| 阅读此需阅读下面这些博客先 |
|---|
| 【Spring源码分析】Bean的元数据和一些Spring的工具 |
| 【Spring源码分析】BeanFactory系列接口解读 |
| 【Spring源码分析】执行流程之非懒加载单例Bean的实例化逻辑 |
| 【Spring源码分析】从源码角度去熟悉依赖注入(一) |
上篇这里简单提一下哈,怕有些没看的,这是连着的…:
- 上篇是提了下生命周期的属性注入阶段,也就是 populateBean 的具体实现;
- 然后里面涉及到实例化后阶段,和三种注入方式,Spring的BYNAME和BYTYPE还有通过MergedBeanDefinitionPostProcessor 去重定义 BeanDefinition 时的注入这俩种是简单提了一下,然后就准备去详细分析一下使用@Autowired注解是如何注入的呢?这就涉及到 InstantiationAwareBeanPostProcessor 的实现类 AutowiredAnnotationBeanPostProcessor 里的具体实现了;
- 然后就去简单分析了一下是注入的,首先是去遍历属性和方法,看谁有 @Autowired、@Value 这俩注解,有就创建对应的 InjectElement 然后进行注入。
这篇呢主要就是去分析一下 AutowiredFieldElement 和 AutowiredMethodElement 里注入的具体实现。
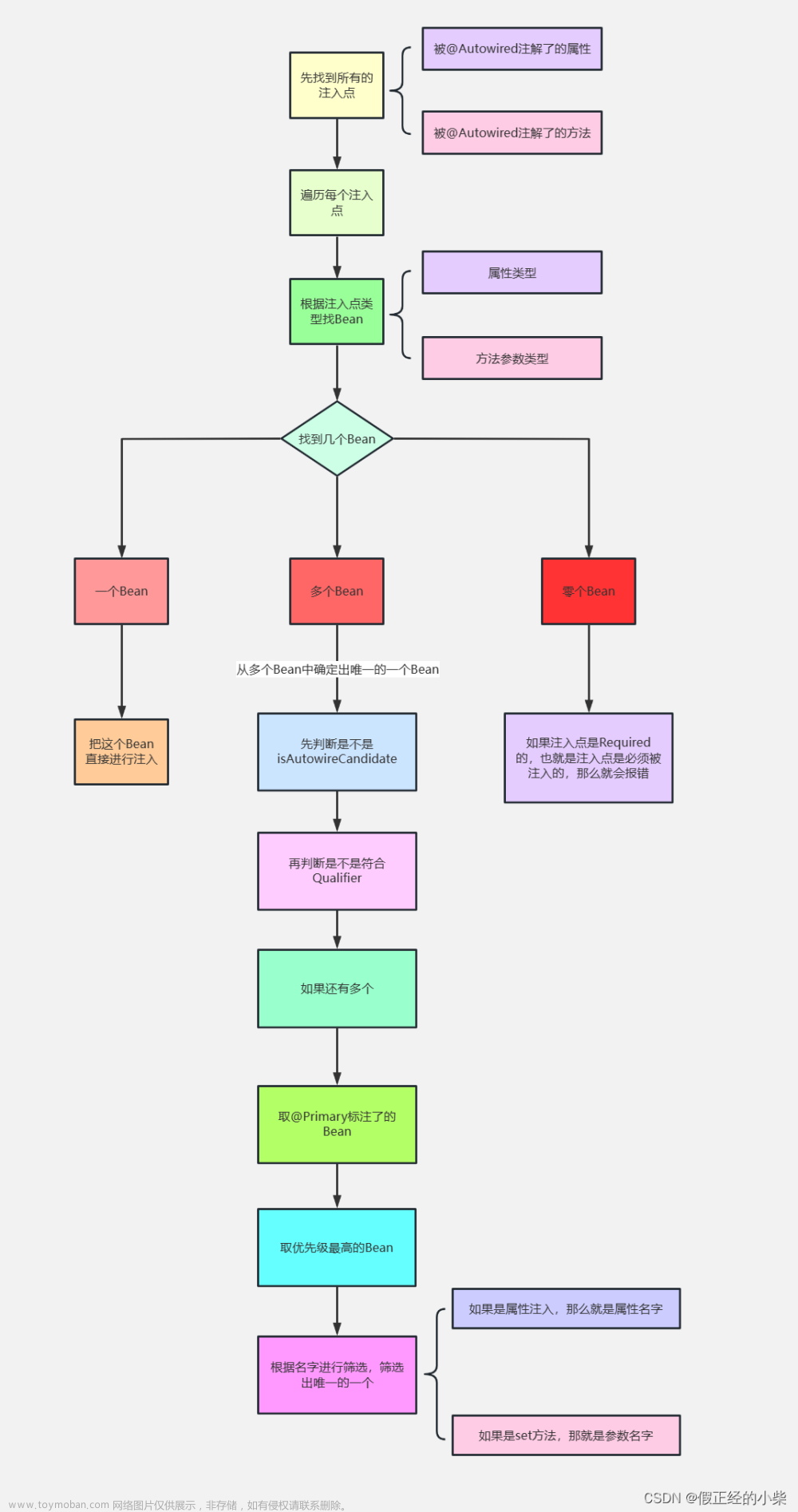
也是对应着下面流程图中的 如何去寻找Bean的?
