calling IN_DEV_NET_ROUTE_LOCALNET(),
* and call it once if daddr or/and saddr are loopback addresses
*/
if (ipv4_is_loopback(daddr)) {
if (!IN_DEV_NET_ROUTE_LOCALNET(in_dev, net))
goto martian_destination;
} else if (ipv4_is_loopback(saddr)) {
if (!IN_DEV_NET_ROUTE_LOCALNET(in_dev, net))
goto martian_source;
}
/*
* Now we are ready to route packet.
*/
fl4.flowi4_oif = 0;
fl4.flowi4_iif = dev->ifindex;
fl4.flowi4_mark = skb->mark;
fl4.flowi4_tos = tos;
fl4.flowi4_scope = RT_SCOPE_UNIVERSE;
fl4.flowi4_flags = 0;
fl4.daddr = daddr;
fl4.saddr = saddr;
fl4.flowi4_uid = sock_net_uid(net, NULL);
if (fib4_rules_early_flow_dissect(net, skb, &fl4, &_flkeys)) {
flkeys = &_flkeys;
} else {
fl4.flowi4_proto = 0;
fl4.fl4_sport = 0;
fl4.fl4_dport = 0;
}
err = fib_lookup(net, &fl4, res, 0);
if (err != 0) {
if (!IN_DEV_FORWARD(in_dev))
err = -EHOSTUNREACH;
goto no_route;
}
if (res->type == RTN_BROADCAST) {
if (IN_DEV_BFORWARD(in_dev))
goto make_route;
/* not do cache if bc_forwarding is enabled */
if (IPV4_DEVCONF_ALL(net, BC_FORWARDING))
do_cache = false;
goto brd_input;
}
if (res->type == RTN_LOCAL) {
err = fib_validate_source(skb, saddr, daddr, tos,
0, dev, in_dev, &itag);
if (err < 0)
goto martian_source;
goto local_input;
}
if (!IN_DEV_FORWARD(in_dev)) {
err = -EHOSTUNREACH;
goto no_route;
}
if (res->type != RTN_UNICAST)
goto martian_destination;
make_route:
err = ip_mkroute_input(skb, res, in_dev, daddr, saddr, tos, flkeys);
out: return err;
brd_input:
if (skb->protocol != htons(ETH_P_IP))
goto e_inval;
if (!ipv4_is_zeronet(saddr)) {
err = fib_validate_source(skb, saddr, 0, tos, 0, dev,
in_dev, &itag);
if (err < 0)
goto martian_source;
}
flags |= RTCF_BROADCAST;
res->type = RTN_BROADCAST;
RT_CACHE_STAT_INC(in_brd);
local_input:
do_cache &= res->fi && !itag;
if (do_cache) {
rth = rcu_dereference(FIB_RES_NH(*res).nh_rth_input);
if (rt_cache_valid(rth)) {
skb_dst_set_noref(skb, &rth->dst);
err = 0;
goto out;
}
}
rth = rt_dst_alloc(l3mdev_master_dev_rcu(dev) ? : net->loopback_dev,
flags | RTCF_LOCAL, res->type,
IN_DEV_CONF_GET(in_dev, NOPOLICY), false, do_cache);
if (!rth)
goto e_nobufs;
rth->dst.output= ip_rt_bug;
#ifdef CONFIG_IP_ROUTE_CLASSID
rth->dst.tclassid = itag;
#endif
rth->rt_is_input = 1;
RT_CACHE_STAT_INC(in_slow_tot);
if (res->type == RTN_UNREACHABLE) {
rth->dst.input= ip_error;
rth->dst.error= -err;
rth->rt_flags &= ~RTCF_LOCAL;
}
if (do_cache) {
struct fib_nh *nh = &FIB_RES_NH(*res);
rth->dst.lwtstate = lwtstate_get(nh->nh_lwtstate);
if (lwtunnel_input_redirect(rth->dst.lwtstate)) {
WARN_ON(rth->dst.input == lwtunnel_input);
