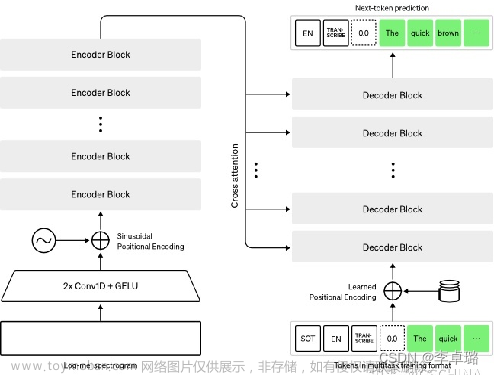
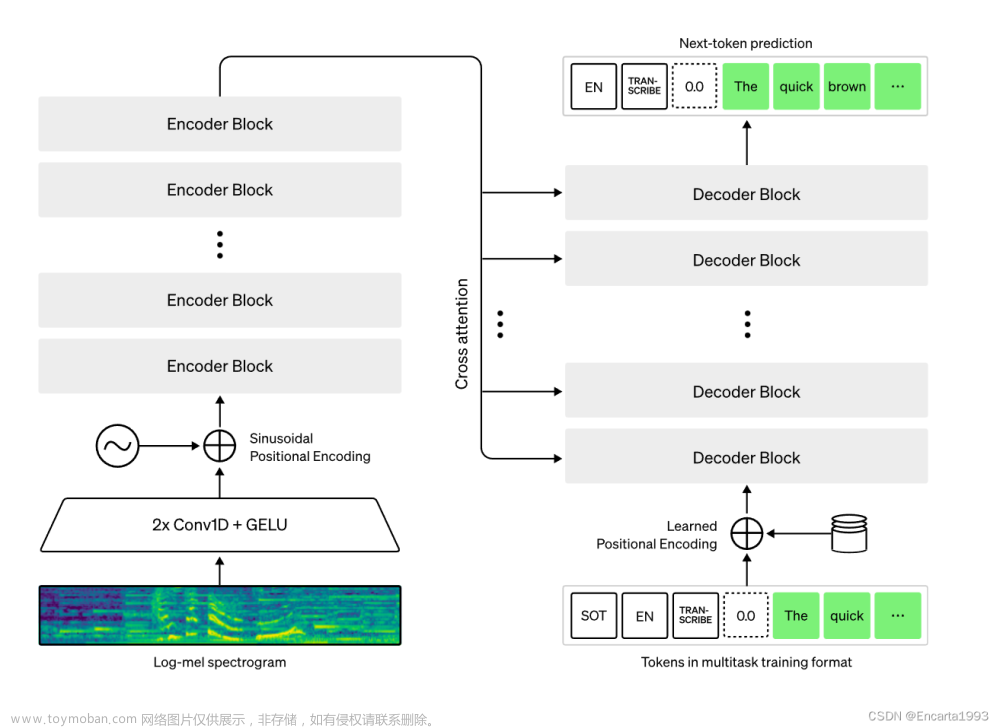
阿里的FunAsr对Whisper中文领域的转写能力造成了一定的挑战,但实际上,Whisper的使用者完全可以针对中文的语音做一些优化的措施,换句话说,Whisper的“默认”形态可能在中文领域斗不过FunAsr,但是经过中文特殊优化的Whisper就未必了。
中文文本标注优化
Whisper经常被人诟病的一点是对中文语音转写后标点符号的支持不够完备。首先安装whisper:
pip install -U openai-whisper
编写转写脚本:
import whisper
device = "cuda:0" if torch.cuda.is_available() else "cpu"
audio = whisper.load_audio(audio_path)
audio = whisper.pad_or_trim(audio)
model = whisper.load_model("large-v2",download_root="./whisper_model/")
mel = whisper.log_mel_spectrogram(audio).to(model.device)
options = whisper.DecodingOptions(beam_size=5)
result = whisper.decode(model, mel, options)
print(result.text)
程序返回:
Erwin_0.wav|Erwin|ZH|如果这个作战顺利。
Erwin_1.wav|Erwin|ZH|你也许可以趁此机会干掉狩之巨人
Erwin_10.wav|Erwin|ZH|如果到時候我不衝在最前面
Erwin_11.wav|Erwin|ZH|他们根本不会往前冲然后我会第一个去死
Erwin_12.wav|Erwin|ZH|地下室里到底有什么
Erwin_13.wav|Erwin|ZH|也就无从知晓了好想去地下室看一看我之所以能撑着走到今天
Erwin_14.wav|Erwin|ZH|就是因为相信这一天的到来。
Erwin_15.wav|Erwin|ZH|因为艰辛着
Erwin_16.wav|Erwin|ZH|我才想能够得到证实
Erwin_17.wav|Erwin|ZH|我之前無數次的想過,要不然乾脆死了算了。
Erwin_18.wav|Erwin|ZH|可即便如此,我還是想要實現父親的夢想。
Erwin_19.wav|Erwin|ZH|然而现在
Erwin_2.wav|Erwin|ZH|但得拿所有新兵不管選擇哪條路
Erwin_20.wav|Erwin|ZH|她的答案就在我触手可及的地方
Erwin_21.wav|Erwin|ZH|仅在咫尺死去的同伴们也是如此吗
Erwin_22.wav|Erwin|ZH|那些流血的棲身,都是沒有意義的嗎?
