本节已经涉及Rust学习曲线上的一个大坑:泛型和特性了,属于语言的深水区,如果初学者,建议看一眼知道有这个功能即可。
如果我们立足于功能实现,那么做到像上一节那样就可以了,从原理上来说,每个函数满足唯一的功能,是一种好的设计,软件工程里面“高内聚低耦合”是有利于系统的独立性的。
但是在调用的时候,就需要有一点的心智了,例如我们要读取点线面三种不同的shapefile,就要记住三种不同的函数名和三种不同的绘图要素构建程序,那也太麻烦了,有没有一种方法,让我们调用一种方法,根据不同的参数类型自动适配不同的处理逻辑呢?
如果你是学Python/Java/JavaScript这样的高级语言的同学,你肯定已经有了自己的实现方法,例如Python/Javascript作为动态类型的语言,可以只写一个入口函数,然后根据函数的输入参数自动去选择不同的分支来处理。
而Java也有同名方法覆盖,利用不同的函数签名(参数类型)来解决用同名函数实现不同的逻辑流程。
而C++则是可以用泛型和函数重载来实现这个功能。
那么在Rust里面如何解决呢?
- 首先,Rust不支持函数签名的类型推断。所有函数签名的类型必须写清楚,这就杜绝了我们用动态类型的语言那样根据输入的参数来匹配。
- 第二,Rust也不(直接)支持函数重载,为什么是不直接支持呢,因为可以通过泛型和特性来实现函数重载,也就是我们今天要做的内容。
老规矩,先看结果:
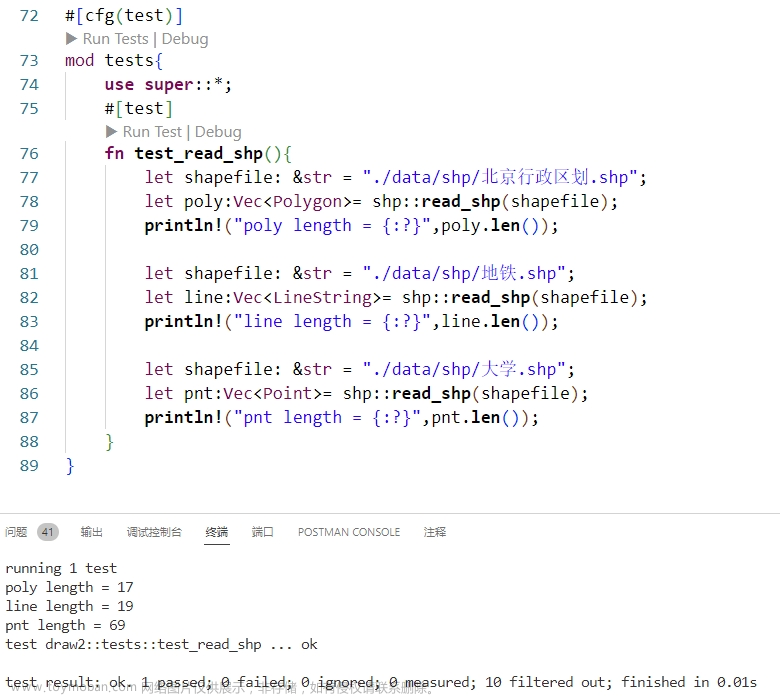
用同名的一个方法,实现对于三种不同的shapefile读取,并且获取三种不同的返回类型值,那么这是这么实现的呢?