rth->dst.lwtstate->orig_input = rth->dst.input;
rth->dst.input = lwtunnel_input;
}
if (unlikely(!rt_cache_route(nh, rth)))
rt_add_uncached_list(rth);
}
skb_dst_set(skb, &rth->dst);
err = 0;
goto out;
no_route:
RT_CACHE_STAT_INC(in_no_route);
res->type = RTN_UNREACHABLE;
res->fi = NULL;
res->table = NULL;
goto local_input;
/*
* Do not cache martian addresses: they should be logged (RFC1812)
*/
martian_destination:
RT_CACHE_STAT_INC(in_martian_dst);
#ifdef CONFIG_IP_ROUTE_VERBOSE
if (IN_DEV_LOG_MARTIANS(in_dev))
net_warn_ratelimited("martian destination %pI4 from %pI4, dev %s\n",
&daddr, &saddr, dev->name);
#endif
e_inval:
err = -EINVAL;
goto out;
e_nobufs:
err = -ENOBUFS;
goto out;
martian_source:
ip_handle_martian_source(dev, in_dev, skb, daddr, saddr);
goto out;
}static void nl_fib_lookup(struct net *net, struct fib_result_nl *frn)
{
struct fib_result res;
struct flowi4 fl4 = {
.flowi4_mark = frn->fl_mark,
.daddr = frn->fl_addr,
.flowi4_tos = frn->fl_tos,
.flowi4_scope = frn->fl_scope,
};
struct fib_table *tb;
rcu_read_lock();
tb = fib_get_table(net, frn->tb_id_in);
frn->err = -ENOENT;
if (tb) {
local_bh_disable();
frn->tb_id = tb->tb_id;
frn->err = fib_table_lookup(tb, &fl4, &res, FIB_LOOKUP_NOREF);
if (!frn->err) {
frn->prefixlen = res.prefixlen;
frn->nh_sel = res.nh_sel;
frn->type = res.type;
frn->scope = res.scope;
}
local_bh_enable();
}
rcu_read_unlock();
}ARP缓存的数据结构及初始化过程,包括ARP缓存的初始化
ARP(Address Resolution Protocol)缓存是用于存储IP地址与MAC地址之间映射关系的数据结构。在Linux内核中,ARP缓存使用struct neighbour结构来表示。
初始化ARP缓存的过程通常在设备初始化的时候完成。以以太网设备为例,以下是ARP缓存的初始化过程:
在以太网设备的初始化函数中,调用neigh_table_init函数来初始化邻居表。neigh_table_init函数位于net/core/neighbour.c文件中,用于初始化邻居表。它会创建用于存储邻居项的哈希表和相关的数据结构。
在设备初始化过程中,通过调用neigh_create函数创建ARP缓存项。neigh_create函数位于net/core/neighbour.c文件中,用于创建一个新的ARP缓存项。该函数会为缓存项分配内存,并对缓存项的字段进行初始化。
初始化ARP缓存项的各个字段,例如设置dev指针指向所属的网络设备、设置硬件层地址缓存等。
通过调用neigh_add函数将ARP缓存项添加到邻居表中。neigh_add函数位于net/core/neighbour.c文件中,用于将ARP缓存项添加到邻居表中并建立映射关系。
当需要使用ARP缓存项时,可以通过调用neigh_lookup函数来查找缓存项。neigh_lookup函数位于net/core/neighbour.c文件中,用于根据目标IP地址查找对应的ARP缓存项。
通过以上步骤,ARP缓存项的初始化和添加到邻居表的过程完成了。在使用ARP缓存时,可以根据目标IP地址查找对应的缓存项,从而获取相应的MAC地址。
struct neighbour {
struct neighbour __rcu *next;
struct neigh_table *tbl;
struct neigh_parms *parms;
unsigned long confirmed;
unsigned long updated;
rwlock_t lock;
refcount_t refcnt;
struct sk_buff_head arp_queue;
unsigned int arp_queue_len_bytes;
struct timer_list timer;
unsigned long used;
atomic_t probes;
__u8 flags;
__u8 nud_state;
__u8 type;
__u8 dead;
seqlock_t ha_lock;
unsigned char ha[ALIGN(MAX_ADDR_LEN, sizeof(unsigned long))];
