1. 数据表示和公开数据库
1.1 数据表示
(1)基本的数据形式
- ADC(数模转换)数据块:由Chirp采样N、每帧内Chirp个数M和天线K组成的三维数据块的中频信号
- Range-Azimuth-Doppler数据块:将中频信号数据块分别在距离、速度、角度三个维度上进行FFT操作,得到距离-角度-速度表征的RAD数据块。其中,角度是指水平方向的旋转角度
- 稀疏点云:对RAD稠密数据块通过CFAR操作得到稀疏点云,点云中的每个点表示距离、速度、角度三个值

(2)折中的表示形式
-
执行两个维度的FFT
- Range-Azimuth-Chirp:保留Doppler维度,对中频数据块执行Range和Azimuth两个维度的FFT,得到Range-Azimuth-Chirp数据块。后面可采样深度神经网络的方法来处理Doppler维度,以得到速度信息。
- Range-Antenna-Doppler:保留Azimuth维度,对中频数据块执行Range和Doppler两个维度的FFT,得到Range-Antenna-Doppler数据块。
-
降低CFAR阈值,保留更多的点(比如5k - 10k),在数据量与信息量之间取得折中。
1.2 公开数据库
(1)单模态数据库
- 只包含毫米波雷达数据,相对来说应用范围较窄,只能进行毫米波雷达感知算法的研究
- 很难进行准确有效的标注
(2)多模态数据库
- 除了毫米波雷达数据外,还包括同步的图像和激光雷达数据,这样可通过这些辅助数据来进行标注,然后将标注信息转换到毫米波雷达坐标系下,这样就间接完成了对毫米波雷达的标注。
- 毫米波雷达数据:底层数据块或点云数据
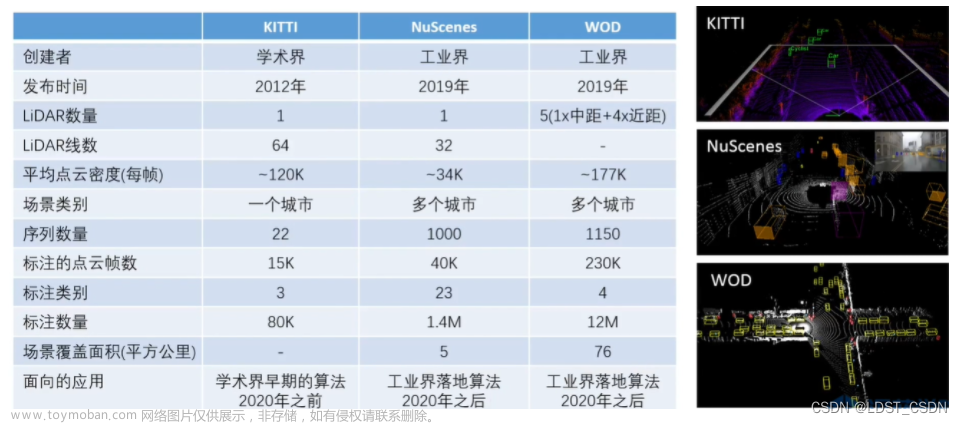
- NuScenes、CARRADA、SCORP、CRUW、SeeingThroughFog
(3)NuScenes
- 第一个公开发表的包含雷达数据的多模态数据库
- 140万帧图像数据(6个Camera,12Hz)
- 40万帧激光雷达数据(1个LiDAR,20Hz)
- 130万帧毫米波雷达数据(5个Radar,13Hz)
- 毫米波雷达参数:采样5个FMCW 77GHz的毫米波雷达,最大探测距离为250米,速度分辨率为0.03米/秒,它只包含稀疏的点云数据

(4)CARRADA
- 2020年由法国研究者发布
- 可认为是(非严格意义上)同步的图像和雷达数据(每种传感器一个)
-
- 30个序列,12666帧(约20分钟)
- 标注类别:汽车、行人、骑车的人
- 采集场景:封闭道路
- 数据格式:底层的RAD数据块
- 数据的具体信息:

