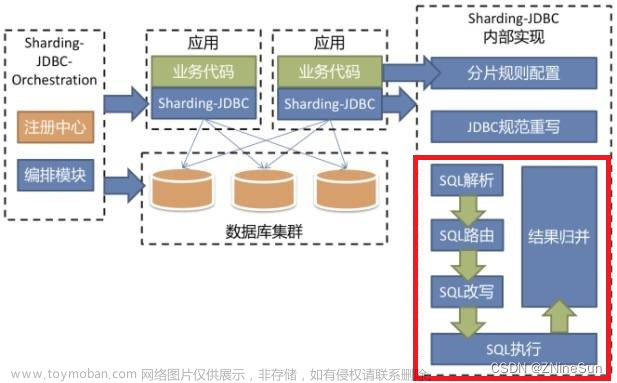
数据量在百万以里,可以通过Tina集从库、优化索引等提升性能
数据量超过千万,为了减少数据库的负担,提升数据库响应速度,缩短查询时间,需要进行分库分表
分库策略
推荐:采用垂直分库&水平分表
总结:分库要解决的是硬件资源的问题,不管是拆分字段,还是拆分数据,都是要拆到不同的数据库不同的服务器上,从硬件资源上解决性能瓶颈。而分表是解决单表数据量过大的问题,拆分完后还是放在同一数据库中不同表里面,只是减少了单表的读写锁资源消耗,如果性能瓶颈在硬件资源,只是简单的分表并不能从根本上解决问题,所有具体分库分表亦或者是结合使用都要结合具体的业务场景
垂直切分
垂直分库(专库专用)
每一个独立的服务(业务)都拥有自己的数据库,如订单、用户、商品
垂直分表(拆表)
基于数据表的列为依据切分,大表拆小表,拆的是表结构,如一个表内将常用和访问不频繁的字段分到不同表中存储,把text,blob等大字段拆分出来放在附表中
优点
- 业务间解耦,不同业务的数据进行独立的维护、监控、扩展
- 在高并发场景下,一定程度上缓解了数据库的压力
缺点
- 提升了开发的复杂度,由于业务的隔离性,很多表无法直接访问,必须通过接口方式聚合数据,
- 分布式事务管理难度增加
- 数据库还是存在单表数据量过大的问题,并未根本上解决,需要配合水平切分
水平(Sharding)切分
水平分表
分的是数据,将一张大数据量的表,切分成多个表结构相同,而每个表只占原表一部分数据,然后按不同的条件分散到多个数据库中。
库内分表
表拆分了,但还在一个数据库内,还是存在竞争同一物理机的CPU、内存、网络IO
分库分表
将切分出来的子表,放到不同数据库
优点
- 解决高并发时单库数据量过大的问题,提升系统稳定性和负载能力
- 业务系统改造的工作量不是很大
缺点
- 跨分片的事务一致性难以保证
- 跨库的join关联查询性能较差
- 扩容的难度和维护量较大,子表如果过多难以维护,增加系统复杂度
分表策略
hash取模方案
hash(key) % NUM_DB
id数据取模,按照不同的模值存放到不同表
优点:
- 数据分片相对比较均匀,不易出现某个库并发访问的问题
- 同维度的数据便于存到一个库内,便于查询定位,不用跨库查询
缺点: - 当某一台机器宕机,本应该落在该数据库的请求就无法得到正确的处理,这时宕掉的实例会被踢出集群,此时算法变成hash(userId) mod N-1,用户信息可能就不再在同一个库中
- 不便于分库,模值很难定义,后续数据量不断增多,如果再次分表比较麻烦,不利于水平扩展
range范围区间取值方案
可以是 ID 范围也可以是时间范围
按ID区间区分,0-10000,10000-20000
优点:
- 单表数据量是可控的
- 水平扩展简单只需增加节点即可,无需对其他分片的数据进行迁移
- 可以分库存储,能快速定位要查询的数据在哪个库
缺点: - 由于连续分片可能存在数据热点问题,如果按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
映射表方案
使用单独的一个数据库来存储映射关系
分库分表问题
事务一致性问题
由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题。
跨节点关联查询
由于原来一张表的数据现在分布在不同数据库,不同表中,在涉及到多表关联,一定要设计好分片策略以及查询条件,否则很可能出现笛卡尔积现象,导致性能更低。
笛卡尔积现象:当进⾏多张表联合查询的时候,在没有任何条件进⾏限制情况下,最终查询结果条数是多张表记录条数的乘积!
