1. 前言
前两天接了个需求,要求将数据导出成word,里边有边个,有其他的东西,怎么说这,这个需求最开始就是上传word,下载附件就行了,非得改成上传数据然后支持下载word。有股脱裤子放屁的感觉
而且呢,当时做的时候前任开发在数据库存了一个巨大的Json文件,解析也挺费劲的咱就是说。本来只为难前端,现在前后端全部为难一遍。
最终敲定了两版方案,都有这些许瑕疵
- 原生POI
这个方案吧,纯手撸,
根据word模板生成word的时候,表格内的文字无法设置行距1.0,首行缩进2字符无法取消,数字会换行。
- EasyPoi
相对简单一点,但是也有不小的问题,表格内的字体无法设置中文,行距和首行缩进问题得到解决,
但是这个包读取模板文件有点问题,不过可以自行解决
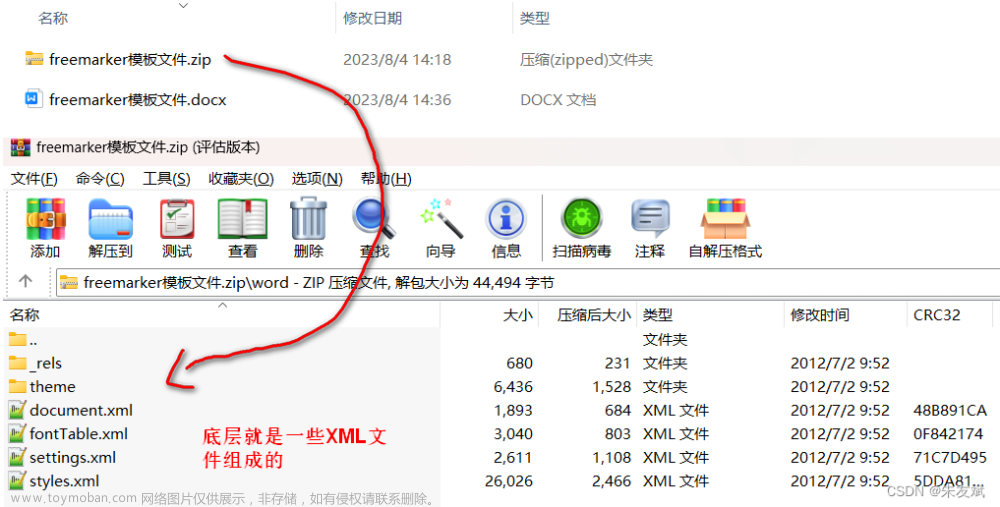
- 修改docx的document.xml
用zip将docx解压出来改xml,怎么说呢,不是人能干的活,眼都能看瞎
2. 解决方案
1 原生POI
1. 引入依赖
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
<!--导出word数据-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
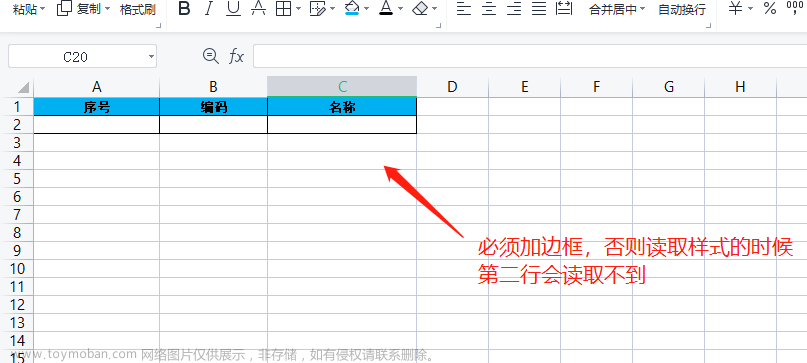
2. 创建一个word模板
就类似下边这样的一个模板,最开始用{companyName}这样的占位符,结果原生poi给我的这个占位符识别成了三个段落,后来就改成这样了

3. 准备数据
我的数据存在一个巨大的json里边,要是其他的数据可以改造下边的fillTableData方法
{
"companyName": "测试",
"startTime": "2024-01-24",
"endTime": "2024-01-31",
"content": "{\"companyName\":\"测试\",\"userList\":[{\"id\":1,\"name\":\"测试\",\"age\":18,\"birthDay\":\"1999-01-01\",\"hobby\":\"\",\"extra\":\"\"}]}"
}
4. 代码编写
package org.example;
import cn.hutool.core.util.StrUtil;
import com.google.gson.Gson;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.xwpf.usermodel.*;
import org.example.entity.ReportInfo;
import org.junit.Test;
import org.springframework.core.io.ClassPathResource;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.text.SimpleDateFormat;
import java.time.DayOfWeek;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.time.temporal.TemporalAdjusters;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author eleven
* @date 2024/1/22 9:08
* @apiNote
*/
@Slf4j
public class DocxTest {
@Test
public void test() {
Gson gson = new Gson();
// 从resources下获取文件数据
ClassPathResource resource = new ClassPathResource("response.json");
ClassPathResource docxResource = new ClassPathResource("word模板.docx");
try (InputStreamReader inputStreamReader = new InputStreamReader(resource.getInputStream());
XWPFDocument document = new XWPFDocument(docxResource.getInputStream());
FileOutputStream fos = new FileOutputStream("e:\\output.docx")
){
ReportInfo reportInfo = gson.fromJson(inputStreamReader, ReportInfo.class);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// 获取文档的所有段落
List<XWPFParagraph> paragraphs = document.getParagraphs();
Map reportInfoMap = getReportInfo(reportInfo);
replaceRegex(paragraphs, "companyName", String.valueOf(reportInfoMap.get("companyName")));
replaceRegex(paragraphs, "startTime", sdf.format(reportInfo.getStartTime()));
replaceRegex(paragraphs, "endTime", sdf.format(reportInfo.getEndTime()));
// 获取所有表格
List<XWPFTable> tables = document.getTables();
fillTableData(tables.get(0),
getTableData(reportInfoMap,
"userList",
"id",
"name",
"age",
"birthDay",
"hobby",
"extra"
)
);
document.write(fos);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 获取表格的数据
* @param reportInfoMap map数据