Erwin_23.wav|Erwin|ZH|不!不對!
Erwin_24.wav|Erwin|ZH|那些死去士兵的意义将由我们来赋予
Erwin_25.wav|Erwin|ZH|那些勇敢的死者可憐的死者
Erwin_26.wav|Erwin|ZH|是他们的牺牲换来了我们活着的今天
Erwin_27.wav|Erwin|ZH|让我们能站在这里否则今天我们将会死去
Erwin_28.wav|Erwin|ZH|将依依托福给下一个活着的人
Erwin_29.wav|Erwin|ZH|这就是我们与这个残酷的世界
Erwin_3.wav|Erwin|ZH|我们基本都会死吧是的全灭的可能性相当的高
Erwin_30.wav|Erwin|ZH|抗爭的意義
Erwin_4.wav|Erwin|ZH|但事到如今,也只能做好玉石俱焚的觉悟。
Erwin_5.wav|Erwin|ZH|將一切賭在獲勝渺茫的戰術上
Erwin_6.wav|Erwin|ZH|到了这一步
Erwin_7.wav|Erwin|ZH|要让那些年轻人们去死
Erwin_8.wav|Erwin|ZH|就必须像一个一流的诈骗犯一样
Erwin_9.wav|Erwin|ZH|对他们花言巧语一番
可以看到,除了语气特别强烈的素材,大部分都没有进行标点符号的标注。
但事实上,Whisper完全可以针对中文进行标注,只需要添加对应的引导词:
options = whisper.DecodingOptions(beam_size=5,prompt="生于忧患,死于欢乐。不亦快哉!")
这里通过prompt对其进行引导,通过逗号、句号以及感叹号对文本标注,引导后的效果:
Erwin_0.wav|Erwin|ZH|如果这个作战顺利。
Erwin_1.wav|Erwin|ZH|你也许可以趁此机会干掉受之虚人。
Erwin_10.wav|Erwin|ZH|如果到时候我不冲在最前面
Erwin_11.wav|Erwin|ZH|他们根本不会往前冲,然后我会第一个去死。
Erwin_12.wav|Erwin|ZH|地下室里到底有什么?
Erwin_13.wav|Erwin|ZH|好想去地下室看一看,我之所以能撑着走到今天。
Erwin_14.wav|Erwin|ZH|就是因为相信这一天的到来。
Erwin_15.wav|Erwin|ZH|因为艰辛着D
Erwin_16.wav|Erwin|ZH|我的猜想能够得到证实。
Erwin_17.wav|Erwin|ZH|我之前无数次地想过,要不然干脆死了算了。
Erwin_18.wav|Erwin|ZH|可即便如此,我还是想要实现父亲的梦想。
Erwin_19.wav|Erwin|ZH|然而现在
Erwin_2.wav|Erwin|ZH|但得拿所有新兵,不管选择哪条路。
Erwin_20.wav|Erwin|ZH|他的答案就在我触手可及的地方。
Erwin_21.wav|Erwin|ZH|竟在咫尺。死去的同伴们也是如此吗?
Erwin_22.wav|Erwin|ZH|那些流血的牺牲,都是没有意义的吗?
