文章主线
通过自定义UDAF 实现clickhouse中的内置函数 countResample
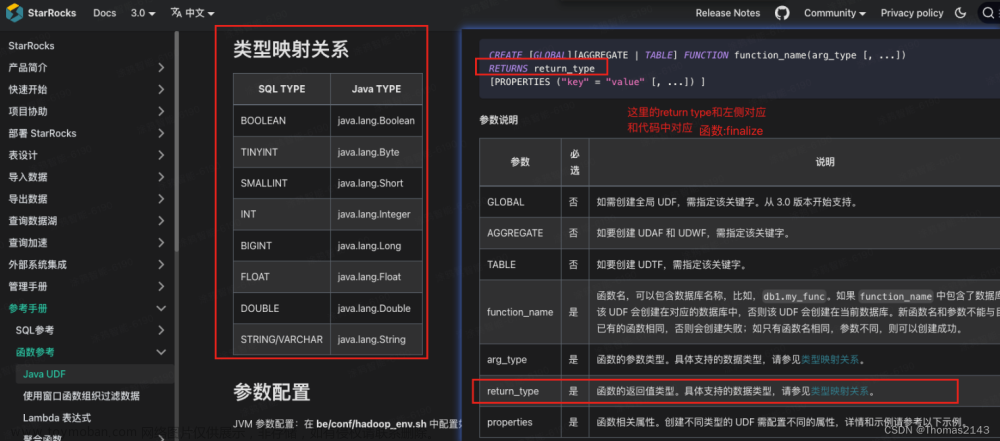
官方文档
Java UDF | StarRocks
UDF
java scala都可以
UDAF
java可以 scala一直报错类找不到 实际上类在的
UDAF 可以接受多个参数输入 比如固定值 比如列数据
UDAF 目前不支持返回复杂数据类型 如数组之类
 文章来源:https://www.toymoban.com/news/detail-823133.html
文章来源:https://www.toymoban.com/news/detail-823133.html
countResample 效果
 文章来源地址https://www.toymoban.com/news/detail-823133.html
文章来源地址https://www.toymoban.com/news/detail-823133.html
自定义函数实现 countResample
package tuya.starrocks.udaf;
import com.google.common.primitives.Bytes;
import java.util.ArrayList;
import java.util.Arrays;
/*
时间段 左闭 右开
*/
public class CountResample {
// 用的 long所以配置8
static int DataT到了这里,关于starrocks3.0 编写自定义UDF java/scala版本 clickhouse中countResample的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!