scrapy项目创建与启动
创建项目
在你的工作目录下直接使用命令:
scrapy startproject scrapytutorial
运行后创建了一个名为scrapytutorial的爬虫工程
创建spider
在爬虫工程文件内,运行以下命令:
scrapy genspider quotes
创建了名为quotes的爬虫
修改爬虫代码,实现自己想要的爬虫逻辑
启动爬虫
在爬虫项目目录下,运行:
scrapy crawl quotes
即可运行爬虫
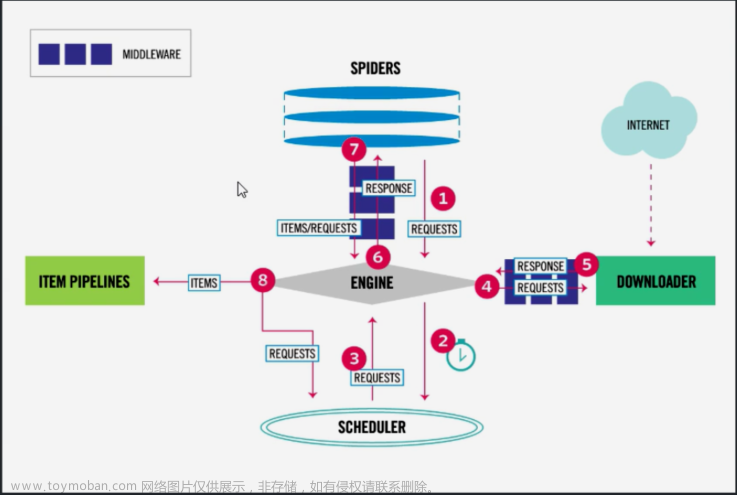
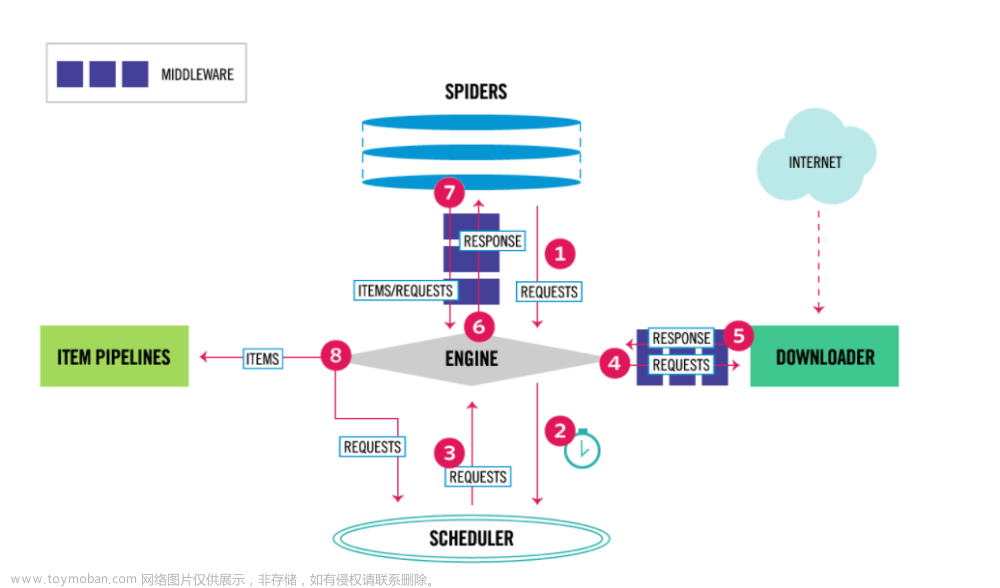
Spider
在scrapy中,网站的链接配置,抓取逻辑,解析逻辑都是在spider内配置。

start_requests
分析以下简单的爬虫代码:
import scrapy
class HttpbinspiderSpider(scrapy.Spider):
# 定义 Spider 的名称
name = "httpbinspider"
# 设置允许爬取的域名
allowed_domains = ["www.httpbin.org"]
# 定义起始 URL
start_uri = 'https://www.httpbin.org/get'
# 定义 Spider 的起始请求
def start_requests(self):
# 使用循环生成多个请求,这里生成了 1 到 5 的 offset 参数
for offset in range(1, 6):
url = self.start_uri + f'?offset={offset}'
# 生成请求,并指定回调函数为 parse
# 同时将 offset 通过 meta 传递给回调函数
yield scrapy.Request(url, callback=self.parse, meta={'offset': offset})
# 定义数据处理逻辑
def parse(self, response):
# 打印 offset 和响应文本
print(f"===============offset {response.meta['offset']}=========")
print(response.text)
# 打印 meta 数据,这里包含了在 start_requests 中传递的 offset
print(response.meta)
这里我重写了start_requests方法,使用scrapy.Request构造了5个GET请求,并使用yield方法发送到下载器用于下载,同时指定了响应的解析回调函数,并通过meta参数传递offset参数。
简要说明:
name:定义 Spider 的名称。
allowed_domains:定义允许爬取的域名。
start_uri:定义起始 URL。
start_requests:生成起始请求,使用循环生成多个带有不同 offset 参数的请求,每个请求的回调函数是 parse。
parse:处理响应的回调函数,打印 offset、响应文本和 meta 数据。
spider发送GET请求
使用scrapy.Request(url=url)
或 scrapy.Request(method=‘GET’,url=url)
发送GET请求,查询参数建议拼接在url内。文章来源:https://www.toymoban.com/news/detail-823611.html
spider发送POST请求
 文章来源地址https://www.toymoban.com/news/detail-823611.html
文章来源地址https://www.toymoban.com/news/detail-823611.html
到了这里,关于scrapy框架核心知识Spider,Middleware,Item Pipeline,scrapy项目创建与启动,Scrapy-redis与分布式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[爬虫]3.4.1 Scrapy框架的基本使用](https://imgs.yssmx.com/Uploads/2024/02/598070-1.jpg)