一、AutowiredFieldElement 注入分析
注入属性,就是去找到对应Bean,然后通过反射去赋值了,所以咱具体看看 resolveFieldValue(这上篇都有说过): 往里看,可以注意到其解析依赖获取Bean的逻辑是通过 beanFactory#resolveDependency 去实现的,传的参数有俩主要的就是类型转化器和属性描述对象(它是 AutowiredCapableBeanFactory 接口里的一个方法,即使不说,也应该猜到,毕竟这是在属性注入流程里出现的):
往里看,可以注意到其解析依赖获取Bean的逻辑是通过 beanFactory#resolveDependency 去实现的,传的参数有俩主要的就是类型转化器和属性描述对象(它是 AutowiredCapableBeanFactory 接口里的一个方法,即使不说,也应该猜到,毕竟这是在属性注入流程里出现的): 上篇说了,AutowiredAnnotationBeanPostProcessor 是有实现 BeanFactoryAware 接口的,那么它在初始化前就会去操作把 BeanFactory 注入到它这里面,注入的是
上篇说了,AutowiredAnnotationBeanPostProcessor 是有实现 BeanFactoryAware 接口的,那么它在初始化前就会去操作把 BeanFactory 注入到它这里面,注入的是 DefaultListableBeanFactory ,然后它向上转型成了 ConfigurableListableBeanFactory,转不转都一样,ConfigurableListableBeanFactory 接口本就覆盖了所有 BeanFactory 接口系列的功能,这前面也阐述过:
那也就是说,咱接下来得分析,DefaultListableBeanFactory#resolveDependency,在分析之前得清除,这是 DefaultListableBeanFactory 下的方法实现,而传的参数 DependencyDescriptor 也是注入点的子类,就是说其可以描述构造参数、属性、方法参数,即该方法不管是注入的公共方法,包括属性和方法(所以如果碰到关系方法的地方不要懵,比如下面的第一行)。
@Override
@Nullable
public Object resolveDependency(DependencyDescriptor descriptor, @Nullable String requestingBeanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
// 用来获取方法入参名字的
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
// 所需要的类型是Optional
if (Optional.class == descriptor.getDependencyType()) {
return createOptionalDependency(descriptor, requestingBeanName);
}
// 所需要的的类型是ObjectFactory,或ObjectProvider
else if (ObjectFactory.class == descriptor.getDependencyType() ||
ObjectProvider.class == descriptor.getDependencyType()) {
return new DependencyObjectProvider(descriptor, requestingBeanName);
}
else if (javaxInjectProviderClass == descriptor.getDependencyType()) {
return new Jsr330Factory().createDependencyProvider(descriptor, requestingBeanName);
}
else {
// 在属性或set方法上使用了@Lazy注解,那么则构造一个代理对象并返回,真正使用该代理对象时才进行类型筛选Bean
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
// descriptor表示某个属性或某个set方法
// requestingBeanName表示正在进行依赖注入的Bean
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;
}
}
- 首先是获取到参数的名字,这肯定是字节码层面的,咱别去细究了;
- 然后是去对类型进行判断,Optional、ObjectFactory、ObjectProvider、javax下的那Provider,这些俺几乎不用,不去详细看了,直接看else的逻辑;
- 判断参数上是不是加了
@Lazy注解,如果加了表示该Bean注入进行懒加载,这样就话返回的就是一个CGLIB的动态代理对象。- 在 Mybatis 源码分析里,咱遇到过Javassit、jdk、CGLIB 三种动态代理,这里为什么选择 CGLIB原因如下:它不是运行时候用的,它是直接Spring加载的时候进行的,所以不需要Javassit 去做,而jdk动态代理是在接口层面的,属性注入肯定不仅仅是类,所以毫无疑问 CGLIB 是这里最好的选择了。
- 如果没用 @Lazy 的话,就是正常构造了,调用
doResolveDependency方法。
下面有做懒加载的测试: 可以看见这调试的是一个代理对象,且是 CGLIB 代理:
可以看见这调试的是一个代理对象,且是 CGLIB 代理: doResolveDependency 方法是解决属性注入的核心,咱分标题去分析。下面看一下,AutowiredMethodElement的注入,将俩关联起来。
doResolveDependency 方法是解决属性注入的核心,咱分标题去分析。下面看一下,AutowiredMethodElement的注入,将俩关联起来。
二、AutowiredMethodElement注入分析
有关方法方式的注入,主要是在 resolveMethodArguments 方法中进行:
 里面的实现逻辑就是去遍历每一个参数,然后去调用
里面的实现逻辑就是去遍历每一个参数,然后去调用 DefaultListableBeanFactory#resolveDependency 方法获取到对应的Bean,然后放到数组中,最后返回。
 至于 resolveDependency 的实现逻辑,就和上面串起来了。
至于 resolveDependency 的实现逻辑,就和上面串起来了。