(5)SCORP
- 2020年由加拿大、法国和德国的研究人员联合发布
- 可认为是(非严格意义上)同步的图像和雷达数据(每种传感器一个)
- 它是第一个包含数模转换(ADC)数据(比RAD更底层)的公开数据块
- 三种数据表示
-
- Sample-Chirp-Antenna数据块(ADC数据块)
- Range-Azimuth-Doppler数据块(RAD数据块)
- 点云(稀疏)
- 11个序列,3913帧(相对较小)
- 只有语义分割标注,没有目标级的标注

- 数据库的具体信息

(6)CRUW
- 2020年由华盛顿大学的研究人员发布
- 可认为是(非严格意义上)同步的图像和雷达数据(每种传感器两个)
- 相对大规模的,包含真实场景的数据库
- 包含物体级别的标注(物体框和分割mask)
- 数据格式:Range-Azimuth-Chirp数据块(保留速度维度,不对Doppler进行FFT,便于后期采样神经网络提取速度特征)
- 数据库的具体信息

(7)SeeingThroughFog
- 同步的可见光相机,热传感相机,激光雷达,毫米波雷达
- 毫米波雷达数据:稀疏点云
- 10000公理来自北欧的数据,包含超过10万个物体标注
- 包括了恶劣的天气环境,比如五天、雪天和雨天
- 验证在恶劣天气环境下,多传感器融合带来的性能提升
(8)未来发展方向
-
多模态数据:包括同步的图像、激光雷达、毫米波雷达等数据,用来进行多传感器融合的研究
-
多数据类型:包括ADC数据、RAD数据、点云数据等,以对比不同数据类型对算法带来的性能提升,为不同层次的算法研究和实际应用提供支持
-
360度视场:需要多个雷达配合完成,以满足多种自动驾驶应用的需求
-
大规模数据:对于自动驾驶来说,一般需要超过10万帧不同场景、不同天气条件下采集的数据
-
丰富的标注信息
-
- 物体级别:类别、位置、大小、方向、分割的mask
- 场景级别:语义信息,比如free space,occupied space等
2. 稀疏点云+深度学习
(1)毫米波雷达点云与激光雷达点云的区别
- 毫米波雷达点云比较稀疏,每帧只有上百个点;激光雷达点云较为稠密,每帧可达上万个点
- 激光雷达点云中的点有x, y, z三维空间坐标,而毫米波雷达在高度方向的感知能力较弱,因此通常所说的毫米波雷达点云只有x, y二维平面坐标
(2)稀疏毫米波雷达点云 + 深度学习的处理思路
- 直接处理点云
- 聚类得到目标物体的候选
- 深度神经网络进行特征提取和分类
- 点云转换为俯视图网格
- 点云量化为2D的网格结构
- 深度神经网络完成物体检测
(3)直接处理点云——候选生成 + 特征提取 + 候选分类(Deep Learning)
-
论文:Schumann, et al., Comparison of random forest and long short-term memory network performances in classification tasks using radar, 2017. From Daimler
-
通过点云聚类方法(DBSCAN)得到目标物体的候选
-
对每个聚类提取手工设计的特征,如位置、速度、反射强度等的统计值,共34维
-
对每个聚类进行分类
-
- 6个类别:轿车、公交车、自行车、行人、一组行人、垃圾桶
- 分类器:Random Forest vs LSTM
- LSTM的输入来自连续8帧 ( n τ ) (n_{\tau}) (nτ)的34维 ( n f e a t ) (n_{feat}) (nfeat)特征向量,需要Tracker的辅助,来连接多帧的同一目标(输入为一个二维矩阵, n τ = 8 , n f e a t = 34 n_{\tau}=8,n_{feat}=34 nτ=8,nfeat=34,经过LSTM处理后特征维度提升到80,接着采样传统的全连接层 + softmax进行分类,选取概率值较大的作为当前特征向量的类别)