跨节点分页、排序函数
跨节点多库进行查询时,limit分页、order by排序等问题,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。
主键避重
不能在采用数据库自增主键,应采用分布式id,保证全局唯一。
公共表
实际的应用场景中,参数表、数据字典表等都是数据量较小,变动少,而且属于高频联合查询的依赖表。例如地理区域表也属于此类型。可以将这类表在每个数据库都保存一份,所有对公共表的更新操作都同时发送到所有分库执行。
分库分表工具
- sharding-jdbc(当当)
- TSharding(蘑菇街)
- Atlas(奇虎360)
- Cobar(阿里巴巴)
- MyCAT(基于Cobar)
- Oceanus(58同城)
- Vitess(谷歌)
- ShardingSphere(京东)
sharding-jdbc官网
分库后的查询问题
用户端:按照用户id,订单id(内部含userid后四位)
商家端:商家id,mq备份一下订单数据
运营管理端:查全量,非实时(数据仓库),实时(elasticsearch)
数据迁移
停机迁移(一般都不允许)
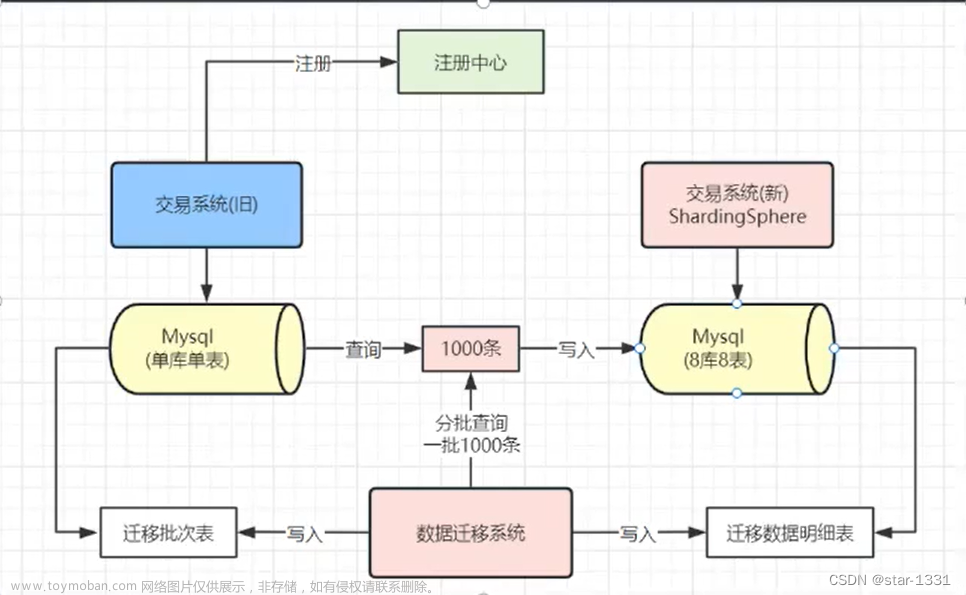
不停机迁移
有不断的增删改查
同步:
binlog日志、canal(阿里开源),同步两个表
增量同步的话可能会组件/数据冲突,update和delete会有问题,数据混乱
rocketmg延迟再传递一遍
运行一段时间,抽检,总数的比对等进行校验
上线
不会全量把老系统下掉
有损发布:
做一个灰度发布(用一部分流量打到新的系统),观察一段时间
少数情况下,数据到了新系统,旧系统没有,会有一部分数据问题
无损发布:
短暂灰度之后,全流量切
TiDB分布式数据架构
雪花算法(Snowflake)— 唯一ID的生成和管理
一种全局ID生成算法,其核心思想是将64位的long型ID分为四个部分,分别为:时间戳、工作机器ID、数据中心ID和序列号。通过将数据映射到具有特定结构的分布式系统中,实现数据的存储和查询。该算法由一系列节点组成,每个节点负责存储数据的一部分。这些节点通过哈希函数将数据映射到特定的位置,形成类似于雪花结构的分布式系统。通过这种方式,雪花算法能够在分布式系统中保证ID的唯一性和有序性。 文章来源:https://www.toymoban.com/news/detail-823508.html
文章来源:https://www.toymoban.com/news/detail-823508.html
美团实践
大众点评订单系统分库分表实践文章来源地址https://www.toymoban.com/news/detail-823508.html
到了这里,关于数据库-分库分表初探的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!