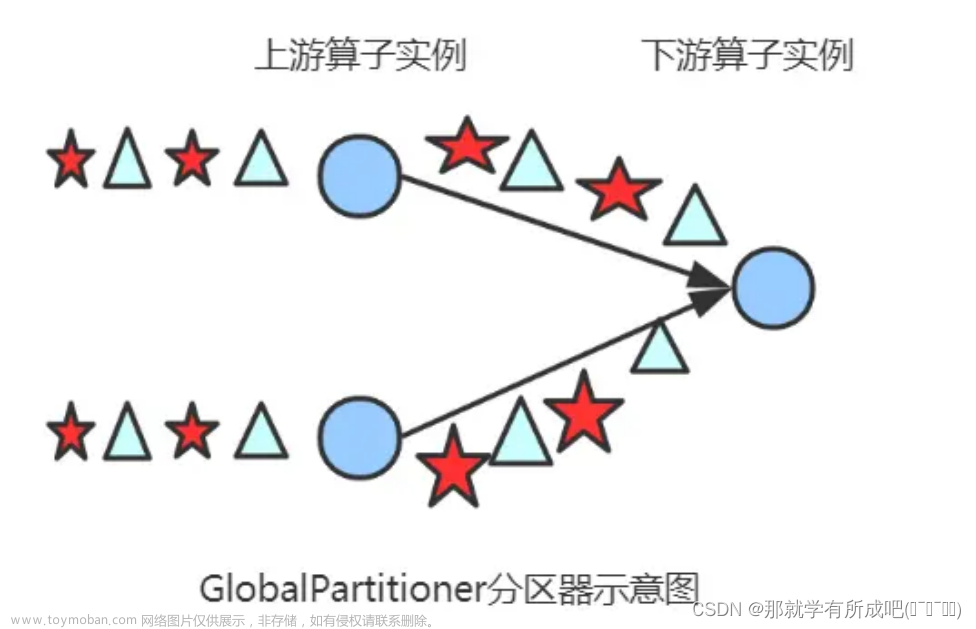
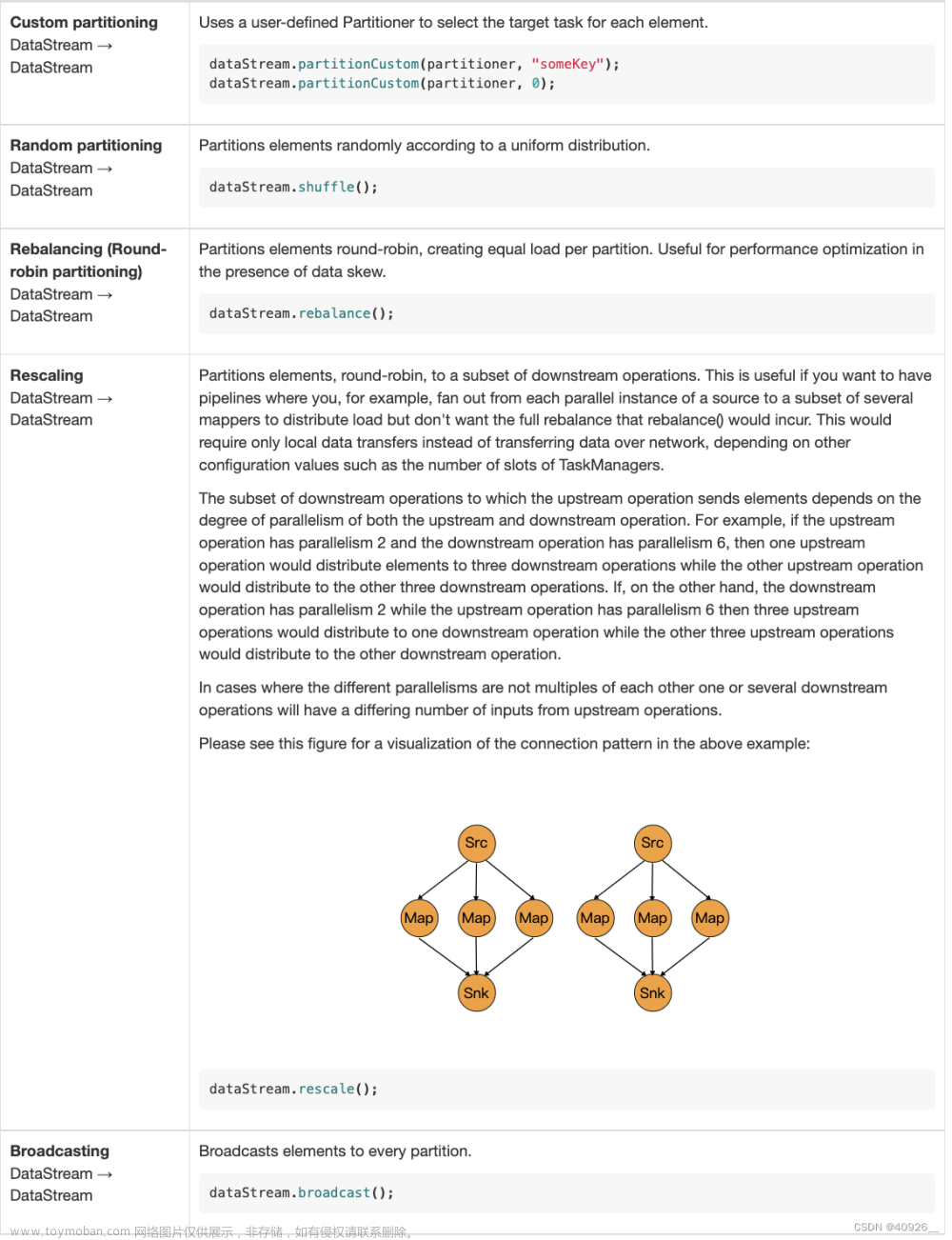
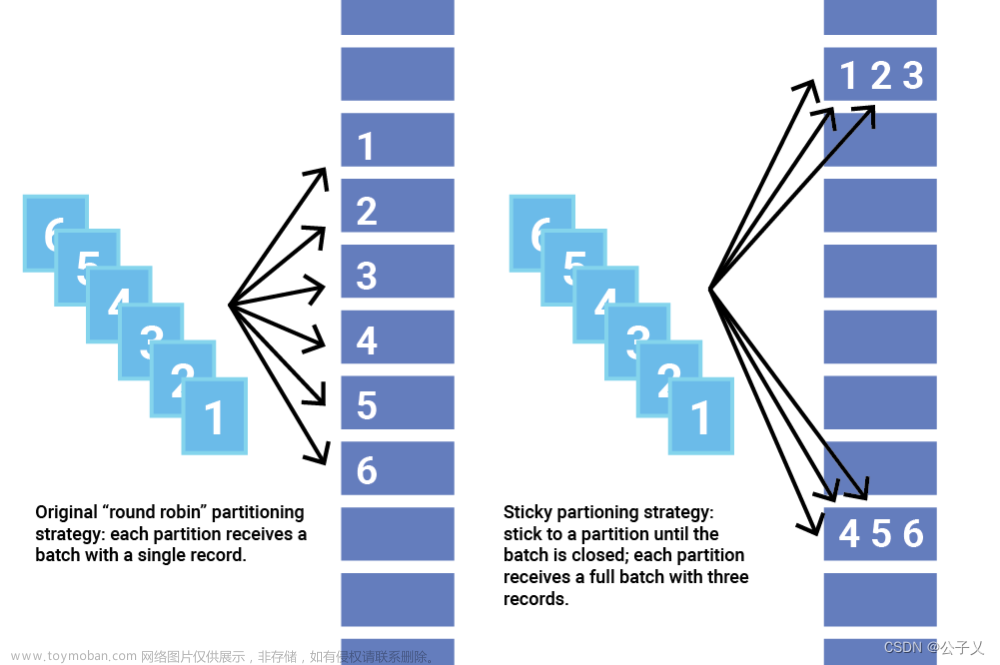
简介
在实际应用中,我们一般都需要将数据按照某个 key 进行分区,然后再进行计算处理;所
以最为常见的状态类型就是 Keyed State。之前介绍到 keyBy 之后的聚合、窗口计算,算子所
持有的状态,都是 Keyed State。
另外,我们还可以通过富函数类(Rich Function)对转换算子进行扩展、实现自定义功能,
比如 RichMapFunction、RichFilterFunction。在富函数中,我们可以调用.getRuntimeContext()
获取当前的运行时上下文(RuntimeContext),进而获取到访问状态的句柄;这种富函数中自
定义的状态也是 Keyed State。文章来源:https://www.toymoban.com/news/detail-824409.html
什么是Key State
按键分区状态(Keyed State)顾名思义,是任务按照键(key)来访问和维护的状态。它
的特点非常鲜明,就是以 key 为作用范围进行隔离。
在进行按键分区之后,具有相同键的所有数据,都会分配到同一个并行子任务中;所以如
果当前任务定义了状态,Flink 就会在当前并行子任务实例中,为每个键值维护一个状态的实
例。于是当前任务就会为分配来的所有数据,按照 key 维护和处理对应的状态。
在底层,Keyed State 类似于一个分布式的映射(map)数据结构,所有的状态会根据 key
保存成键值对(key-value)的形式。这样当一条数据到来时,任务就会自动将状态的访问范围
限定为当文章来源地址https://www.toymoban.com/news/detail-824409.html
到了这里,关于Flink状态编程之按键分区状态的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!