-
实验结果:通过LSTM和Random Forest的对比可知,LSTM并没有体现出很大的优势。具体原因分析是因为:序列长度较短,导致信息量不够;手工设计的特征限制了LSTM的学习能力。
-
该方法的缺点
- 聚类算法的鲁棒性不足,需要通过时序融合来进行改进
- 手工设计的特征信息量不足,限制了深度神经网络的学习能力
(4)直接处理点云——候选生成 + 特征提取(Deep Learning) + 候选分类(Deep Learning)
-
论文:Danzer, et al., 2D Car Detection in Radar Data with PointNets, 2019. From University of Ulm
-
整体结构

-
每个点生成一个候选
- 候选大小由先验知识确定:比如说若要进行车辆检测,则将候选大小设计为车辆的先验大小;若要进行多类别目标检测,则要估计多类别目标的先验大小在每个点处去生成多个候选来对应多个类别的目标
- 每个候选采样n个邻域点:每个点包括x坐标、y坐标、速度、反射强度4个特征
-
采用PointNet提取特征并对候选进行分类,在分类时对前景点根据类别设计 n s n_s ns个模板和 n h n_h nh个离散角度。然后,在分类的基础上,回归出与大小模板和离散角度的偏差(偏差值相对于绝对值是较小的,这样有利于神经网络的训练)。在分类+回归的作用下,获取候选精确的大小和角度。
-
PointNet同时给出点云分割的结果,来判断每个点属于前景点还是背景点
- 将前景点的绝对坐标转换为相对候选中心的相对坐标
- 根据前景点来估计候选bbox大小和朝向
- 网络输出:2表示物体中心点的预测,3
n
s
n_s
ns表示分类时
n
s
n_s
ns个大小模板 + 回归时
n
s
n_s
ns个偏差(长和宽两个方向),2
n
h
n_h
nh表示分类时
n
h
n_h
nh个离散角度 + 回归时
n
h
n_h
nh个偏差纠正

(5)网络数据 + 端到端检测(Deep Learning)
- 论文:Dreher et al., Radar-based 2D Car Detection Using Deep Neural Networks, 2020. From Technical University of Munich
- 点云转换为俯视图网格(2D)
-
- 点云量化:每个网格最多保留一个点
- 网格特征:速度、反射强度
- 端到端检测:YOLO V3物体检测网络

(6)实验结论
- 通过NuScenes数据库上的实验结果分析可知:
- 直接处理点云和转换成网格的检测结果都不太理想
- 基于网格的方法在小物体上的效果更差
- 原因分析
- 毫米波雷达点云过于稀疏,大量信息在信号处理阶段丢失 ==> 解决办法:采样深度神经网络直接处理底层数据
- 单帧点云噪声较大,需要有效的时序融合 ==> 解决办法:采样循环神经网络融合多帧时序信息
3. 稠密数据块+深度学习
3.1 直接处理Range-Azimuth-Doppler数据块
(1)方法1:RA模型
采样均值池化的方法沿着多普勒(Doppler)维度进行压缩,得到Range-Azimuth二维特征图
(2)方法2:RAD模型
- 采样均值池化是方法,分别沿着D、A、R三个维度进行处理,得到RA、RD、AD三个2D特征图
- 上述得到的三个2D特征图大小是不一样的,需要将其扩展为同一尺寸后合并为三维RAD数据
- 通过3D卷积和池化将Doppler维度压缩到一维(去掉Doppler维度),得到二维数据
- 采样U-Net结构,将得到的二维数据与原始的RA特征图进行合并
(3)对RA Tensor进行进一步处理
不管是采用方法1的RA模型得到的RA特征图,还是采用方法2的RAD模型得到的RA特征图,都需要将传感器的极坐标系转换到车辆的笛卡尔坐标系下。
3.2 RAD模型方法
对三维的RAD数据块采用2D卷积的方式,分别在RA、RD、AD维度上进行处理(另外一个维度当作通道)。经过一系列卷积降采样操作得到RA、RD、AD特征图,然后分别在Doppler、Azimuth、Range维度上进行重复堆叠,使三者恢复为大小相同的3D特征,并且沿着Doppler维度进行concat拼接,得到融合后的3D特征。然后,将融合的3D特征看成Doppler为通道的图像,沿着Doppler维度采用U型网络的方法对其进行上采样,并与原始的RA特征进行融合。网络输出为具有原始分辨率的RA特征图,然后将其从极坐标系转换到笛卡尔坐标系。接着,采用LSTM进行时序融合,融合多帧信息,提高检测系统的稳定性。最后,采用检测头detection来完成目标检测任务。
3.3 RAMP-CNN
-
论文:Gao et al., RAMP-CNN: A Novel Neural Network for Enhanced Automotive Radar Object Recognition, 2020. From University of Washington
-
大致思路:将RAD数据块分解成3部分进行处理,然后再合并到一起
-
与RAD模型的区别
- 其中的RA特征图的处理比RAD模型更加复杂
- 多帧数据的时序融合是在合并之前进行的,而RAD模型的多帧时序融合是在特征合并之后进行的
- 采用3D自编码器(AutoEncoder)处理多帧数据,而RAD模型是采用LSTM来处理多帧数据

