介绍
为什么需要
正则表达式是处理文本的利器;
基本介绍
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE)。它是一个强大的字符串处理工具,可以对字符串进行查找、提取、分割、替换等操作,是一种可以用于模式匹配和替换的规范;
一个正则表达式就是由普通的字符(如字符 a~z)以及特殊字符(元字符)组成的文字模式,用以描述在查找文字主体时待匹配的一个或多个字符串。
jdk1.4推出 java.util.regex 包,它包含了 Pattern 和 Matcher 类,用于处理正则表达式的匹配操作。
package com.lhy.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分析java的正则表达式的底层实现(重要.)
*/
public class RegTheory {
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布" ;
//目标:匹配所有四个数字
//说明
//1. \\d 表示一个任意的数字
String regStr = "(\\d\\d)(\\d\\d)";
//2. 创建一个模式对象[即正则表达式对象]
Pattern pattern = Pattern.compile(regStr);
//3. 创建一个匹配器对象
//说明:创建匹配器matcher, 按照 正则表达式的规则(pattern模式) 去匹配 content字符串
Matcher matcher = pattern.matcher(content);
//4.开始循环匹配
while (matcher.find()) {
//小结
//1. 如果正则表达式有() 即分组
//2. 取出匹配的字符串规则如下
//3. group(0) 表示匹配到的子字符串
//4. group(1) 表示匹配到的子字符串的第一组字串
//5. group(2) 表示匹配到的子字符串的第2组字串
//6. ... 但是分组的数不能越界.
System.out.println("找到: " + matcher.group(0));//找到: 1998
System.out.println("第1组()匹配到的值=" + matcher.group(1));//19
System.out.println("第2组()匹配到的值=" + matcher.group(2));//98
}
}
}
语法
\\符号说明:在我们使用正则表达式去检索某些特殊字符的时候,需要用到转义字符,否则检测不到结果,甚至会报错。
注意:在Java的正则表达式中,两个\\代表其他语言中的一个\;
元字符
限定符
用于指定其前面的字符和组合项连续出现多少次。
| 符号 | 含义 | 示例 | 说明 | 匹配输入 |
| * | 指定字符重复0次或n次(无要求)零到多 | (abc)* | 仅包含任意个abc的字符串,等效于\w* | abc、 abcabcabc |
| + | 指定字符重复1次或n次(至少 一次)1到多 | m+(abc)* | 以至少1个m开头,后接任意个abc的字 符串 | m、mabc、 mabcabc |
| ? | 指定字符重复0次或1次(最多 一次)0到1 | m+abc? | 以至少1个m开头,后接ab或abc的字符 串 | mab、mabc、mmmab. mmabc |
| {} | 只能输入n个字符 | [abcd]{3} | 由abcd中字母组成的任意长度为3的字 符串 | abc、dbc、adc |
| {n,} | 指定至少n个匹配 | [abcd]{3,} | 由abcd中字母组成的任意长度不小于3的字符串 | aab、dbc、aaabdc |
| {n,m} | 指定至少n个但不多于m个匹配 | [abcd]{3,5} | 由abcd中字母组成的任意长度不小于3,不大于5的字符串 | abc、abcd、aaaaa、bcdab |
java默认为
贪婪匹配。
- 即:在限定出现次数里,优先匹配出现
次数最多的一组。- 例如:用a{3,5}来匹配aaaaaacx,返回的式aaaaa。
- 例如:
a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的
话,它会匹配整个字符串aabab。
?组合的时候,它只作用于离他最近的那一个字符。
- 例如:
m+abc?中,?只作用于字符c。如果想要使用非贪婪匹配(懒惰匹配),则在限定符后面加上
?即可。
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)
选择匹配符
在匹配某个字符串的时候是选择性的,即可以匹配这个,也可以匹配那个。
|
符号
|
符号 | 示例 | 解释 |
| | | 匹配“|”之前或之后的表达式 | ab|cd | ab或者cd |
分组组合和反向引用符
1、分组
- 我们可以用圆括号组成一个比较复杂的四配模式,那么一个圆括号的部分我们可以看作是一个子表达式或一个分组。
2、捕获分组
- 把正则表达式中子表达式或分组匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。组0代表的是整个正则式。
| 常用分组构造形式 | 说明 |
| (pattern) | 非命名捕获。捕获匹配的子字符串。编号为零的第一个捕获是由整个正则表达式模式匹配的文本,其它捕获结果则根据左括号的顺序从1开始自动编号。(在分析底层源码的时候说过) |
| (?pattern) | 命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中。用于name的字符串不能包括任何标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如(?`name`) |
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Reg02 {
public static void main(String[] args) {
