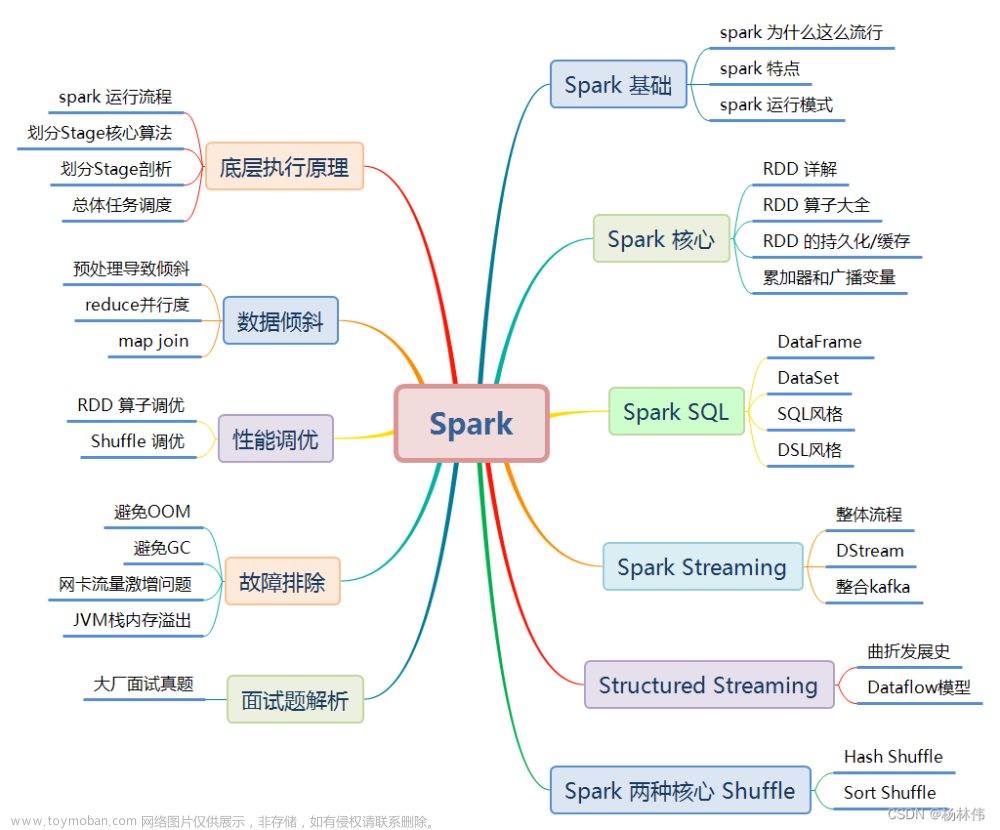
大数据处理已成为当代数据领域的重要课题之一。为了高效地处理和分析大规模数据集,许多大数据处理引擎应运而生。其中,Spark作为一个快速、通用的大数据处理引擎备受关注。
本文将从“是什么、怎么用、为什么用”三个角度来介绍Spark。首先,我们会详细探讨Spark的基本概念和主要特点,让读者对Spark有一个清晰的认识。接着,我们将介绍Spark的使用方法,包括编程语言和API、运行环境等方面的内容。最后,我们会深入探讨为什么选择Spark作为大数据处理工具的原因,以及它相对于传统的批处理系统的优势。
通过本文的阅读,读者将能够了解Spark的基本原理和功能,掌握Spark的使用方法,同时也能够了解Spark相对于其他大数据处理引擎的优势。希望本文能够为读者提供一个全面而简明的Spark介绍,帮助读者更好地理解和应用Spark在大数据处理领域的重要性。
让我们一起深入探索Spark的世界吧!