(1)RA分支的处理
- 对ADC数据块分别在Range和Azimuth维度上进行FFT操作,保留Chirp维度(Doppler维度),得到Range-Azimuth-Chirp数据块
- 每帧数据只在任意一个Chirp上得到RA特征图,将多帧的RA特征图融合得到3D特征图
- 采用3D卷积在多帧数据上提取Doppler信息(既包含多帧信息(时序),也包含空间的邻域信息(3D卷积))
(2)RD和AD分支的处理方法与RAD模型中的处理方法相同
(3)三维卷积自编码器
采用三维卷积自编码器进行特征提取,来处理来自多帧的RA、RD、AD特征图(既可以在空间维度上提取信息,也可以在时序维度上提取信息)
(4)RA、RD、AD特征融合模块
以RA特征图为基础,对RA、RD、AD特征进行拼接融合。其中RD特征图是先通过pooling操作将Doppler维度压缩到一维,然后在Angle维度上进行重复,从而恢复出RA特征图大小;AD特征图是先通过pooling操作将Doppler维度压缩到一维,然后在Range维度上进行重复,从而恢复出RA特征图大小。最后将原始的RA特征图与得到的两个RA大小的特征图在Doppler维度上进行拼接融合,最后将融合的特征图从极坐标系转换到笛卡尔坐标系下。
3.4 RODNet
- 论文:Wang et al., AReal-Time Radar Object Detection Network Cross-Supervised by Camera-Radar Fused Object 3D Localization, 2020. From University of Washington.
在Chirp采用和天线维度上进行FFT操作,得到距离和角度。因此输入数据是Range-Azimuth-Chirp,将Chirp维度保留,后续采用神经网络进行处理。
(1)三种不同的主干网络结构
标准编码-解码结构,带Skip连接的Hour-Glass结构(HG),带Inception卷积的HG结构
网络输入:
(
C
R
F
,
T
,
n
,
H
,
W
)
(C_{RF},T,n,H,W)
(CRF,T,n,H,W),其中
C
R
F
C_{RF}
CRF表示特征图的实部和虚部,因此
C
R
F
C_{RF}
CRF值为2,
T
T
T表示时序融合的帧数,
n
n
n指
n
n
n个Chirp,H和W分别表示RA特征图的高和宽.
网络输出:
(
C
c
l
s
,
T
,
H
,
W
)
(C_{cls},T,H,W)
(Ccls,T,H,W),其中
C
c
l
s
C_{cls}
Ccls表示目标类别数,其余维度与输入表示含义与输入一样。
(2)M-Net
- 使用 ( w , 1 , 1 ) (w,1,1) (w,1,1)的3D卷积核对输入的 ( 2 , n , H , W ) (2,n,H,W) (2,n,H,W)数据在chirp维度进行卷积操作,来提取运动信息
- 采用Max-Pooling将Chirp维度压缩到1维,得到Range-Azimuth二维特征图
- 对每帧数据都进行上述相同的M-Net处理