* @param key json数据中的key
* @param sortedCellKey 表格中排序好的cell表格字段
* @return List<List<String>> 表格中每一行的数据
*/
@SuppressWarnings("unchecked")
private List<List<String>> getTableData(Map reportInfoMap, String key, String... sortedCellKey) {
Object data = reportInfoMap.get(key);
if (data instanceof List) {
List<Map> dataList = (List<Map>)data;
List<List<String>> result = new ArrayList<>(dataList.size());
List<String> rowData = new ArrayList<>(sortedCellKey.length);
for (Map map : dataList) {
for (String cellKey : sortedCellKey) {
if (StrUtil.equalsAnyIgnoreCase("id", cellKey)) {
rowData.add(String.valueOf(dataList.indexOf(map) + 1));
} else {
rowData.add(String.valueOf(map.get(cellKey)));
}
}
result.add(rowData);
}
return result;
}
return null;
}
/**
* 填充表格数据,默认第0行为表头,有合并表头的话用另外一个方法
* @param table 文档中的表格对象
* @param data 要填充的数据
*/
private void fillTableData(XWPFTable table, List<List<String>> data) {
fillTableData(table, 0, data);
}
/**
*
* @param table 要填中的表格对象
* @param lastHeaderRow 表头的最后一行行数,从0开始计数,合并表头的表格填写此参数
* @param data 填充的数据
*/
private void fillTableData(XWPFTable table, Integer lastHeaderRow, List<List<String>> data) {
if (null == lastHeaderRow) {
lastHeaderRow = 0;
}
List<XWPFTableRow> rows = table.getRows();
// 表头结束行
XWPFTableRow headerRow = rows.get(lastHeaderRow);
List<String> headers = new ArrayList<>();
for (XWPFTableCell cell : headerRow.getTableCells()) {
headers.add(cell.getText());
}
// 拼接数据到表格中
for (List<String> rowData : data) {
XWPFTableRow newRow = table.createRow();
for (int j = 0; j < headers.size(); j++) {
XWPFTableCell cell = newRow.getCell(j);
if (cell == null) {
cell = newRow.createCell();
}
cell.removeParagraph(0);
//设置段落的样式,行间距
XWPFParagraph paragraph = cell.addParagraph();
paragraph.setSpacingBetween(1);
paragraph.setIndentationFirstLine(0);
paragraph.setIndentationLeft(0);
XWPFRun run = paragraph.createRun();
run.setFontFamily("仿宋_GB2312");
// 小五
run.setFontSize(9);
run.setText(rowData.get(j));
}
}
}
private Map getReportInfo(ReportInfo info) {
String content = info.getContent();
Gson gson = new Gson();
return gson.fromJson(content, Map.class);
}
/**
* 替换段落中的模板
* @param paragraphs 文档中的段落结合
* @param regex 占位字符串
* @param str 要替换的值
*/
private void replaceRegex(List<XWPFParagraph> paragraphs, String regex, String str) {
// 如果要替换的值为null需要设置默认值,否则生成的模板中有占位字符串
if (StrUtil.isBlank(str)) {
str = "无。";
}
for (XWPFParagraph paragraph : paragraphs) {
List<XWPFRun> runs = paragraph.getRuns();
for (XWPFRun run : runs) {
String text = run.getText(0);
if (StrUtil.isNotBlank(text) && text.contains(regex)) {
run.setText(text.replace(regex, str), 0);
}
}
}
}
}
5. 存在的问题
- 替换的字符必须不为空,否则生成的word中会有占位字符串存在
- 生成的表格中的文字无法设置行距,首行缩进无法取消,经过测试这个首行缩进应该是字体的原因,不设置
仿宋字体就可以。默认字体为Times New Roman
2. EasyPoi
1. 引入依赖
<!--EasyPoi-->
<dependency>
<groupId>cn.afterturn</groupId>