三、doResolveDependency 源码分析
(吐槽一下,本来就是这部分注入流程都在这里,我分析源码解读算细了,但CSDN md 恶心人,昨天写的今天打开草稿一看全没了,我是真服了)
先给出源码,再针对源码各部分依次解读:
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
InjectionPoint previousInjectionPoint = ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
// 如果当前descriptor之前做过依赖注入了,则可以直接取shortcut了,相当于缓存
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}
Class<?> type = descriptor.getDependencyType();
// 获取@Value所指定的值
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
// 占位符填充(${})
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
// 解析Spring表达式(#{})
value = evaluateBeanDefinitionString(strVal, bd);
}
// 将value转化为descriptor所对应的类型
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}
// 如果descriptor所对应的类型是数组、Map这些,就将descriptor对应的类型所匹配的所有bean方法,不用进一步做筛选了
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
// 找到所有Bean,key是beanName, value有可能是bean对象,有可能是beanClass
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
// required为true,抛异常
// 找不到对应的Bean,但是 required 又是 true,就会抛出异常,@Autowired 的 required 默认是 true 的
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
// 根据类型找到了多个Bean,进一步筛选出某一个, @Primary-->优先级最高--->name
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
// 记录匹配过的beanName
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
// 有可能筛选出来的是某个bean的类型,此处就进行实例化,调用getBean
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
Object result = instanceCandidate;
if (result instanceof NullBean) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
result = null;
}
if (!ClassUtils.isAssignableValue(type, result)) {
throw new BeanNotOfRequiredTypeException(autowiredBeanName, type, instanceCandidate.getClass());
}
return result;
}
finally {
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
1. @Value 注解解析
在判定字段和方法是否为注入点时,除了判定 @Autowired 注解还有就是 @Value 注解。而这里就是对 @Value 注解进行解析:
Class<?> type = descriptor.getDependencyType();
// 获取@Value所指定的值
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
// 占位符填充(${})
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
// 解析Spring表达式(#{})
value = evaluateBeanDefinitionString(strVal, bd);
}
// 将value转化为descriptor所对应的类型
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}
解析过程很简单,就是拿到 @Value 注解中的内容,若是 ${} 开头就去 Environment 中去寻其结果。要是 #{} 开头就是用 SPEL 表达式解析器去解析。
不管是从环境对象(配置文件、系统配置、总环境配置)中去找还是SPEL表达式解析,最后都有一个值,然后再交给转换器进行转换得到结果后返回。
测试 ${} 和 #{}
编写对应配置: 引入配置:
引入配置:
测试:

2. resolveMultipleBeans 筛选特殊类型(处理多Bean)
// 如果descriptor所对应的类型是数组、Map这些,就将descriptor对应的类型所匹配的所有bean方法,不用进一步做筛选了
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
resolveMultipleBeans 方法对 Stream、数组、Collection、Map 这三种情况进行了处理。
其实处理方式大致都一样,这里随便抽一种类型进行解释,其他的你们能懂。
Map 的处理方式如下:
- 主要就是去找到 Map 上对应的泛型类型;
- 然后通过Value泛型的类型去调用 findAutowireCandidates 方法去根据类型找对应的Beans,返回的是一个 Map<String,Object> 其中key 是 beanName,Value 是对应的Bean。
- 若是其他类型的话就这个Map进行些处理,然后返回结果集就好了,这 Map 是不需要处理的,然后就直接返回了。
测试


findAutowireCandidates 方法解析
