一、概述
定义
1、Kafka传统定义:Kafka 是一个分布式的基于 发布/订阅模式 的消息队列(Message Queue) ,主要应用与大数据实时处理领域。
2、发布/订阅:消息的发送者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接受自己感兴趣的消息。
3、Kafka 最新定义:Kafka是一个开源的 分布式事件流平台 (Event Streaming Platfrom),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
消息队列的应用场景
传统的消息队列主要应用场景包括: 缓存/削峰、解耦和异步通信。
缓存/削峰
所有数据可以全部缓存到消息队列,服务器可以根据自己处理的性能按一定的频率去消息队列中取。
解耦
减少服务之间的直接调用,由消息队列充当中间者。
异步通信
一个业务可以将优化体验(发短信)的动作放到消息队列中,由专门的服务去处理,达到快速响应上游。
消息队列的俩种模式
1)点对点模式
消费者主动拉取数据,消息收到后清除数据。

2)发布/订阅模式
- 一个队列可以有多个topic主题。(topic对消息进行分类,消费者可以自己需求拿消息)
- 消费者消费数据之后,不删除数据。
- 每个消费者相互独立,都可以拿到消费数据。

Kafka的基础架构
1、为方便扩展,并提高吞吐量,一个 Topic 分为多个 partition(分区)
2、配合分区的设计,提出了消费者组的概念,组内每个消费者并行消费,一个分区只能让一个消费者消费。
3、为了提高可用性,为每个 partition 增加诺干副本进行备份(分为leader 和 follower)消费者只找learder,当leader挂掉的时候,follower符合条件时会变成leader。
4、zookerper存储节点信息,有哪些副本。

二、入门
Kafka的基本命令
Topic命令
- 查看有多少主题
kafka-topics.sh --bootstrap-server 192.168.204.10:9092,192.168.204.10:9093 --list- 新增主题
kafka-topics.sh --bootstrap-server 192.168.204.10:9092,192.168.204.10:9093 --topic first --create --partitions 1 --replication-factor 3- 查看主题详情
kafka-topics.sh --bootstrap-server 192.168.204.10:9092,192.168.204.10:9093 --topic first --describe - 修改主题
只能加不能减
kafka-topics.sh --bootstrap-server 192.168.204.10:9092,192.168.204.10:9093 --topic first --alter --partitions 3
命令行操作
- 创建一个生产者
kafka-console-producer.sh --bootstrap-server 192.168.204.10:9092 --topic second
- 创建一个消费者
kafka-console-consumer.sh --bootstrap-server 192.168.204.10:9092 --topic second
可以查看到历史数据
kafka-console-consumer.sh --bootstrap-server 192.168.204.10:9092 --topic second --from-beginning三、生产者
原理
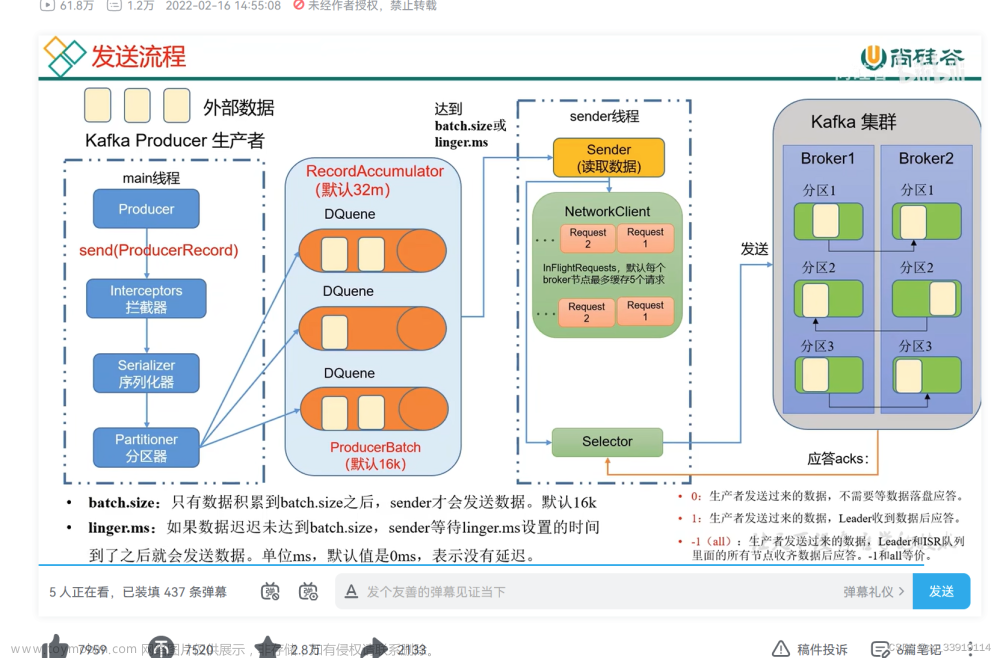
在消息发送的过程中,涉及到了俩个线程 -- main 和 Sender。在main线程中创建了 一个双端队列 RecordAccumulator 。main线程将消息发送给RecordAccumulator ,Sender 线程不断从RecordAccumulator 中拉取消息发送给Kafka Broker。