<artifactId>easypoi-spring-boot-starter</artifactId>
<version>4.1.2</version>
</dependency>
2. 创建一个模板
和vue中的语法有点类似 {{companyName}}即可替换。
表格横向填充需要写特殊语句, $fe:代表横向遍历,创建新行,
更多模板内容参考
- 使用EasyPoi导出复杂Word
- Springboot系列(十六):集成easypoi实现word模板多数据页导出(实战篇二)
- Springboot系列(十六):集成easypoi实现word模板多数据页导出(实战篇一)
- 官方文档
{{$fe: userList t.id}}

3. 代码编写
package org.example;
import cn.afterturn.easypoi.word.WordExportUtil;
import com.google.gson.Gson;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.example.entity.ReportInfo;
import org.junit.Test;
import org.springframework.core.io.ClassPathResource;
import java.io.FileOutputStream;
import java.io.InputStreamReader;
import java.text.SimpleDateFormat;
import java.util.List;
import java.util.Map;
/**
* @author eleven
* @date 2024/1/22 9:08
* @apiNote
*/
@Slf4j
public class EasyDocxTest {
@Test
public void easyPoiTest() {
Gson gson = new Gson();
ClassPathResource resource = new ClassPathResource("response.json");
try (InputStreamReader inputStreamReader = new InputStreamReader(resource.getInputStream());
FileOutputStream fos = new FileOutputStream("e:\\output2.docx")
) {
//准备数据
ReportInfo reportInfo = gson.fromJson(inputStreamReader, ReportInfo.class);
Map reportInfoMap = getReportInfo(reportInfo);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// 这里如果不是字
reportInfoMap.put("userList", getEasyPoiTableData(reportInfoMap, "userList"));
// 单module应用直接放在resources下
XWPFDocument afterDoc = WordExportUtil.exportWord07("test2.docx", reportInfoMap);
afterDoc.write(fos);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 获取map数据
* @param reportInfoMap 要填充的数据
* @param key table在实体类中的key
* @return List<Map>
*/
@SuppressWarnings("unchecked")
private List<Map> getEasyPoiTableData(Map reportInfoMap, String key) {
Object data = reportInfoMap.get(key);
if (data instanceof List) {
List dataMap = (List) data;
dataMap.forEach(item -> {
Map map = (Map) item;
map.put("id", dataMap.indexOf(item) + 1);
});
return dataMap;
}
return null;
}
private Map getReportInfo(ReportInfo info) {
String content = info.getContent();
Gson gson = new Gson();
return gson.fromJson(content, Map.class);
}
}
4. 存在的问题
- 我的项目结构是多module的,有一个专门的runner启动,但是我的模板是放在另外一个module下的resources的。这个
WordExportUtil.exportWord07("test2.docx", reportInfoMap)去找了runner启动包下的resources下的模板,就报空指针了 - 同样的无法切换表格内的字体(也可能是因为因为我不会)
- 官网对于word导出的文档有点少
5. 解决获取不到模板的问题
官网说可以实现一个
IFileLoader接口,用偏房子解决了
-
创建一个
MyParseWord07类,修改源码中通过
url获取输入流的代码,主要就是179-194行的代码,将源码中通过POIManager获取输入流的代码,手动改成通过ClasspathResource获取文章来源:https://www.toymoban.com/news/detail-823510.html
import cn.afterturn.easypoi.cache.WordCache;
import cn.afterturn.easypoi.entity.ImageEntity;
import cn.afterturn.easypoi.util.PoiPublicUtil;
import cn.afterturn.easypoi.word.entity.MyXWPFDocument;
import cn.afterturn.easypoi.word.entity.params.ExcelListEntity;