String test = "020-85652222";
//1.匹配目标
String reg="(0\\d{2})-(\\d{8})";
//2. 创建一个模式对象[即正则表达式对象]
Pattern pattern = Pattern.compile(reg);
//3.创建匹配器
Matcher mc= pattern.matcher(test);
if(mc.find()){
System.out.println("分组的个数有:"+mc.groupCount());
for(int i=0;i<=mc.groupCount();i++){
System.out.println("第"+i+"个分组为:"+mc.group(i));
}
}
}
}
输出结果:
分组的个数有:2
第0个分组为:020-85652222
第1个分组为:020
第2个分组为:85652222
String test = "020-85653333";
String reg="(?<quhao>0\\d{2})-(?<haoma>\\d{8})";
Pattern pattern = Pattern.compile(reg);
Matcher mc= pattern.matcher(test);
if(mc.find()){
System.out.println("分组的个数有:"+mc.groupCount());
System.out.println(mc.group("quhao"));
System.out.println(mc.group("haoma"));
}
输出结果:
分组的个数有:2
分组名称为:quhao,匹配内容为:020
分组名称为:haoma,匹配内容为:85653333
3、非捕获分组
| 常用分组构造形式 | 说明 |
| (?:pattern) | 匹配pattern但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储以后使用的匹配。这对于用“or”字符(|)组合模式部件的情况很有用。例如:`industr(?:y |
| (?=pattern) | 它是一个非捕获匹配。例如:`windows(?=95 |
| (?!pattern) | 该表达式匹配不处于匹配pattern的字符串的起始点的搜索字符串。它是一个非捕获匹配。例如:`windows(?!95 |
String test = "020-85653333";
String reg="(?:0\\d{2})-(\\d{8})";
Pattern pattern = Pattern.compile(reg);
Matcher mc= pattern.matcher(test);
if(mc.find()){
System.out.println("分组的个数有:"+mc.groupCount());
for(int i=0;i<=mc.groupCount();i++){
System.out.println("第"+i+"个分组为:"+mc.group(i));
}
}
输出结果:
分组的个数有:1
第0个分组为:020-85653333
第1个分组为:85653333
//正向先行断言
零宽度正预测先行断言
语法:(?=pattern)
作用:匹配pattern表达式的前面内容,不返回本身。
【正向先行断言】可以匹配表达式前面的内容,那意思就是(?=) 就可以匹配到前面的内容了。
@Test
public void testAssert1(){
String regex = ".+(?=</span>)";
String context = "<span class=\"read-count\">阅读数:641</span>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
//匹配结果:<span class="read-count">阅读数:641
//可是我们要的只是前面的数字呀,那也简单咯,匹配数字 \d,那可以改成:
@Test
public void testAssert2(){
String regex = "\\d+(?=</span>)";
String context = "<span class=\"read-count\">阅读数:641</span>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
//匹配结果:
//641
4、反向引用
圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个我们称为反向引用,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用\\分组号,外部反向引用$分组号。
public class RegTheory {
public static void main(String[] args) {
String content = "123-abc";
String regStr = "(?<i1>\\d)(?<i2>\\d)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println(matcher.group("i1"));
System.out.println(matcher.group("i2"));
}
}
}
// 结果是1,2
正向后行断言:
零宽度正回顾后发断言,断言在前,模式在后
语法:(?<=pattern)
作用:匹配pattern表达式的后面的内容,不返回本身。
有先行就有后行,先行是匹配前面的内容,那后行就是匹配后面的内容啦。
@Test
public void testAssert3(){
String regex = "(?<=<span class=\"read-count\">阅读数:)\\d+";
String context = "<span class=\"read-count\">阅读数:641</span>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