先看代码:
架构定义
- 首先定义了一个结构体,这个空结构体的作用类似于Java里面的class。
- 然后定义了一个特性(trait),特性这个东西,在Rust中,类似于Java里面的接口,或者C++里面的虚函数,但是与接口和虚函数不同的时候,特性可以直接在里面写实现,也可以留空,如果你是学Java的,你把下面的代码理解为定义了一个接口,并且定义了一个实现接口的工厂方法即可。
- 在这里的特性中,我们定义一个泛型T,然后定义了一个方法,就叫做read_shp,输入产生就是一个shapefile的路径,返回值是一个
T,这个T就是Rust中的泛型,即代表一切可能的类型。- 如果是没有接触过泛型的同学,可能会问,他既然代表一切类型,那么你不是说了Rust是类型严格的语言么?那系统编译器怎么知道,这个T到底是哪种类型呢?继续往下看
pub struct shp;
pub trait ReadShapfile<T> {
fn read_shp(shp_path:&str) -> T;
}
然后我们开始写针对不同类型的shapefile的实现,实现如下:
//实现1:读取polygon类型的shapefile,通过返回值来匹配。
impl ReadShapfile<Vec<Polygon>> for shp{
fn read_shp(shp_path:&str) -> Vec<Polygon>{
let shp_read = shapefile::read_as::<_,
shapefile::Polygon, shapefile::dbase::Record>(shp_path)
.expect(&format!("Could not open polygon-shapefile, error: {}", shp_path));
let mut polygons:Vec<Polygon> = Vec::new();
for (polygon, polygon_record) in shp_read {
let geo_mpolygon: geo_types::MultiPolygon<f64> = polygon.into();
for poly in geo_mpolygon.iter(){
polygons.push(poly.to_owned());
}
}
polygons
}
}
//实现2:读取Polyline类型的shapefile,通过返回值来匹配。
impl ReadShapfile<Vec<LineString>> for shp{
fn read_shp(shp_path:&str) -> Vec<LineString>{
let shp_read = shapefile::read_as::<_,
shapefile::Polyline, shapefile::dbase::Record>(shp_path)
.expect(&format!("Could not open polyline-shapefile, error: {}", shp_path));
let mut linestrings:Vec<LineString> = Vec::new();
for (pline, pline_record) in shp_read {
let geo_mline: geo_types::MultiLineString<f64> = pline.into();
for line in geo_mline.iter(){
linestrings.push(line.to_owned());
}
}
linestrings
}
}
//实现2:读取Point类型的shapefile,通过返回值来匹配。
impl ReadShapfile<Vec<Point>> for shp{
fn read_shp(shp_path:&str) -> Vec<Point>{
let shp_read = shapefile::read_as::<_,
shapefile::Point, shapefile::dbase::Record>(shp_path)
.expect(&format!("Could not open polyline-shapefile, error: {}", shp_path));
let mut pnts:Vec<Point> = Vec::new();
for (pnt, pnt_record) in shp_read {
let geo_pnt: geo_types::Point<f64> = pnt.into();
pnts.push(geo_pnt.to_owned());
}
pnts
}
}
简要的解释一下:
-
在Rust的语法中,impl
特性名称<返回值> for结构名这个语法,代表了具体的实现,而里面那个 <返回值> 部分,就是我们定义的泛型T,注意,T只是一个代称,习惯性用大写字母,你用ABCDEFG,或者abcdefg都是可以的。 -
然后在这个实现里面,去写具体方法的read_shp的实现,写完之后,就可以通过在调用的时候,再指定返回类型,来适配具体调用哪个方法了。
看到这里,可能有同学又有问题了:
上一节,直接写多个方法,多实用啊,读polygon就是polygon方法,读point就是point方法,干净整洁又高效,干嘛搞这么麻烦?

实际上两种方式,都是可以的,每个方法用独立名称进行调用,实际上是一种比较传统,但是很高效的方式(C语言里面写操作系统内核都是这样写的)。
而后面这种,则是现代编程架构里面推荐的,用同名函数,来减少调用者的心智负担,反正都是读取shapefile,我干嘛还要记那么多个函数名啊?为什么不能用一个函数就全部解决了呢?

所以在软件开发中,同名函数,通过定义不同的返回值,或者输入值来区分的方式,叫做多态,而在Rust里面,多态又可以分为静态分发:即静态多态模式或者单一态模式;以及动态分发:即动态多态模式。
这种所谓的静态和动态,在Rust中,是针对编译而言的,静态即代码和方法,在被编译的时候,就已经决定了编译的结果,你的输入、输出、处理流程等,都在编译的时候被固定下来了。
这种也是函数式编程的核心思想:函数式编程强调:不可变性和纯函数,这意味着函数的输出只取决于它的输入,而不依赖于外部状态
而动态则相反,在编译的时候,系统并不知道要输入的参数和输出的结果具体是什么类型,只有在运行的时候,根据输入的数据情况才知道。
一般来说,动态语言中的动,就是这种,通常解释性的语言,都是动态的,例如Python/Javascript等。
当然,Rust也是支持动态编译的,但是在使用动态编译的时候,需要有一系列的手续,这个我们以后再说。
从两种编译模式来看,静态模式的开销小,安全性高,但是灵活性比较差;反之,动态模式灵活性好,但是开销大,安全性和稳定性较差。
具体在开发过程中,用哪种模式,就仁者见仁智者见智了。
最后我们来画一个UML图,就很容易看出来这个架构的实现思路了:文章来源:https://www.toymoban.com/news/detail-823062.html
 文章来源地址https://www.toymoban.com/news/detail-823062.html
文章来源地址https://www.toymoban.com/news/detail-823062.html
到了这里,关于用可视化案例讲Rust编程4. 用泛型和特性实现自适配shapefile的读取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!