import cn.afterturn.easypoi.word.parse.ParseWord07;
import cn.afterturn.easypoi.word.parse.excel.ExcelEntityParse;
import cn.afterturn.easypoi.word.parse.excel.ExcelMapParse;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.xwpf.usermodel.*;
import org.springframework.core.io.ClassPathResource;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import static cn.afterturn.easypoi.util.PoiElUtil.*;
/**
* @author eleven
* @date 2024/1/23 10:19
* @apiNote
*/
@Slf4j
public class MyParseWord07 extends ParseWord07 {
private void changeValues(XWPFParagraph paragraph, XWPFRun currentRun, String currentText,
List<Integer> runIndex, Map<String, Object> map) throws Exception {
Object obj = PoiPublicUtil.getRealValue(currentText, map);
if (obj instanceof ImageEntity) {// 如果是图片就设置为图片
currentRun.setText("", 0);
ExcelMapParse.addAnImage((ImageEntity) obj, currentRun);
} else {
currentText = obj.toString();
PoiPublicUtil.setWordText(currentRun, currentText);
}
for (int k = 0; k < runIndex.size(); k++) {
paragraph.getRuns().get(runIndex.get(k)).setText("", 0);
}
runIndex.clear();
}
/**
* 判断是不是迭代输出
*
* @return
* @throws Exception
* @author JueYue
* 2013-11-18
*/
private Object checkThisTableIsNeedIterator(XWPFTableCell cell,
Map<String, Object> map) throws Exception {
String text = cell.getText().trim();
// 判断是不是迭代输出
if (text != null && text.contains(FOREACH) && text.startsWith(START_STR)) {
text = text.replace(FOREACH_NOT_CREATE, EMPTY).replace(FOREACH_AND_SHIFT, EMPTY)
.replace(FOREACH, EMPTY).replace(START_STR, EMPTY);
String[] keys = text.replaceAll("\\s{1,}", " ").trim().split(" ");
return PoiPublicUtil.getParamsValue(keys[0], map);
}
return null;
}
/**
* 解析所有的文本
*
* @param paragraphs
* @param map
* @author JueYue
* 2013-11-17
*/
private void parseAllParagraphic(List<XWPFParagraph> paragraphs,
Map<String, Object> map) throws Exception {
XWPFParagraph paragraph;
for (int i = 0; i < paragraphs.size(); i++) {
paragraph = paragraphs.get(i);
if (paragraph.getText().indexOf(START_STR) != -1) {
parseThisParagraph(paragraph, map);
}
}
}
/**
* 解析这个段落
*
* @param paragraph
* @param map
* @author JueYue
* 2013-11-16
*/
private void parseThisParagraph(XWPFParagraph paragraph,
Map<String, Object> map) throws Exception {
XWPFRun run;
XWPFRun currentRun = null;// 拿到的第一个run,用来set值,可以保存格式
String currentText = "";// 存放当前的text
String text;
Boolean isfinde = false;// 判断是不是已经遇到{{
List<Integer> runIndex = new ArrayList<Integer>();// 存储遇到的run,把他们置空
for (int i = 0; i < paragraph.getRuns().size(); i++) {
run = paragraph.getRuns().get(i);
text = run.getText(0);
if (StringUtils.isEmpty(text)) {
continue;
} // 如果为空或者""这种这继续循环跳过
if (isfinde) {
currentText += text;
if (currentText.indexOf(START_STR) == -1) {
isfinde = false;
runIndex.clear();
} else {
runIndex.add(i);
}
if (currentText.indexOf(END_STR) != -1) {