@Test
public void testRef(){
String context = "aabbxxccdddsksdhfhshh";
String regex = "(\\w)\\1";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
输出结果:
aa
bb
xx
cc
dd
hh
//请编写一个 Servlet, 可以获取到浏览器所在电脑的操作系统版本和位数(32 还是 64), 显示在页面即可。
//(User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0)
public class ComputerServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doPost(req,resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String user_agent = req.getHeader("User-Agent");
//1.匹配目标
String regStr = "\\((.*)\\)";
//2. 创建一个模式对象[即正则表达式对象]
Pattern pattern = Pattern.compile(regStr);
//3. 创建一个匹配器对象
//说明:创建匹配器matcher, 按照 正则表达式的规则(pattern模式) 去匹配 content字符串
Matcher matcher = pattern.matcher(user_agent);
//4.开始循环匹配
while (matcher.find()) {
//匹配内容,放在 matcher.group(0);
String group01 = matcher.group(1);
String[] split = group01.split(";");
System.out.println("操作系统=" +split[0]);//Windows NT 10.0
System.out.println("操作系统位数=" + split[1].trim());// Win64
}
}
}特殊字符--转义符
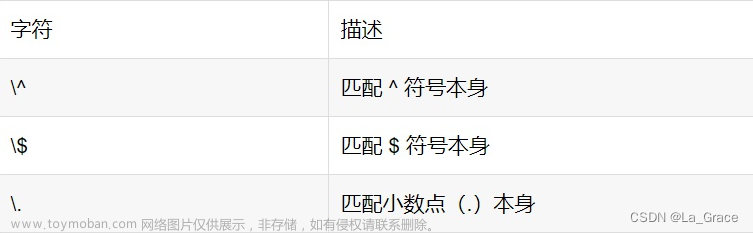
需要用到转移符号的字符有以下:. * + ( ) $ / \ ? [ ] ^ { }
字符匹配符
| 符号 | 符号 | 示例 | 解释 |
| [] | 可接收的字符列表 | [efgh] | e、f、g、h中的任意1个字符 |
| [^] | 不接收的字符列表 | [^abc] | 除a、b、c之外的任意1个字符, 包括数字和特殊符号 |
| - | 连字符 | A-Z | 任意单个大写字母 |
| . | 匹配除\n以外的任何字节 | a…b | 以a开头,b结尾,中间包括2个任意字符的长度为4的字符串 |
| \\d | 匹配单个数字字符,相当于[0-9] | \\d{3}(\\d)? | 包含3个或4个数字的字符串 |
| \\D | 匹配单个非数字字符,相当于[^0-9] | \\D(\\d)* | 以单个非数字字符的开头,后接任意个数字字符串 |
| \\w | 匹配单个数字、大小写字母字符,相当于[0-9a-zA-Z] | \\d{3}\\w{4} | 以3个数字字符开头的长度为7的数字字母字符串 |
| \\W | 匹配单个非数字,大小写字母字符,相当于[^0-9a-zA-Z] | \\W+\\d{2} | 以至少1个非数字字母字符开头,2个数字字符结尾的字符串 |
| \\s | 匹配任何空白字符(空格,制表符等) | ||
| \\S | 匹配任何非空白字符,和\\s刚好相反 |
定位符
| 符号 | 含义 | 示例 | 说明 | 匹配输入 |
| ^ | 指定起始字符 | ^[0-9]+[a-z]* | 以至少1个数字开头,后接任意个小写字 母的字符串 | 123、6aa、555edf |
| $ | 指定结束字符 | ^[0-9]\\-[a-z]+$ | 以1个数字开头后接连字符“-”,并以至少1个小写字母结尾的字符串 | 1-a |
| \\b | 匹配目标字符串的边界 | han\\b | 这里说的字符串的边界指的是子串间有空格,或者是目标字符串的结束位置 | hanshunping sphan nnhan |
| \\B | 匹配目标字符串的非边界 | han\\B | 和b的含义刚刚相反 | hanshunping sphan nr |
其他
java正则表达式默认是区分字母的大小写。如何实现不区分大小写的方式❓
- 方式一:在需要不区分大小写的表达式前面写上(?i)。但需要注意的是,如果是表达式中间的某个字符不区分大小写的时候需要将它们括起来,例如:a((?i)b)c。
- 方式二:Pattern pat = Pattern.compile(regEx,Pattern.CASE_INSENSITIVE);
常用类
Pattern 类(模式类):
pattern 对象是一个正则表达式的编译表示形式:指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建 Matcher 对象,依照正则表达式,该对象可以与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一模式。
Pattern 类没有公共构造方法;首先调用其公共静态编译方法,可返回一个 Pattern 对象, 该方法接受一个正则表达式作为它的第一个参数;,比如:Pattern r = Pattern.compile(pattem)
String content = "hello helloasdas";
String regStr = "hello";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println(matcher.group(0));// 部分匹配,这里会匹配到两个hello