(3)时序融合:3D可变性卷积
将多帧的经M-Net处理后的结果 ( C 1 , T , H , W ) (C_1,T,H,W) (C1,T,H,W) 通过可变形卷积进行时序融合,得到 通过可变形卷积进行时序融合,得到 通过可变形卷积进行时序融合,得到(C_2,T,H,W) 。其中, 。其中, 。其中, T T T为时序的融合帧数。
3D可变形卷积是标准卷积的扩展,它是指同一空间位置在不同帧时刻的卷积采样位置不同,它可以更好地适应目标在多帧时间内的空间移动。
(4)时序融合:3D Inception模型
具体结构如下图所示,左边分支在空间维度上进行卷积下采样,中间和右边分支在时序维度上分别采用9和13的kernel进行卷积,从而实现在空间和时序两个维度上的特征提取。
(5)损失函数——多类别的二值分类(Binary Cross Entropy)
l
=
−
∑
c
l
s
∑
i
,
j
D
i
,
j
c
l
s
l
o
g
D
^
i
,
j
c
l
s
+
(
1
−
D
i
,
j
c
l
s
)
l
o
g
(
1
−
D
^
i
,
j
c
l
s
)
D
:
表示
G
T
,
它是根据标注生成的二值
C
o
n
f
M
a
p
D
^
:
表示
p
r
e
d
,
它是网络预测的
C
o
n
f
M
a
p
(
C
c
l
s
,
T
,
H
,
W
)
表示
G
T
和
p
r
e
d
的大小,其中
C
c
l
s
为目标类别数
,
T
为融合帧数
,
H
和
W
为特征图尺寸
l=-\sum_{cls}\sum_{i,j}D_{i,j}^{cls}log\hat{D}_{i,j}^{cls}+(1-D_{i,j}^{cls})log(1-\hat{D}_{i,j}^{cls}) \\ D:表示GT,它是根据标注生成的二值ConfMap \\ \hat{D}:表示pred, 它是网络预测的ConfMap \ \ \ \ \ \ \ \ \ \ \ \ \\ (C_{cls},T,H,W)表示GT和pred的大小,其中C_{cls}为目标类别数,T为融合帧数,H和W为特征图尺寸
l=−cls∑i,j∑Di,jclslogD^i,jcls+(1−Di,jcls)log(1−D^i,jcls)D:表示GT,它是根据标注生成的二值ConfMapD^:表示pred,它是网络预测的ConfMap (Ccls,T,H,W)表示GT和pred的大小,其中Ccls为目标类别数,T为融合帧数,H和W为特征图尺寸
(6)后处理流程(NMS)
- Object Location Similarity(OLS):一种相似性的度量方式,用来代替bounding box中的IoU
O L S = e x p ( − d 2 2 ( s k c l s ) 2 ) OLS=exp(\frac{-d^2}{2(sk_{cls})^2}) OLS=exp(2(skcls)2−d2)
d d d:表示两个点在RF特征图上的距离(米),需要将点从极坐标系下转换到笛卡尔坐标系下
s s s:物体距离雷达的距离(米)
k c l s k_{cls} kcls:根据不同物体类别设置的常量文章来源:https://www.toymoban.com/news/detail-823130.html
基于OLS的NMS方法文章来源地址https://www.toymoban.com/news/detail-823130.html
- 在ConfMap中找到所有的8邻域的局部极值点,形成集合P
- 把集合P中置信度最高的点p加入集合 P , P^, P,,并将其从集合P中删除
- 计算集合P中每个点和 p , p^, p,的OLS,如果高于设定的阈值,则将该点从集合P中删除
- 重复步骤2、3,直到集合P为空
- 输出集合 P , P^, P,作为当前类别的ConfMap的最终检测结果
- 对每个类别的ConfMap重复以上步骤
到了这里,关于自动驾驶环境感知之基于深度学习的毫米波雷达感知算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!