这个方法很重要,也很难,主要概括下就是通过类型去找对应Bean的Map集合,Key 是 BeanName,Value 的话是对应的Bean或者是对应的Class对象。
先给出源码的解析:
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
// 从BeanFactory中找出和requiredType所匹配的beanName,仅仅是beanName,这些bean不一定经过了实例化,只有到最终确定某个Bean了,如果这个Bean还没有实例化才会真正进行实例化
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = CollectionUtils.newLinkedHashMap(candidateNames.length);
// 根据类型从resolvableDependencies中匹配Bean,resolvableDependencies中存放的是类型:Bean对象,比如BeanFactory.class:BeanFactory对象,在Spring启动时设置
for (Map.Entry<Class<?>, Object> classObjectEntry : this.resolvableDependencies.entrySet()) {
Class<?> autowiringType = classObjectEntry.getKey();
if (autowiringType.isAssignableFrom(requiredType)) {
Object autowiringValue = classObjectEntry.getValue();
autowiringValue = AutowireUtils.resolveAutowiringValue(autowiringValue, requiredType);
if (requiredType.isInstance(autowiringValue)) {
result.put(ObjectUtils.identityToString(autowiringValue), autowiringValue);
break;
}
}
}
for (String candidate : candidateNames) {
// 如果不是自己,则判断该candidate到底能不能用来进行自动注入
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 为空要么是真的没有匹配的,要么是匹配的自己
if (result.isEmpty()) {
// 需要匹配的类型是不是Map、数组之类的
boolean multiple = indicatesMultipleBeans(requiredType);
// Consider fallback matches if the first pass failed to find anything...
DependencyDescriptor fallbackDescriptor = descriptor.forFallbackMatch();
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, fallbackDescriptor) &&
(!multiple || getAutowireCandidateResolver().hasQualifier(descriptor))) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 匹配的是自己,被自己添加到result中
if (result.isEmpty() && !multiple) {
// Consider self references as a final pass...
// but in the case of a dependency collection, not the very same bean itself.
for (String candidate : candidateNames) {
if (isSelfReference(beanName, candidate) &&
(!(descriptor instanceof MultiElementDescriptor) || !beanName.equals(candidate)) &&
isAutowireCandidate(candidate, fallbackDescriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
}
}
return result;
}
咱先对整体的流程进行个概述:
-
BeanFactoryUtils.beanNamesForTypeIncludingAncestors是去根据类型去找到对应的 beanNames,这个是真正的根据类型去找。内部实现概述起来不难,就是去遍历所有的beanNames,如果单例池中有就拿bean出来,没有就去找对应的beanDefinition,那里面在扫描过程中有把Class实体存进去,那么直接instanceOf就知道合不合要求了。 -
下一步就是去遍历Spring启动的时候会放入写实体放到
resolvableDependencies下,就是这些类型的话也是可以被注入的,我所说的有如下几个:- beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
beanFactory.registerResolvableDependency(ResourceLoader.class, this);
beanFactory.registerResolvableDependency(ApplicationEventPublisher.class, this);
beanFactory.registerResolvableDependency(ApplicationContext.class, this);
- beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
-
对注入的不是自己再度进行筛选,通过的
isAutowireCandidate方法,这里用了责任链的设计模式,下面会再度概述这点。 -
如果筛选到最后没一个符合的,就会去判断是否引用的自己,是的话放入返回的结果集中。

isAutowireCandidate 源码分析
这个是 findAutowireCandidates 中的第三点,前俩点主要是找可以注入的实体,只有第三点是会进行再次筛选。