}
boolean matches = Pattern.matches(regStr, content);
System.out.println(matches);
// 这是false,因为它是整体匹配,即正则表达式去匹配整个字符;表示字符串完全符合给出的正则表达式所表示的范围。只要有一个字符不匹配则返回false串。
//matches()的底层也只是封装了find()方法。Matcher 类(匹配器类):
Matcher 对象是对输入字符串进行解释和匹配操作的引擎;与Pattern 类一样,Matcher 也没有公共构造方法;需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象
Macher类的常用方法
索引方法
| 序号 | 方法 | 说明 |
| 1 | public int start() | 返回以前匹配的初始索引。 |
| 2 | public int start(int group) | 返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引 |
| 3 | public int end() | 返回最后匹配字符之后的偏移量。 |
| 4 | public int end(int group) | 返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。 |
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("aaa2223bb");
m.find();//匹配2223
m.start();//返回3
m.end();//返回7,返回的是2223后的索引号
m.group();//返回2223
Mathcer m2=m.matcher("2223bb");
m.lookingAt(); //匹配2223
m.start(); //返回0,由于lookingAt()只能匹配前面的字符串,所以当使用lookingAt()匹配时,start()方法总是返回0
m.end(); //返回4
m.group(); //返回2223
Matcher m3=m.matcher("2223bb");
m.matches(); //匹配整个字符串
m.start(); //返回0,原因相信大家也清楚了
m.end(); //返回6,原因相信大家也清楚了,因为matches()需要匹配所有字符串
m.group(); //返回2223bb
Pattern p=Pattern.compile("([a-z]+)(\\d+)");
Matcher m=p.matcher("aaa2223bb");
m.find(); //匹配aaa2223
m.groupCount(); //返回2,因为有2组
m.start(1); //返回0 返回第一组匹配到的子字符串在字符串中的索引号
m.start(2); //返回3
m.end(1); //返回3 返回第一组匹配到的子字符串的最后一个字符在字符串中的索引位置.
m.end(2); //返回7
m.group(1); //返回aaa,返回第一组匹配到的子字符串
m.group(2); //返回2223,返回第二组匹配到的子字符串查找方法
| 序号 | 方法 | 说明 |
| 1 | public boolean lookingAt() | 尝试将从区域开头开始的输入序列与该模式匹配。 |
| 2 | public boolean find() | 尝试查找与该模式匹配的输入序列的下一个子序列。 |
| 3 | public boolean find(int start) | 重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。 |
| 4 | public boolean matches() | 尝试将整个区域与模式匹配。 |
@Test
public void testMatches() {
String regex = "Mary";
String content1 = "Mary";
String content2 = "Mary is very handsome !";
String content3 = "My name is Mary.";
Pattern pattern = Pattern.compile(regex);
Matcher matcher1 = pattern.matcher(content1);
Matcher matcher2 = pattern.matcher(content2);
Matcher matcher3 = pattern.matcher(content3);
System.out.println("matches1(): " + matcher1.matches());
System.out.println("lookingAt1(): " + matcher1.lookingAt());
System.out.println("matches2(): " + matcher2.matches());
System.out.println("lookingAt2(): " + matcher2.lookingAt());
System.out.println("matches3(): " + matcher3.matches());
System.out.println("lookingAt3(): " + matcher3.lookingAt());
}
结果:
matches(): true
lookingAt(): true
matches(): false
lookingAt(): true
matches(): false
lookingAt(): false
//现在我们使用一下稍微高级点的正则匹配操作,例如有一段文本,里面有很多数字,而且这些数字是分开的,我们现在要将文本中所有数字都取出来,利用java的正则操作是那么的简单.
