一个问题出现了,我们首先要描述这个问题,然后分析问题出现的原因,找到原因后提出解决方案。废话不多说,直接上定义,然后通过回归和分类任务的例子来做解释。
一、什么是欠拟合和过拟合?
(1)欠拟合的定义
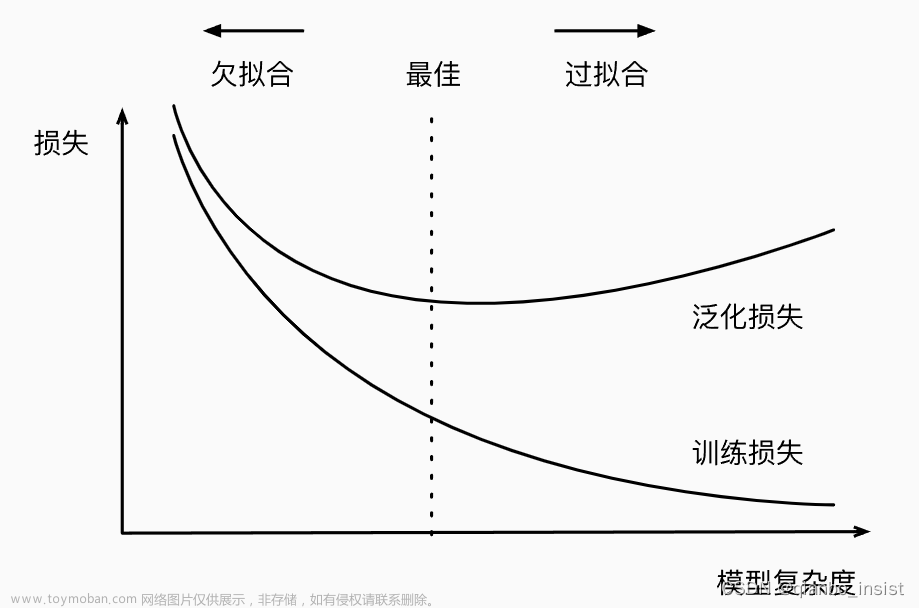
欠拟合(Underfitting)指的是模型在训练过程中未能捕捉到数据集中的有效规律或模式,导致模型过于简单,无法正确预测结果。

(2)过拟合的定义
拟合(Overfitting)是指模型在训练集上表现很好,但在测试集(未见过的数据)上性能表现很差。也就是说,模型“过度学习”了训练数据,把数据中的噪声也学习了进来,导致它失去了对未来数据的预测能力。

(3)良好拟合的定义
良好拟合指的是模型在训练集上有较低的误差,同时在测试集上也有很好的表现。也就是说,模型既没有过度地学习训练数据中的噪声,也成功捕获了数据的规律或模式,以至于能进行准确的预测。这就需要在模型的复杂性和简单性之间找到一个恰当的平衡。
 文章来源:https://www.toymoban.com/news/detail-823547.html
文章来源:https://www.toymoban.com/news/detail-823547.html
注:噪声(这里只说在输入数据中)就是一些无法对你要解决的任务比如回归任务起作用的输入值,它是数据误差或异常值。文章来源地址https://www.toymoban.com/news/detail-823547.html
二、造成欠拟合与过拟合的可能原因?
(1)造成欠拟合的可能原因
- 模型过于简单:模型结构过于简单,例如线性模型对于复杂非线性数据的拟合,模型就可能无法捕获到数据中的所有关系
- 特征选择不当:学习算法的复杂度不足,例如特征无法很好地代表预测的目标变量,或者特征数量太少
- 训练时间不足:如果模型的训练时间不足,或者训练步骤太少,那么模型可能还没有足够的机会“学习”到数据中的规律
- 学习率设置不合理:导致模型没有充分学习数据集的特性
(2)造成过拟合的可能原因
- 模型过于复杂:模型的复杂度远高于数据本身的复杂度,模型可能会“学习”到数据中的噪声,而没有捕获到真正的规律
- 训练数据量不足:训练数据量相对模型复杂度过小,使得模型有机会过度学习训练数据中的噪声或特殊情况
- 数据噪声过大:模型可能会错误地将这些噪声视为有效的信号进行学习
三、怎么解决欠拟合与过拟合问题?
(1)解决欠拟合问题的方法
- 增加模型复杂度:用更多的特征量和参数去构建模型
- 增加新特征:通过特征工程构建更多有意义的特征,增强模型对数据的表达能力
- 增大学习率:适当提高学习率,让模型更快地遍历参数空间,寻找更好的拟合效果
(2)解决过拟合问题的方法
- 增加训练样本:这有助于模型的泛化能力,并且可以防止模型记住所有单个样本
- 进行特征选择:只选择最合适的特征进行训练,但缺点是模型选择性的丢失了训练集的细节
- 正则化:如L1或L2正则化,可以惩罚模型中大的参数值,限制模型的复杂度的同时又保证具有训练集的所以细节
到了这里,关于【机器学习300问】17、什么是欠拟合和过拟合?怎么解决欠拟合与过拟合?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!