changeValues(paragraph, currentRun, currentText, runIndex, map);
currentText = "";
isfinde = false;
}
} else if (text.indexOf(START_STR) >= 0) {// 判断是不是开始
currentText = text;
isfinde = true;
currentRun = run;
} else {
currentText = "";
}
if (currentText.indexOf(END_STR) != -1) {
changeValues(paragraph, currentRun, currentText, runIndex, map);
isfinde = false;
}
}
}
private void parseThisRow(List<XWPFTableCell> cells, Map<String, Object> map) throws Exception {
for (XWPFTableCell cell : cells) {
parseAllParagraphic(cell.getParagraphs(), map);
}
}
/**
* 解析这个表格
*
* @param table
* @param map
* @author JueYue
* 2013-11-17
*/
private void parseThisTable(XWPFTable table, Map<String, Object> map) throws Exception {
XWPFTableRow row;
List<XWPFTableCell> cells;
Object listobj;
for (int i = 0; i < table.getNumberOfRows(); i++) {
row = table.getRow(i);
cells = row.getTableCells();
listobj = checkThisTableIsNeedIterator(cells.get(0), map);
if (listobj == null) {
parseThisRow(cells, map);
} else if (listobj instanceof ExcelListEntity) {
new ExcelEntityParse().parseNextRowAndAddRow(table, i, (ExcelListEntity) listobj);
i = i + ((ExcelListEntity) listobj).getList().size() - 1;//删除之后要往上挪一行,然后加上跳过新建的行数
} else {
ExcelMapParse.parseNextRowAndAddRow(table, i, (List) listobj);
i = i + ((List) listobj).size() - 1;//删除之后要往上挪一行,然后加上跳过新建的行数
}
}
}
/**
* 解析07版的Word并且进行赋值
*
* @return
* @throws Exception
* @author JueYue
* 2013-11-16
*/
public XWPFDocument parseWord(String url, Map<String, Object> map) throws Exception {
MyXWPFDocument doc = getXWPFDocument(url);
parseWordSetValue(doc, map);
return doc;
}
public static MyXWPFDocument getXWPFDocument(String url) {
ClassPathResource classPathResource = new ClassPathResource(url);
try(InputStream inputStream = classPathResource.getInputStream()) {
MyXWPFDocument doc = new MyXWPFDocument(inputStream);
return doc;
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return null;
}
/**
* 解析07版的Work并且进行赋值但是进行多页拼接
*
* @param url
* @param list
* @return
*/
public XWPFDocument parseWord(String url, List<Map<String, Object>> list) throws Exception {
if (list.size() == 1) {
return parseWord(url, list.get(0));
} else if (list.size() == 0) {
return null;
} else {
MyXWPFDocument doc = WordCache.getXWPFDocumen(url);
parseWordSetValue(doc, list.get(0));
//插入分页
doc.createParagraph().setPageBreak(true);
for (int i = 1; i < list.size(); i++) {
MyXWPFDocument tempDoc = WordCache.getXWPFDocumen(url);
parseWordSetValue(tempDoc, list.get(i));
tempDoc.createParagraph().setPageBreak(true);
doc.getDocument().addNewBody().set(tempDoc.getDocument().getBody());
}
return doc;
}
}
/**
* 解析07版的Word并且进行赋值
*
* @throws Exception
*/
public void parseWord(XWPFDocument document, Map<String, Object> map) throws Exception {
parseWordSetValue((MyXWPFDocument) document, map);
}