isAutowireCandidate 这个方法是一个重载方法,只有它返回为true,才会尝试放入返回结果集中,我们直接看最核心的这个方法。 看来看去最后是以
看来看去最后是以 AutowireCandidateResolver#isAutowireCandidate 为返回结果:
在分析之前,还是得看一下这个关系图; 源码中所使用的 AutowireCandidatesResolver 实体就是
源码中所使用的 AutowireCandidatesResolver 实体就是 QualifierAnnotationAutowireCandidateResolver 实体对象,接下来咱就看看它的 #isAutowireCandidate 的实现: 它首先是去父类的筛选,若父类筛选不通过的话就直接返回FALSE了,不会执行if里的代码。
它首先是去父类的筛选,若父类筛选不通过的话就直接返回FALSE了,不会执行if里的代码。
而 if 里面的代码就是对 @Qualifier 注解(限定符)的筛选,若原实体和注入字段上有@Qualifier注解就去比对里面的Value值。
父类 GenericTypeAwareAutowireCandidateResolver 解析也是一样,先交给父类,然后再尝试自己执行,这个是去解析泛型的,一点复杂,不解析了。
 再往上的话就是 SimpleAutowireCandidateResolver 去解析了,就是判断BeanDefinition中的autowireCandidate是不是为true,默认是true的,允许注入:
再往上的话就是 SimpleAutowireCandidateResolver 去解析了,就是判断BeanDefinition中的autowireCandidate是不是为true,默认是true的,允许注入:
 这是典型的责任链设计模式,其中执行流程是 SimpleAutowireCandidateResolver -》GenericTypeAwareAutowireCandidateResolver -》QualifierAnnotationAutowireCandidateResolver,没前一步都影响后续的执行,相比过滤器那种它只是没有前置处理,也不需要。
这是典型的责任链设计模式,其中执行流程是 SimpleAutowireCandidateResolver -》GenericTypeAwareAutowireCandidateResolver -》QualifierAnnotationAutowireCandidateResolver,没前一步都影响后续的执行,相比过滤器那种它只是没有前置处理,也不需要。
测试
对上面的三种过滤形式进行个简单测试好理解:
SimpleAutowireCandidateResolver 主要是去判断 autowireCandidate 是不是为true。
下面我把 autowireCandidate 设置为了 FALSE,那么注入肯定会报错的(报错位置应该是在 doResolveDependency 中找不到对应注入实体,但是 required 又是true):
 然后就是 GenericTypeAwareAutowireCandidateResolver 解析器去对泛型的筛选,如下所示:
然后就是 GenericTypeAwareAutowireCandidateResolver 解析器去对泛型的筛选,如下所示:
public class BaseService<O, S> {
@Autowired
protected O o;
@Autowired
protected S s;
}
 BaseService 中定义了泛型,然后 UserService 继承了 BaseService 然后指定了泛型类型,这里就是对这个泛型类型进行筛选。由于这里是泛型,在起初 BeanFactoryUtils.beanNamesForTypeIncludingAncestors 得到的结果是所有的 beanNames,而这里就可以得到泛型类型的真正筛选。
BaseService 中定义了泛型,然后 UserService 继承了 BaseService 然后指定了泛型类型,这里就是对这个泛型类型进行筛选。由于这里是泛型,在起初 BeanFactoryUtils.beanNamesForTypeIncludingAncestors 得到的结果是所有的 beanNames,而这里就可以得到泛型类型的真正筛选。
打断点测试: 可以发现要注入的类型是 Object,而筛选出来的结果是所有的 beanName
可以发现要注入的类型是 Object,而筛选出来的结果是所有的 beanName
而那流程执行结束看结果:
最后输出: 而
而 QualifierAnnotationAutowireCandidateResolver 去解析@Qualifier我觉得开发过的对这个应该都不陌生的。
无非就是去标志一下,最后注入的时候需要比对一下:
比如下面提供几种负载均衡策略实体,然后通过注解自由注入例子:
@Target({ElementType.TYPE, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Qualifier("random")
public @interface Random {
}
@Target({ElementType.TYPE, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Qualifier("roundRobin")
public @interface RoundRobin {
}
public interface LoadBalance {
String select();
}
@Component
@Random
public class RandomStrategy implements LoadBalance {
@Override
public String select() {
return null;
}
}
@Component
@RoundRobin
public class RoundRobinStrategy implements LoadBalance {
@Override
public String select() {
return null;
}
}

 无非就是前后限定符的比对。
无非就是前后限定符的比对。
3. 根据类型找Bean没找着且required=true
// 找到所有Bean,key是beanName, value有可能是bean对象,有可能是beanClass
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
