-
将PDF转换为Word:
- 使用pdf2docx库中的Converter类来进行PDF转换。
-
convert_pdf_to_docx函数接受PDF文件路径和输出的Word文档路径作为参数。 - 通过调用Converter对象的
convert方法将PDF转换为Docx格式。 - 最后调用
close方法关闭Converter对象并保存转换后的文档。
-
将Word转换为Excel:
- 使用docx库打开Word文档。
- 创建一个新的Excel文件。
- 遍历Word文档中的表格,逐行读取表格内容,并将其写入Excel文件。
- 使用openpyxl库保存Excel文件。
-
替换Excel中的数据:
- 使用openpyxl库加载输入的Excel文件。
- 获取原始数据,并复制一份用于替换。
- 遍历替换数据的范围,更新特定位置的数据。
- 创建新的Excel文件,更新数据并保存。
-
将Excel转换为Word:
- 遍历输入文件夹下的所有Excel文件。
- 为每个Excel文件创建一个新的Word文档。
- 打开Excel文件并获取活动工作表。
- 在Word文档中创建一个表格,并将Excel单元格数据写入表格。
- 调整表格样式和单元格样式,并保存Word文档。
-
将Word转换为PDF:
- 使用docx2pdf库的convert函数将Word文档转换为PDF。
- 遍历输入文件夹下的所有Word文件,并将其转换为PDF格式。
- 流程步骤
①初始pdf
②变成word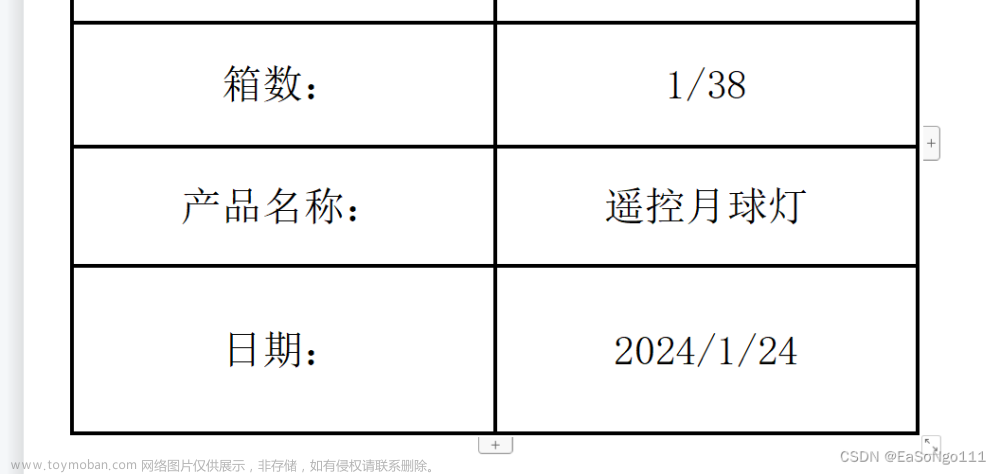
③变成excel
④批量处理更换
⑤转成word 文章来源:https://www.toymoban.com/news/detail-824225.html
文章来源:https://www.toymoban.com/news/detail-824225.html
⑥转成pdf 文章来源地址https://www.toymoban.com/news/detail-824225.html
文章来源地址https://www.toymoban.com/news/detail-824225.html
#pdf 转 word
from pdf2docx import Converter
def convert_pdf_to_docx(pdf_path, docx_path):
cv = Converter(pdf_path)
cv.convert(docx_path, start=0, end=None)
cv.close()
if __name__ == '__main__':
pdf_path = 'C:/Users/wangkejun/Desktop/1/结果1.pdf' # 输入的 PDF 文件路径
docx_path = 'C:/Users/wangkejun/Desktop/1/结果2.docx' # 输出的 Word 文档路径
convert_pdf_to_docx(pdf_path, docx_path)
print('转换完成!')
