大模型部署背景
部署:将训练好的模型在特定软硬件环境中启动的过程
挑战:存储问题
LMDeploy简介
针对英伟达平台
量化可以节省显存,提升推理速度
访问数据占用了大量时间
有一部分很重要的参数不量化,保留性能。其余部分量化节约显存
动手实践
安装、部署、量化
创建环境
/root/share/install_conda_env_internlm_base.sh lmdeploy


安装lmdeploy
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
pip install 'lmdeploy[all]==v0.1.0'
服务部署
在线转换
可以直接加载 Huggingface 模型
直接启动本地的 Huggingface 模型
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b
可以在bash中对话
离线转换
需要先保存模型再加载
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/

模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace

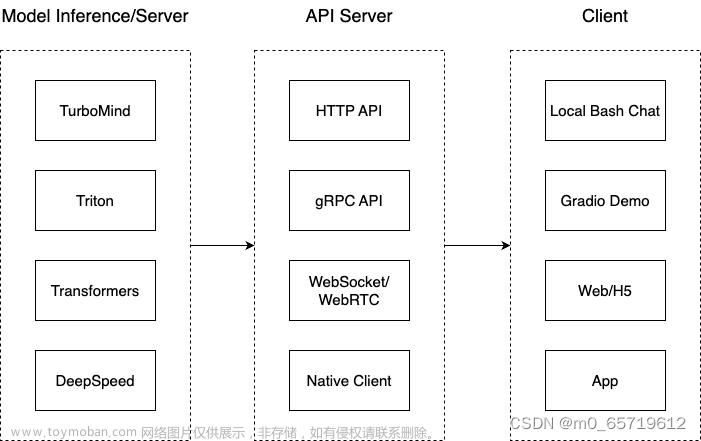
TurboMind推理+API服务
在上面的部分我们尝试了直接用命令行启动 Client,接下来我们尝试如何运用 lmdepoy 进行服务化
”模型推理/服务“目前提供了 Turbomind 和 TritonServer 两种服务化方式。
首先,通过下面命令启动服务。
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1

新开一个窗口,执行下面的 Client 命令。如果使用官方机器,可以打开 vscode 的 Terminal,执行下面的命令。
# ChatApiClient+ApiServer(注意是http协议,需要加http)
lmdeploy serve api_client http://localhost:23333

本地使用SSH连接,并打开 http://localhost:23333/


Gradio 作为前端 Demo演示
TurboMind 服务作为后端
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True
TurboMind 推理作为后端
Gradio 也可以直接和 TurboMind 连接,如下所示
# Gradio+Turbomind(local)
lmdeploy serve gradio ./workspace
打开http://localhost:6006/
作业
-
本地对话方式,生成300字小故事

-
API 方式,生成300字小故事

 文章来源:https://www.toymoban.com/news/detail-823977.html
文章来源:https://www.toymoban.com/news/detail-823977.html -
网页Gradio方式, 生成300字小故事
 文章来源地址https://www.toymoban.com/news/detail-823977.html
文章来源地址https://www.toymoban.com/news/detail-823977.html
到了这里,关于书生·浦语大模型--第五节课笔记&作业--LMDeploy 大模型量化部署实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!