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("我的QQ是:456456 我的电话是:0532214 我的邮箱是:aaa123@aaa.com");
while(m.find()) {
System.out.println(m.group());
}
输出:
456456
0532214
123
package com.lhy.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class regex02 {
public static void main(String[] args) {
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("我的QQ是:456456 我的电话是:0532214 我的邮箱是:aaa123@aaa.com");
while(m.find()) {
System.out.println(m.group());
System.out.print("start:"+m.start());
System.out.println(" end:"+m.end());
}
}
}
则输出:
456456
start:6 end:12
0532214
start:19 end:26
123
start:36 end:39 每次执行匹配操作后start(),end(),group()三个方法的值都会改变,改变成匹配到的子字符串的信息,以及它们的重载方法,也会改变成相应的信息.
注意:只有当匹配操作成功,才可以使用start(),end(),group()三个方法,否则会抛出java.lang.IllegalStateException,也就是当matches(),lookingAt(),find()其中任意一个方法返回true时,才可以使用.
替换方法
| 序号 | 方法 | 说明 |
| 1 | public Matcher appendReplacement(StringBuffer sb, String replacement) | 实现非终端添加和替换步骤。 |
| 2 | public StringBuffer appendTail(StringBuffer sb) | 实现终端添加和替换步骤。 |
| 3 | public String replaceAll(String replacement) | 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| 4 | public String replaceFirst(String replacement) | 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| 5 | public static String quoteReplacement(String s) | 返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给Matcher类的appendReplacement 方法一个字面字符串一样工作。 |
@Test
public void testReplace(){
String regex = "Mary";
String context = "My name is Mary, Mary is very handsome. ";
String replacement = "Lucy";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(context);
String result1 = m.replaceAll(replacement);
System.out.println(result1);
String result2 = m.replaceFirst(replacement);
System.out.println(result2);
}
结果:
My name is Lucy, itlils is very handsome.
My name is Lucy, itnanls is very handsome.
@Test
public void testAppend() {
String REGEX = "a*b";
String INPUT = "aabfooaabfooabfooabkkk";
String REPLACE = "-";
Pattern p = Pattern.compile(REGEX);
// 获取 matcher 对象
Matcher m = p.matcher(INPUT);
StringBuffer sb = new StringBuffer();
m.find();
m.appendReplacement(sb, REPLACE);
System.out.println(sb);
m.find();
m.appendReplacement(sb, REPLACE);
System.out.println(sb);
m.appendTail(sb);
System.out.println(sb);
}
结果:
-
-foo-
-foo-fooabfooabkkk
PatternSyntaxException:
它表示一个正则表达式模式中的语法错误;PatternSyntaxException 是一个非强制异常类;
其他
String类中使用正则表达式的方法
| 方法 | 返回类型 | 功能 | 示例 |
| matches() | boolean | 告知此字符串是否匹配给定的正则表达式。 | "-1234".matches("^-?\\d+$") => true |
| replaceAll(String regex, String replacement) | String | 使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。 | "a1b2c3".replaceAll("[a-zA-z]", "") => 123 |
| replaceFirst(String regex, String replacement) | String | 使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串。 | "Hello World! Hello Everyone!".replaceFirst("\\s", "") => HelloWorld! Hello Everyone! |
| split(String regex) | String[] | 根据给定正则表达式的匹配拆分此字符串。 | "boo:and:foo".split(":") => { "boo", "and", "foo" } |
| split(String regex, int limit) | String[] | 根据给定正则表达式的匹配拆分此字符串。 | "boo:and:foo".split(":", 5) => { "boo", "and", "foo" } |
split(String regex, int limit)方法中limit 参数控制模式应用的次数,因此影响所得数组的长度。
- 如果该限制 n 大于 0,则模式将被最多应用 n - 1 次,数组的长度将不会大于 n,而且数组的最后一项将包含所有超出最后匹配的定界符的输入。
- 如果 n 为非正,那么模式将被应用尽可能多的次数,而且数组可以是任何长度。
- 如果 n 为 0,那么模式将被应用尽可能多的次数,数组可以是任何长度,并且结尾空字符串将被丢弃。
- 例如,字符串
"boo:and:foo"使用这些参数可生成以下结果:
| Regex | Limit | 结果 |
| : | 2 | { "boo", "and:foo" } |
| : | 5 | { "boo", "and", "foo" } |
| : | -2 | { "boo", "and", "foo" } |
| o | 5 | { "b", "", ":and:f", "", "" } |
| o | -2 | { "b", "", ":and:f", "", "" } |
| o | 0 | { "b", "", ":and:f" } |
调用此方法的 str.split(regex, n) 形式与以下表达式产生的结果完全相同:Pattern.compile(regex).split(str, n)
String content = "hello helloasdas";
String str = content.replaceAll("(\\w)\\1+", "$1");
System.out.println(str); // 结果helo heloasdas
String content = "hehllos";
String regex = "^(h)\\w*s$";
boolean matches = content.matches("^(h)\\w*s$");
System.out.println(matches); //结果 true
String content = "hehllos";
String[] hs = content.split("h");
for (String h : hs) {
System.out.println(h);