Erwin_23.wav|Erwin|ZH|不!不对!
Erwin_24.wav|Erwin|ZH|那些死去士兵的意义将由我们来赋予!
Erwin_25.wav|Erwin|ZH|那些勇敢的死者,可怜的死者!
Erwin_26.wav|Erwin|ZH|是他们的牺牲换来了我们活着的今天!
Erwin_27.wav|Erwin|ZH|让我们能站在这里,而今天我们将会死去!
Erwin_28.wav|Erwin|ZH|将依依托福给下一个活着的人!
Erwin_29.wav|Erwin|ZH|这就是我们与这个残酷的世界。
Erwin_3.wav|Erwin|ZH|是的,全灭的可能性相当的高。
Erwin_30.wav|Erwin|ZH|抗争的意义!
Erwin_4.wav|Erwin|ZH|但事到如今,也只能做好玉石俱焚的觉悟。
Erwin_5.wav|Erwin|ZH|将一切赌在获胜渺茫的战术上。
Erwin_6.wav|Erwin|ZH|到了这一步
Erwin_7.wav|Erwin|ZH|要让那些年轻人们去死。
Erwin_8.wav|Erwin|ZH|就必须像一个一流的诈骗犯一样。
Erwin_9.wav|Erwin|ZH|对他们花言巧语一番。
通过transformers来调用中文模型
transformers是一个用于自然语言处理(NLP)的开源库,由Hugging Face开发和维护。它提供了各种预训练的模型,包括文本生成、文本分类、命名实体识别等多种NLP任务的模型。transformers库基于Transformer模型架构,这是一种用于处理序列数据的深度学习模型。Transformer模型在NLP领域取得了巨大成功,因为它能够处理长距离依赖关系,并且在各种NLP任务上取得了优异的性能。
使用transformers库,开发人员可以轻松地访问和使用各种预训练的NLP模型,也可以使用该库进行模型的微调和训练。transformers库支持多种主流深度学习框架,包括PyTorch和TensorFlow。
首先安装transformers:
pip install -U transformers
编写转写代码:
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
def transcribe_bela(audio_path):
transcriber = pipeline(
"automatic-speech-recognition",
model="BELLE-2/Belle-whisper-large-v2-zh",
device=device
)
transcriber.model.config.forced_decoder_ids = (
transcriber.tokenizer.get_decoder_prompt_ids(
language="zh",
task="transcribe",
)
)
transcription = transcriber(audio_path)
print(transcription["text"])
return transcription["text"]
这里通过BELLE-2/Belle-whisper-large-v2-zh模型来进行转写,提高中文的识别准确度和效率。
这个模型是在whisper的large-v2模型上针对中文进行了微调,以增强中文语音识别能力, Belle-whisper-large-v2-zh 在中国 ASR 基准测试(包括 AISHELL1、AISHELL2、WENETSPEECH 和 HKUST)上表现出 30-70% 的相对改进。
该模型的官方地址:
https://huggingface.co/BELLE-2/Belle-whisper-large-v2-zh
当然,也不是没有缺陷,BELLE-2模型目前基于AISHELL、WENETSPEECH等数据做的微调,弱化了标点能力。
换句话说,没法通过引导词来打标,但其实也有其他解决方案,即可以基于标点模型 对转写文本加标点。比如这个方案:
https://modelscope.cn/models/damo/punc_ct-transformer_cn-en-common-vocab471067-large/summary
BELLE-2模型的作者相当热心,有问必答,这是笔者对其模型提的Issues:
https://github.com/LianjiaTech/BELLE/issues/571
现在该模型的瓶颈是,如果微调带标点的中文数据,这块开源数据相对比较少,无法进行有效的训练。
除了大模型的中文优化版本,也有针对small模型的中文优化版本:文章来源:https://www.toymoban.com/news/detail-824333.html
https://huggingface.co/Jingmiao/whisper-small-chinese_base
结语
Whisper开源模型通过transformers的微调,可以将预训练模型应用于特定的中文NLP任务,从而提高模型在该任务上的性能。微调使模型能够学习适应特定任务的特征和模式,从而实现更好的效果。文章来源地址https://www.toymoban.com/news/detail-824333.html
到了这里,关于Whisper对于中文语音识别与转写中文文本优化的实践(Python3.10)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!