private void parseWordSetValue(MyXWPFDocument doc, Map<String, Object> map) throws Exception {
// 第一步解析文档
parseAllParagraphic(doc.getParagraphs(), map);
// 第二步解析页眉,页脚
parseHeaderAndFoot(doc, map);
// 第三步解析所有表格
XWPFTable table;
Iterator<XWPFTable> itTable = doc.getTablesIterator();
while (itTable.hasNext()) {
table = itTable.next();
if (table.getText().indexOf(START_STR) != -1) {
parseThisTable(table, map);
}
}
}
/**
* 解析页眉和页脚
*
* @param doc
* @param map
* @throws Exception
*/
private void parseHeaderAndFoot(MyXWPFDocument doc, Map<String, Object> map) throws Exception {
List<XWPFHeader> headerList = doc.getHeaderList();
for (XWPFHeader xwpfHeader : headerList) {
for (int i = 0; i < xwpfHeader.getListParagraph().size(); i++) {
parseThisParagraph(xwpfHeader.getListParagraph().get(i), map);
}
}
List<XWPFFooter> footerList = doc.getFooterList();
for (XWPFFooter xwpfFooter : footerList) {
for (int i = 0; i < xwpfFooter.getListParagraph().size(); i++) {
parseThisParagraph(xwpfFooter.getListParagraph().get(i), map);
}
}
}
}
- 创建
MyWordExportUtil
替换官方的
MyWordExportUtil,变更其中的exportWord07为自己的解析方法文章来源地址https://www.toymoban.com/news/detail-823510.html
import cn.afterturn.easypoi.word.parse.ParseWord07;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import java.util.List;
import java.util.Map;
/**
* @author eleven
* @date 2024/1/23 10:17
* @apiNote
*/
public class MyWordExportUtil {
private MyWordExportUtil() {
}
/**
* 解析Word2007版本
*
* @param url
* 模板地址
* @param map
* 解析数据源
* @return
*/
public static XWPFDocument exportWord07(String url, Map<String, Object> map) throws Exception {
return new MyParseWord07().parseWord(url, map);
}
/**
* 解析Word2007版本
*
* @param document
* 模板
* @param map
* 解析数据源
*/
public static void exportWord07(XWPFDocument document,
Map<String, Object> map) throws Exception {
new ParseWord07().parseWord(document, map);
}
/**
* 一个模板生成多页
* @param url
* @param list
* @return
* @throws Exception
*/
public static XWPFDocument exportWord07(String url, List<Map<String, Object>> list) throws Exception {
return new ParseWord07().parseWord(url, list);
}
}
- 修改第三步的代码
public class WordUtil {
/**
*
* @param templatePath /template/test2.docx
* @param fileName 导出的文件名
* @param reportInfoMap 模板Map
* @param response 客户端响应
*/
public static void exportWordWithTemplate(String templatePath, String fileName, Map reportInfoMap, HttpServletResponse response) {
try (ServletOutputStream outputStream = response.getOutputStream()) {
//获取模板文档
XWPFDocument afterDoc = MyWordExportUtil.exportWord07(templatePath, reportInfoMap);
// 这个自己发挥好吧,都差不多的,
setResponseHeader(response, fileName);
//setTableFont(afterDoc);
afterDoc.write(outputStream);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
3. 修改xml
1. 这个真不会啊
到了这里,关于使用原生POI和EasyPoi根据word模板导出word工具类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!