# word 转 excel
import docx
from openpyxl import Workbook
# 打开 Word 文档
doc = docx.Document(r'C:/Users/wangkejun/Desktop/1/结果2.docx')
# 创建一个新的 Excel 文件
workbook = Workbook()
sheet = workbook.active
# 遍历 Word 文档中的表格
for table in doc.tables:
for row in table.rows:
# 按行遍历表格并将内容写入 Excel 文件
data = []
for cell in row.cells:
data.append(cell.text)
sheet.append(data)
# 保存 Excel 文件
workbook.save(r'C:/Users/wangkejun/Desktop/1/结果3.xlsx')
import os
from openpyxl import load_workbook
def replace_data_in_excel(input_file, output_folder):
# 加载输入的 Excel 表
wb = load_workbook(input_file)
sheet = wb.active
# 获取原始数据
data = []
for row in sheet.iter_rows(values_only=True):
data.append(list(row))
# 替换数据
for i in range(1, 39):
# 复制原始数据
new_data = [row[:] for row in data]
# 替换特定位置的数据
new_data[1][1] = f"{i}/38"
# 创建新的 Excel 表
new_wb = load_workbook(input_file)
new_sheet = new_wb.active
# 更新新的 Excel 表的数据
new_sheet.delete_rows(1, new_sheet.max_row)
for row in new_data:
new_sheet.append(row)
# 保存新的 Excel 表
output_file = os.path.join(output_folder, f"{i}.xlsx")
new_wb.save(output_file)
print("生成完成!")
if __name__ == '__main__':
input_file = r'C:/Users/wangkejun/Desktop/1/结果3.xlsx' # 输入的 Excel 表路径
output_folder = r'C:/Users/wangkejun/Desktop/1' # 输出的文件夹路径
replace_data_in_excel(input_file, output_folder)
#excel 转 word
import os
import openpyxl
from docx import Document
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT, WD_ALIGN_VERTICAL
def convert_excel_to_word(input_folder, output_folder):
# 遍历输入文件夹下的所有 Excel 文件
for file_name in os.listdir(input_folder):
if file_name.endswith('.xlsx') or file_name.endswith('.xls'):
# 构造输出文件路径
output_file = os.path.join(output_folder, f"{file_name.split('.')[0]}.docx")
# 创建一个新的 Word 文档
doc = Document()
# 打开 Excel 文件
file_path = os.path.join(input_folder, file_name)
workbook = openpyxl.load_workbook(file_path)
sheet = workbook.active
# 在 Word 文档中创建一个表格
table = doc.add_table(rows=1, cols=sheet.max_column)
table.autofit = False
# 设置表格样式
table.style = 'Table Grid'
# 将 Excel 单元格数据写入 Word 表格
for row in sheet.iter_rows(values_only=True):
new_row = table.add_row().cells
for i, cell_value in enumerate(row):
new_row[i].text = str(cell_value)
# 调整单元格样式
for row in table.rows:
for cell in row.cells:
cell.vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER
cell.paragraphs[0].paragraph_format.alignment = WD_ALIGN_VERTICAL.CENTER
# 保存 Word 文档
doc.save(output_file)
print("转换完成!")
if __name__ == '__main__':
input_folder = r'C:/Users/wangkejun/Desktop/1/excel' # 输入的文件夹路径
output_folder = r'C:/Users/wangkejun/Desktop/1/word' # 输出的 Word 文件夹路径
convert_excel_to_word(input_folder, output_folder)
# #word 转 pdf
from docx2pdf import convert
import os
def batch_word_to_pdf(input_folder, output_folder):
# 遍历输入文件夹下的所有 Word 文件
for file_name in os.listdir(input_folder):
if file_name.endswith('.docx'):
# 构造输出文件路径
output_file = os.path.join(output_folder, f"{file_name.split('.')[0]}.pdf")
# 调用 docx2pdf 库的 convert 函数将 Word 文档转换为 PDF
convert(os.path.join(input_folder, file_name), output_file)
print("转换完成!")
if __name__ == '__main__':
input_folder = r'C:/Users/wangkejun/Desktop/1/word' # 输入的文件夹路径
output_folder = r'C:/Users/wangkejun/Desktop/1/pdf' # 输出的 PDF 文件夹路径
batch_word_to_pdf(input_folder, output_folder)到了这里,关于python批量处理修改pdf内容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!