异步发送
当main线程发送到RecordAccumulator之后就结束了,不管接下去的操作。
示例代码:
//配置参数
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.204.10:9092,192.168.204.10:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//创建KafkaProducer
KafkaProducer<String, Object> kafkaProducer = new KafkaProducer<>(properties);
kafkaProducer.send(new ProducerRecord<>("second","hello"));
//释放资源
kafkaProducer.close();回调异步发送
相对于异步发送,就是多了一个发送成功之后处理的函数。
示例代码:
//配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.204.10:9092,192.168.204.10:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//创客KafkaProducer
KafkaProducer<String, Object> kafkaProducer = new KafkaProducer<>(properties);
kafkaProducer.send(new ProducerRecord<>("second", "hello"), (recordMetadata, e) -> {
System.out.println(recordMetadata.toString());
System.out.println("send success");
});
//释放资源
kafkaProducer.close();同步发送
同步发送就是main线程需要等sender线程将双端队列中的数据发送出去才能继续往下面操作。
示例代码:
//配置参数
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.204.10:9092,192.168.204.10:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//创建KafkaProducer
KafkaProducer<String, Object> kafkaProducer = new KafkaProducer<>(properties);
try {
kafkaProducer.send(new ProducerRecord<>("second","hello")).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//释放资源
kafkaProducer.close();分区
Kafka分区好处
1、便于合理使用存储资源,每个Partition 在一个Broker上存储,可以把海量数据按照分区切割成一块一块存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
2、提高并行度,生产者可以以分区为单位发送数;消费者可以以分区为单位进行消费数据。
分区策略

自定义分区器
1、定义自己的分区器
package cn.swj.kafka;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* @Author suweijie
* @Date 2023/8/30 21:40
* @Description: TODO
* @Version 1.0
*/
public class MyPartitioner implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
String msg = o1.toString();
if(msg.contains("suweijie")) {
return 1;
}
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
2、添加配置
//配置参数
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.204.10:9092,192.168.204.10:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyPartitioner.class.getName())
//创建KafkaProducer
KafkaProducer<String, Object> kafkaProducer = new KafkaProducer<>(properties);
try {
kafkaProducer.send(new ProducerRecord<>("second","hello")).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//释放资源
kafkaProducer.close();提高生产者的吞吐量

batch.size: 批次的大小默认是16k(16384b) ,但是这个参数要跟linger.ms 配合才有用
linger.ms: 等待时间,修改为 5-100ms ,修改这个会造成数据的延迟。
RecordAccumulator: 双端队列的缓存区大小,修改为64m (33554432b)
compression.type : 压缩snappy, none(默认)、gzip、snappy(用的比较多)、lz4、zstd
最佳实践:
batch.size = 32768
linger.ms = 5
buffer.memory = 33554432
compression.type = snappy数据可靠性
应答ACKS
- 0: 生产者发过来的数据,不需要等待数据落盘应答。
- 1: 生产者发过来的数据,需要等待Leader收到之后应答。
- -1(all): 生产者发过来的数据,需要等Leader+ 和 isr 队列里面所有的节点收齐数据后应答。-1 和 all等价。
-



spring:
kafka:
bootstrap-servers: 192.168.204.10:9092,192.168.204.10:9093,192.168.204.10:9094
consumer:
group-id: 1
value-deserializer: org.apache.kafka.common.serialization.StringSerializer
key-deserializer: org.apache.kafka.common.serialization.StringSerializer
producer:
acks: -1 #ack机制 0 1 -1
batch-size: 32768 #批次大小
value-serializer: org.apache.kafka.common.serialization.StringSerializer
key-serializer: org.apache.kafka.common.serialization.StringSerializer
compression-type: snappy #数据压缩
retries: 5 #重试次数
buffer-memory: 33554432 #双端队列的缓冲区大小
linger-ms: 5 # sender 等待时间
数据重复
幂等性特性


配置:
enable:
idempotence: true #开启幂等性 默认开启但是Kafka挂掉之后会重新生成一个PID,所以也是有可能会产生重复数据。
生产者事务
开启事务、必须得开启幂等性