struct hh_cache hh;
int (*output)(struct neighbour *, struct sk_buff *);
const struct neigh_ops *ops;
struct rcu_head rcu;
struct net_device *dev;
u8 primary_key[0];
} __randomize_layout;void neigh_table_init(int index, struct neigh_table *tbl)
{
unsigned long now = jiffies;
unsigned long phsize;
INIT_LIST_HEAD(&tbl->parms_list);
list_add(&tbl->parms.list, &tbl->parms_list);
write_pnet(&tbl->parms.net, &init_net);
refcount_set(&tbl->parms.refcnt, 1);
tbl->parms.reachable_time =
neigh_rand_reach_time(NEIGH_VAR(&tbl->parms, BASE_REACHABLE_TIME));
tbl->stats = alloc_percpu(struct neigh_statistics);
if (!tbl->stats)
panic("cannot create neighbour cache statistics");
#ifdef CONFIG_PROC_FS
if (!proc_create_seq_data(tbl->id, 0, init_net.proc_net_stat,
&neigh_stat_seq_ops, tbl))
panic("cannot create neighbour proc dir entry");
#endif
RCU_INIT_POINTER(tbl->nht, neigh_hash_alloc(3));
phsize = (PNEIGH_HASHMASK + 1) * sizeof(struct pneigh_entry *);
tbl->phash_buckets = kzalloc(phsize, GFP_KERNEL);
if (!tbl->nht || !tbl->phash_buckets)
panic("cannot allocate neighbour cache hashes");
if (!tbl->entry_size)
tbl->entry_size = ALIGN(offsetof(struct neighbour, primary_key) +
tbl->key_len, NEIGH_PRIV_ALIGN);
else
WARN_ON(tbl->entry_size % NEIGH_PRIV_ALIGN);
rwlock_init(&tbl->lock);
INIT_DEFERRABLE_WORK(&tbl->gc_work, neigh_periodic_work);
queue_delayed_work(system_power_efficient_wq, &tbl->gc_work,
tbl->parms.reachable_time);
timer_setup(&tbl->proxy_timer, neigh_proxy_process, 0);
skb_queue_head_init_class(&tbl->proxy_queue,
&neigh_table_proxy_queue_class);
tbl->last_flush = now;
tbl->last_rand = now + tbl->parms.reachable_time * 20;
neigh_tables[index] = tbl;
}如何将IP地址解析出对应的MAC地址
在Linux内核中,IP地址解析出对应的MAC地址是通过ARP(Address Resolution Protocol)实现的。ARP是一种广泛用于解析IP地址到对应MAC地址的协议。
内核中与ARP相关的代码位于net/ipv4/arp.c文件中。可以在这个文件中找到处理ARP请求和响应的函数。
当发送ARP请求时,调用arp_send()函数,该函数会构造一个ARP请求包并通过网络设备发送出去。
当接收到ARP请求或ARP响应时,会调用arp_rcv()函数进行处理。该函数会解析接收到的ARP包,更新ARP缓存表。
ARP缓存表的数据结构定义在include/net/arp.h文件中,主要包括IP地址、MAC地址、更新时间等字段。
当需要获取目标IP地址对应的MAC地址时,会调用arp_find()函数,在ARP缓存表中查找匹配的条目。如果找到则返回对应的MAC地址,否则返回NULL。
如果ARP缓存表中没有匹配的条目,则需要发送ARP请求进行解析。
通过这个过程,系统能够根据目的IP地址解析出对应的MAC地址。
void arp_send(int type, int ptype, __be32 dest_ip,
struct net_device *dev, __be32 src_ip,
const unsigned char *dest_hw, const unsigned char *src_hw,
const unsigned char *target_hw)
{
arp_send_dst(type, ptype, dest_ip, dev, src_ip, dest_hw, src_hw,
target_hw, NULL);
}static int arp_rcv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *pt, struct net_device *orig_dev)
{
