1. 参考
- ChatGLM2-6B代码地址
- chatglm2-6b模型地址
- Mac M1芯片部署
2. ChatGLM2-6B 介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能。
- 更长的上下文。
- 更高效的推理。
- 更开放的协议。
详细介绍参考官方README介绍。
3. 本地运行
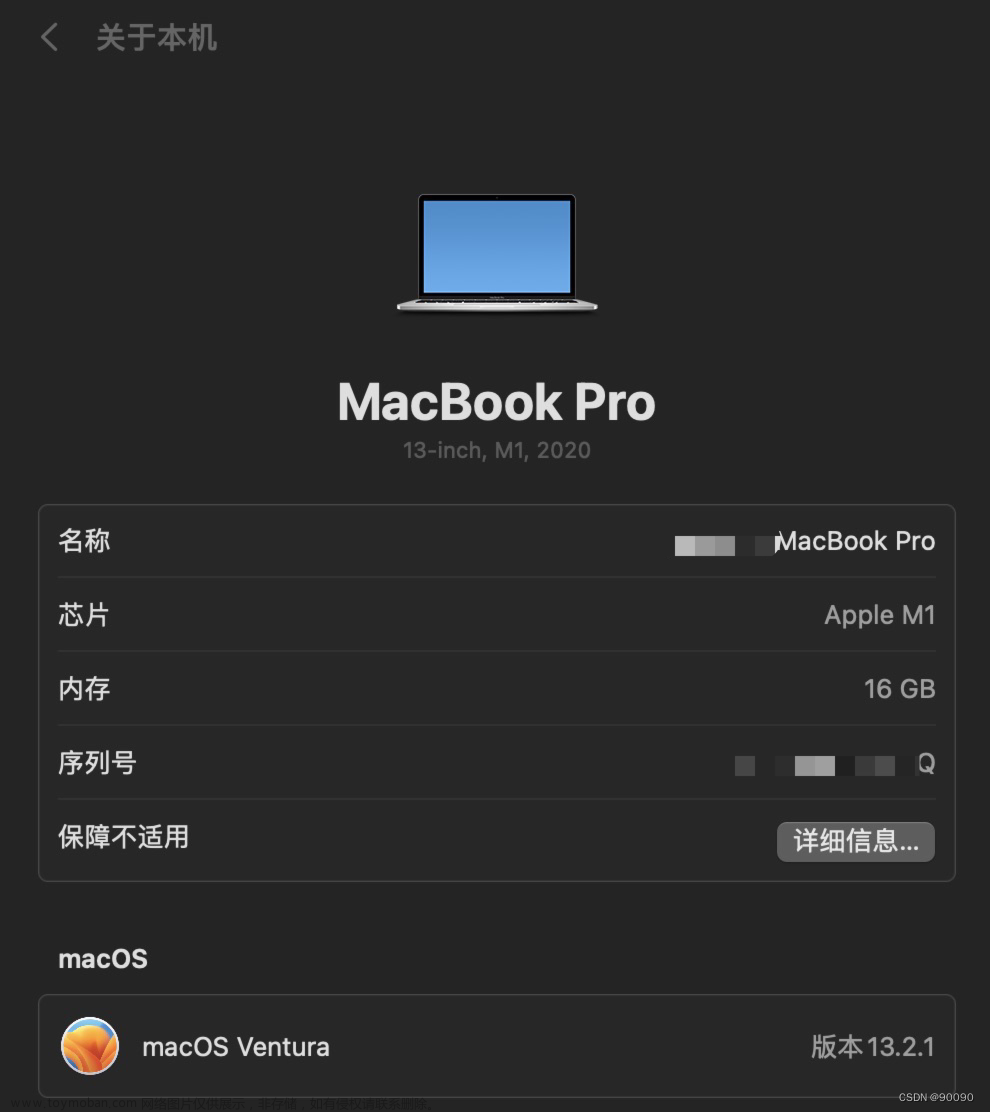
3.1 硬件配置
- 芯片:Apple M1 Pro
- 内存:32 GB
3.2 下载ChatGLM2-6B代码
cd /Users/joseph.wang/llm
git clone https://github.com/THUDM/ChatGLM2-6B
3.3 下载需要加载的模型
此步骤下载模型需要科学上网,同时需要耐心,因为下载的时间会比较长。
cd /Users/joseph.wang/llm/ChatGLM-6B
mkdir model
cd model
git lfs install
git clone https://huggingface.co/THUDM/chatglm2-6b

3.4 运行大模型
3.4.1 安装依赖
cd /Users/joseph.wang/llm/ChatGLM-6B
pip install -r requirements.txt
其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
3.4.2 编辑web_demo.py
cd /Users/joseph.wang/llm/ChatGLM-6B
...
...
# 修改为通过本地加载大模型,这里改本地下载后大模型的路径即可。
tokenizer = AutoTokenizer.from_pretrained("/Users/joseph.wang/llm/ChatGLM-6B/model/chatglm2-6b", trust_remote_code=True)
# 参考 [Mac M1 部署](https://github.com/THUDM/ChatGLM2-6B/blob/main/README.md#mac-%E9%83%A8%E7%BD%B2) 即可
model = AutoModel.from_pretrained("/Users/joseph.wang/llm/ChatGLM-6B/model/chatglm2-6b", trust_remote_code=True).to('mps')
...
...
# 修改本地启动的端口
demo.queue().launch(share=True, inbrowser=True, server_port=1185)
3.4.3 启动
python web_demo.py

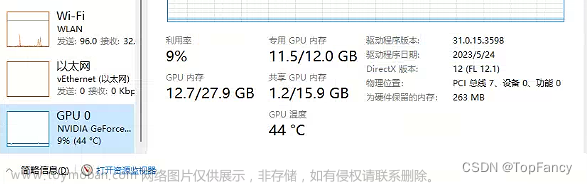
内存消耗 文章来源:https://www.toymoban.com/news/detail-824014.html
文章来源:https://www.toymoban.com/news/detail-824014.html
4. 测试

 文章来源地址https://www.toymoban.com/news/detail-824014.html
文章来源地址https://www.toymoban.com/news/detail-824014.html
到了这里,关于基于MacBook Pro M1芯片运行chatglm2-6b大模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!