示例代码:
private void transaction() {
//配置参数
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.204.10:9092,192.168.204.10:9093");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.LINGER_MS_CONFIG,5); //sender 发送的等待时间 ,当达到这个时间的时候Sender 会直接发
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); //开启幂等性,默认开启
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); //设置双端队列的大小 64m
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,32768); //批次的大小 32k ,当批次达到这个大小的时候,Sender会直接发送
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy"); //数据的压缩方式
properties.put(ProducerConfig.RETRIES_CONFIG,5); //发送失败的重试次数
properties.put(ProducerConfig.ACKS_CONFIG,-1); // acks的方式 -1 当leader 收到并且和isr 队列里面所有的节点同步才应答。
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"123"); //事务唯一id
//自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyPartitioner.class.getName());
//创建KafkaProducer
KafkaProducer<String, Object> kafkaProducer = new KafkaProducer<>(properties);
kafkaProducer.initTransactions(); //初始化事务
kafkaProducer.beginTransaction(); //开启事务
try {
kafkaProducer.send(new ProducerRecord<>("second","hello"));
kafkaProducer.commitTransaction(); //事务
} catch (Exception e) {
e.printStackTrace();
kafkaProducer.abortTransaction();
}
//释放资源
kafkaProducer.close();
}数据有序
同分区内消费者可以实现数据的有序消费,不同分区内消费者如何实现有序消费?TODO
数据乱序问题
产生的原因:
1、默认 broker 最多缓存5个请求
2、当sender一直在发送数据的时候,当有一条数据发送失败需要返回双端队列进行重发,就会产生数据乱序的问题。
解决方案:
1) kafka 在 1.x 版本之前确保单分区下数据有序需要增加以下配置:
max.in.flight.requests.per.connection = 11) kafka在 1.x 以及之后的版本确保单分区下的额数据有序,条件如下:
(1) 未开启幂等性
max.in.flight.requests.per.connection 设置为1
(2)开启幂等性
max.in.flight.requests.per.connection 设置小于5
原理:在kafka1.x 版本以后,启用幂等性后,kafka broker 会缓存producer 发来的最近5个request 的元数据,如果数据乱序会将乱序的数据保存在内存中,重新排序之后在落盘。

四、Broker
ZK存储

启动zkCli.sh:
docker exec -it zookeeper-server bash
#进入之后启动zkCli.sh
bin/zkCli.sh
ls /brokers/ids
get /brokers/topics/second/partitions/0/state
get /controller/brokes/ids : 记录有哪些节点
/brokers/topics/主题/patitions/0/state : 记录着leader、isr队列
/controller : 辅助选举leader
Broker工作原理

AR: kafka 分区中所有的副本统称
工作流程:
1) broker 启动会在zk中注册
2) controller 谁注册,谁说了算
3) 由选举出来的controller 监听 brokers 节点变化
4) Controller 决定 Leader 的选举
选举规则:
在isr队列中存活为前提,安装ARa中排在最前面的优先。例如 ar[1,0,2]、isr[1,0,2],那么leader 就会按照1,0,2的顺序轮询。
5) 主broker的Controller,会将所有节点的信息上传到zk
6) 其他节点的controller 会去从zk同步相关信息下来。
7) 假设broker挂了
8) 监听到broker节点变化
9) 获取isr
10) 选举新的leader
11) 更新leader 以及 isr
新节点的服役以及退役(没听懂)
新节点服役
docker run -d --name kafka3 \
--network kafka-net \
-p 9095:9095 \
-e KAFKA_BROKER_ID=3 \
-e KAFKA_ZOOKEEPER_CONNECT=zookeeper-server:2181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.204.10:9095 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9095 \
-e TZ="Asia/Shanghai" \
wurstmeister/kafka:latest查看在新节点是否有主题信息(指定这台broker的地址,查看是否有主题信息)
kafka-topics.sh --bootstrap-server 192.168.204.10:9094 --topic first --describe 服役新节点、正确退役旧节点
五、Kafka 副本
基本信息
1)Kafka 副本作用: 提高数据的可靠性。
2)Kafka默认的副本数为1,生产环境正常配置俩个,保证数据的可靠性;太多副本会增加磁盘的存储空间,增加网络上数据传输,降低效率。
3)Kafka 中副本分为: Leader 和 Follower。Kafka生产者只会把数据发送到Leader,然后Follower 自己去找Leader 同步。
4)Kafka 分区中的所有副本统称为AR(Assigned Replicas)。
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出ISR。该时间闽值由 replica.lagtime.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。
Leader的选举流程

Follower的故障
 文章来源:https://www.toymoban.com/news/detail-823911.html
文章来源:https://www.toymoban.com/news/detail-823911.html
Leader的故障
 文章来源地址https://www.toymoban.com/news/detail-823911.html
文章来源地址https://www.toymoban.com/news/detail-823911.html
到了这里,关于学习笔记 | Kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!