} // 结果: e llos
常用正则表达式
校验数字的表达式
1 数字:^[0-9]*$
2 n位的数字:^\d{n}$
3 至少n位的数字:^\d{n,}$
4 m-n位的数字:^\d{m,n}$
5 零和非零开头的数字:^(0|[1-9][0-9]*)$
6 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
8 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
9 有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
10 有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
11 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13 非负整数:^\d+$ 或 ^[1-9]\d*|0$
14 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
1 汉字:^[\u4e00-\u9fa5]{0,}$
2 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3 长度为3-20的所有字符:^.{3,20}$
4 由26个英文字母组成的字符串:^[A-Za-z]+$
5 由26个大写英文字母组成的字符串:^[A-Z]+$
6 由26个小写英文字母组成的字符串:^[a-z]+$
7 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
8 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
12 禁止输入含有~的字符:[^~\x22]+
特殊需求表达式
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3 InternetURL:[a-zA-z]+://[^\s]* 或 ^https://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7 身份证号:
15或18位身份证:^\d{15}|\d{18}$
15位身份证:^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$
18位身份证:^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$
8 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
11 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
12 日期格式:^\d{4}-\d{1,2}-\d{1,2}
13 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
14 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
15 钱的输入格式:
16 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
17 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
18 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
19 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.
把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
20 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
21 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
22 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
23 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
24 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)
最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
25 xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
26 中文字符的正则表达式:[\u4e00-\u9fa5]
27 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
28 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
29 HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> (网上流传的版本太糟糕,
上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
30 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的
空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)文章来源:https://www.toymoban.com/news/detail-824337.html
33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)文章来源地址https://www.toymoban.com/news/detail-824337.html
应用案例
//将一个文件中的电话的中间四个数字替换成xxxx? 例子 15236985456 --> 152xxxx5456
姓名 年龄 邮箱 电话
张小强 23 526845845@163.com 13759685424
丁新新 20 238011792@qq.com 18011023709
李银龙 20 liyinl1199w@163.com 17308811441
赵资本 19 anhuo69579@126.com 18234417225
李成刚 21 19713318@qq.com 13279906620
王铁柱 20 ykl3987671@163.com 18802836971
张龙虎 22 zh199715@gmail.com 13888906654
李洁一 18 nl897665@yahoo.com 19762297581
刘大志 20 197685551@qq.com 15299744196
杨天天 19 86765ytian@126.com 17663999002
陈承成 21 rr796232@hotmail.com 18137541864
@Test
public void hidePhoneNumber() throws IOException {
StringBuilder sb = new StringBuilder();
// 1、将文件的内容读取到内存
InputStream in = new FileInputStream("D:\\user.txt");
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf)) > 0){
sb.append(new String(buf,0,len));
}
// 2、进行正则匹配
String regex = "(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])(\\d{4})(\\d{4})";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(sb.toString());
String result = matcher.replaceAll("$1xxxx$3");
System.out.println(result);
}
//通过scanner输入一个字符串,判断是否是一个邮箱?
public class TestEmail {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String email = scanner.next();
String regex = "^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(email);
boolean matches = matcher.matches();
if(matches){
System.out.println("您输入的是一个邮箱!");
} else {
System.out.println("您输入的不是邮箱!");
}
}
}
到了这里,关于Java学习(二十二)--正则表达式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!