const struct arphdr *arp;
/* do not tweak dropwatch on an ARP we will ignore */
if (dev->flags & IFF_NOARP ||
skb->pkt_type == PACKET_OTHERHOST ||
skb->pkt_type == PACKET_LOOPBACK)
goto consumeskb;
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb)
goto out_of_mem;
/* ARP header, plus 2 device addresses, plus 2 IP addresses. */
if (!pskb_may_pull(skb, arp_hdr_len(dev)))
goto freeskb;
arp = arp_hdr(skb);
if (arp->ar_hln != dev->addr_len || arp->ar_pln != 4)
goto freeskb;
memset(NEIGH_CB(skb), 0, sizeof(struct neighbour_cb));
return NF_HOOK(NFPROTO_ARP, NF_ARP_IN,
dev_net(dev), NULL, skb, dev, NULL,
arp_process);
consumeskb:
consume_skb(skb);
return NET_RX_SUCCESS;
freeskb:
kfree_skb(skb);
out_of_mem:
return NET_RX_DROP;
}跟踪TCP send过程中的路由查询和ARP解析的最底层实现
在Linux内核中,TCP send过程中的路由查询和ARP解析是通过网络协议栈中的不同模块实现的。具体来说,路由查询是在IP层实现的,而ARP解析是在数据链路层实现的。
路由查询:
在TCP send过程中,当应用程序调用send函数发送数据时,数据首先被传递到TCP层。TCP层会将数据封装成TCP报文段,并添加TCP报头信息。然后,TCP层将TCP报文段传递给IP层。IP层会根据目标IP地址查找路由表,以确定数据报文段应该通过哪个网络接口发送。
在Linux内核中,路由查询是通过ip_route_output函数实现的。该函数位于net/ipv4/route.c文件中,其定义如下:
struct rtable *ip_route_output(struct net *net, struct flowi4 *fl4,
const struct sock *sk, int flags);其中,net参数是指向网络命名空间的指针,fl4参数是指向IPv4流量标识符(flow identifier)的指针,sk参数是指向套接字的指针,flags参数是控制路由查询行为的标志。该函数会根据目标IP地址和流量标识符查找路由表,并返回一个指向路由表项的指针。如果没有找到合适的路由表项,则返回NULL。
在ip_route_output函数中,路由表的查找是通过调用fib_lookup函数实现的。fib_lookup函数位于net/ipv4/fib_frontend.c文件中,其定义如下:
struct fib_result *fib_lookup(struct net *net, const struct flowi *flp,
int flags);其中,net参数是指向网络命名空间的指针,flp参数是指向流量标识符的指针,flags参数是控制路由查询行为的标志。该函数会根据流量标识符查找路由表,并返回一个指向路由表项的指针。
ARP解析:
在TCP send过程中,当IP层确定了数据报文段应该通过哪个网络接口发送后,数据报文段会被传递到数据链路层。数据链路层会将数据报文段封装成以太网数据帧,并添加以太网帧头信息。然后,数据链路层将以太网数据帧发送到网络接口上。
在发送以太网数据帧之前,需要将目标主机的MAC地址解析出来。如果ARP缓存中已经有了目标主机的MAC地址,则可以直接使用该地址。否则,需要先发送ARP请求,获取目标主机的MAC地址。在Linux内核中,ARP解析是通过neigh_resolve_output函数实现的。该函数会等待收到ARP响应,并在收到响应后更新邻居项中的MAC地址。
neigh_resolve_output函数位于net/core/neighbour.c文件中,其定义如下:
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb);其中,neigh参数是指向邻居项的指针,skb参数是指向要发送的数据包的指针。该函数会等待ARP响应,并在收到响应后更新邻居项中的MAC地址。如果成功获取到MAC地址,则返回0;否则返回负数。
在neigh_resolve_output函数中,ARP请求的创建和发送是通过arp_create函数和dev_queue_xmit函数实现的。具体来说,arp_create函数用于创建一个新的ARP请求,而dev_queue_xmit函数用于将ARP请求发送到网络接口上。文章来源:https://www.toymoban.com/news/detail-822722.html
综上所述,TCP send过程中的路由查询和ARP解析是在Linux内核的IP层和数据链路层中实现的。路由查询是通过ip_route_output函数和fib_lookup函数实现的,而ARP解析是通过neigh_resolve_output函数、arp_create函数和dev_queue_xmit函数实现的。文章来源地址https://www.toymoban.com/news/detail-822722.html
到了这里,关于Linux内核TCP/IP协议栈的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!