是什么
Spark是一个快速、通用的大数据处理引擎,旨在提供高效的分布式数据处理和分析能力。Spark能够处理大规模数据集并利用集群计算能力进行并行计算,同时还提供了丰富的库和工具,支持多种数据处理任务和应用场景。
Spark的一个主要特点是其内存计算能力,可以将数据存储在内存中并进行高速计算,从而大大加快数据处理速度。与传统的批处理系统相比,Spark能够实现更低的延迟和更高的吞吐量。此外,Spark还支持流式计算、机器学习、图处理等多种数据处理模式,使其成为一个强大的大数据处理平台。
怎么用
Spark提供了丰富的API和命令行工具,方便用户进行数据处理和分析。用户可以使用Scala、Java、Python和R等多种编程语言来编写Spark应用程序。Spark还提供了交互式Shell,可以快速进行数据探索和原型验证。
Spark的核心概念是Resilient Distributed Datasets (RDDs),它是一个可分区、可并行处理的数据集合。用户可以通过对RDD进行转换操作(如map、filter、reduce等)来构建数据处理流程,并通过调用action操作(如count、collect、save等)触发计算。Spark还提供了丰富的库和工具,如Spark SQL、Spark Streaming、MLlib和GraphX等,可以满足各种不同的数据处理需要。
用户可以通过本地模式或者在分布式集群上运行Spark应用程序。Spark支持各种集群管理器,如Hadoop YARN、Apache Mesos和Standalone等,在不同的环境中都可以方便地部署和运行。
为什么用
Spark之所以受到广泛关注和应用,是因为它具有以下几个优势:
-
快速性能:Spark能够将数据存储在内存中进行高速计算,大大提高了数据处理速度。它还通过使用弹性数据集和高级调度器等技术来优化计算性能。
-
灵活性:Spark提供了丰富的库和工具,支持多种数据处理模式和应用场景。无论是批处理、流式计算、机器学习还是图处理,都可以在Spark上进行方便、灵活的开发。
-
易用性:Spark提供了简洁而强大的API和工具,易于学习和使用。它还支持多种编程语言和交互式Shell,方便用户进行快速原型验证和数据探索。
-
可扩展性:Spark可以在各种分布式集群上运行,支持水平扩展和自动容错。它还提供了各种调优选项和配置参数,以满足不同规模和需求的数据处理任务。
综上所述,Spark作为一种快速、通用的大数据处理引擎,具有高性能、灵活性、易用性和可扩展性等优势,成为大数据处理和分析的首选工具。
总结
Spark是一个快速、通用的大数据处理引擎,通过内存计算和丰富的库和工具,提供了高效的分布式数据处理和分析能力。用户可以使用多种编程语言和API来开发Spark应用程序,并在各种分布式集群上运行。Spark具有快速性能、灵活性、易用性和可扩展性等优势,使其成为大数据处理和分析的首选工具。文章来源:https://www.toymoban.com/news/detail-823680.html
希望通过本文的介绍,读者能够对Spark有一个基本的了解,并在实际应用中发挥其强大的数据处理能力。# Spark介绍
是什么
Spark是一个快速、通用的大数据处理引擎,旨在提供高效的分布式数据处理和分析能力。Spark能够处理大规模数据集并利用集群计算能力进行并行计算,同时还提供了丰富的库和工具,支持多种数据处理任务和应用场景。
Spark的一个主要特点是其内存计算能力,可以将数据存储在内存中并进行高速计算,从而大大加快数据处理速度。与传统的批处理系统相比,Spark能够实现更低的延迟和更高的吞吐量。此外,Spark还支持流式计算、机器学习、图处理等多种数据处理模式,使其成为一个强大的大数据处理平台。
怎么用
Spark提供了丰富的API和命令行工具,方便用户进行数据处理和分析。用户可以使用Scala、Java、Python和R等多种编程语言来编写Spark应用程序。Spark还提供了交互式Shell,可以快速进行数据探索和原型验证。
Spark的核心概念是Resilient Distributed Datasets (RDDs),它是一个可分区、可并行处理的数据集合。用户可以通过对RDD进行转换操作(如map、filter、reduce等)来构建数据处理流程,并通过调用action操作(如count、collect、save等)触发计算。Spark还提供了丰富的库和工具,如Spark SQL、Spark Streaming、MLlib和GraphX等,可以满足各种不同的数据处理需要。
用户可以通过本地模式或者在分布式集群上运行Spark应用程序。Spark支持各种集群管理器,如Hadoop YARN、Apache Mesos和Standalone等,在不同的环境中都可以方便地部署和运行。
为什么用
Spark之所以受到广泛关注和应用,是因为它具有以下几个优势:
-
快速性能:Spark能够将数据存储在内存中进行高速计算,大大提高了数据处理速度。它还通过使用弹性数据集和高级调度器等技术来优化计算性能。
-
灵活性:Spark提供了丰富的库和工具,支持多种数据处理模式和应用场景。无论是批处理、流式计算、机器学习还是图处理,都可以在Spark上进行方便、灵活的开发。
-
易用性:Spark提供了简洁而强大的API和工具,易于学习和使用。它还支持多种编程语言和交互式Shell,方便用户进行快速原型验证和数据探索。
-
可扩展性:Spark可以在各种分布式集群上运行,支持水平扩展和自动容错。它还提供了各种调优选项和配置参数,以满足不同规模和需求的数据处理任务。
综上所述,Spark作为一种快速、通用的大数据处理引擎,具有高性能、灵活性、易用性和可扩展性等优势,成为大数据处理和分析的首选工具。
总结
Spark是一个快速、通用的大数据处理引擎,通过内存计算和丰富的库和工具,提供了高效的分布式数据处理和分析能力。用户可以使用多种编程语言和API来开发Spark应用程序,并在各种分布式集群上运行。Spark具有快速性能、灵活性、易用性和可扩展性等优势,使其成为大数据处理和分析的首选工具。
希望通过本文的介绍,读者能够对Spark有一个基本的了解,并在实际应用中发挥其强大的数据处理能力。文章来源地址https://www.toymoban.com/news/detail-823680.html
到了这里,关于[AIGC大数据基础] Spark 入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!