// required为true,抛异常
// 找不到对应的Bean,但是 required 又是 true,就会抛出异常,@Autowired 的 required 默认是 true 的
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
通过 findAutowireCandidates 要是没有找到结果集的话,就说明没有匹配的 Bean,那么这时required又是true,默认就是true,那么这时会抛出异常。
4. 寻找唯一Bean(普通注入)
现在就是我们最常见的注入了,就是普通的注入,前面奇奇怪怪的都被筛选光了。
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
// 根据类型找到了多个Bean,进一步筛选出某一个, @Primary-->优先级最高--->name
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
这里的话会先进行判断,若 findAutowireCandidates 返回的结果集是多个那就进行再处理,若是一个则没啥好说的,直接返回到时候反射赋值就是了。那咱就看看它多个的情况下又会做哪些处理吧,主要是在 determineAutowireCandidate 方法中。
这个方法实现不难,主要就是三层筛选,先@Primary,再@Priority,前俩者都没的话就根据名字了。
@Nullable
protected String determineAutowireCandidate(Map<String, Object> candidates, DependencyDescriptor descriptor) {
Class<?> requiredType = descriptor.getDependencyType();
// candidates表示根据类型所找到的多个Bean,判断这些Bean中是否有一个是@Primary的
String primaryCandidate = determinePrimaryCandidate(candidates, requiredType);
if (primaryCandidate != null) {
return primaryCandidate;
}
// 取优先级最高的Bean
String priorityCandidate = determineHighestPriorityCandidate(candidates, requiredType);
if (priorityCandidate != null) {
return priorityCandidate;
}
// Fallback
// 匹配descriptor的名字,要么是字段的名字,要么是set方法入参的名字
for (Map.Entry<String, Object> entry : candidates.entrySet()) {
String candidateName = entry.getKey();
Object beanInstance = entry.getValue();
// resolvableDependencies记录了某个类型对应某个Bean,启动Spring时会进行设置,比如BeanFactory.class对应BeanFactory实例
// 注意:如果是Spring自己的byType,descriptor.getDependencyName()将返回空,只有是@Autowired才会方法属性名或方法参数名
if ((beanInstance != null && this.resolvableDependencies.containsValue(beanInstance)) ||
matchesBeanName(candidateName, descriptor.getDependencyName())) {
return candidateName;
}
}
return null;
}
@Priority 注解的筛选要看一下,是以值越小优先级越高来判断的:
其它就没啥好说的。
四、总结
这简单做个小结吧,注意这里是和上一节是一起的:
- 这个属性注入呢考虑的是去遍历 InstantiationAwareBeanPostProcessor 中的属性注入方法调用,其中有个
AutowiredAnnotationBeanPostProcessor就是我们所分析的。 - 首先呢就是去遍历属性遍历方法寻找注入点,找到后封装成一个注入点实体存进集合中;
- 遍历这个集合依次进行注入,要是方法的话就参数遍历个遍去调用
doResolverDependency方法获取要注入的bean,最后合一起反射调用方法就是了,属性的话,更简单,获取后反射直接赋值。 - doResolveDependency逻辑:
- 先进行
@Value注解的注入; - 筛选
Map、Stream、Collection、数组这特殊类型; - findAutowireCandidates 去根据类型筛选Bean,其中筛选有 autowireCandidate 需要为 true,筛选泛型类型,筛选 @Qualifier 限定符匹配的。
- 若有多Bean需要注入还需要进行筛选:
@Primary-
@Priority(注意这里是值越小优先级越高,且值不能一样,不然抛异常的) - 属性名或者说是参数名和 beanName 匹配一个出来。
- 先进行
- 反射调用/反射赋值(完成依赖注入!!!)
筛选6步记住:@Value ---- autowireCandidate 元数据属性要为 true ----- @Qualifier 限定符若有需匹配 ------- 多Bean的话 @Primary --------@Priority ------属性名或者参数名匹配
下一篇的话把 @Resource 注解注入源码也分析一下,其实可以猜到,也得通过 InstantiationAwareBeanPostProcessor 中的属性注入方法的遍历。文章来源:https://www.toymoban.com/news/detail-824369.html
搞个流程图就像如下步骤一样: 文章来源地址https://www.toymoban.com/news/detail-824369.html
文章来源地址https://www.toymoban.com/news/detail-824369.html
到了这里,关于【Spring源码分析】从源码角度去熟悉依赖注入(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!









