Spark写入(批数据和流式处理)
Spark写入kafka批处理
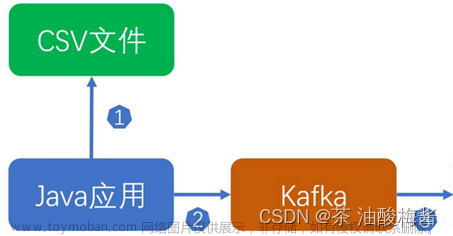
写入kafka基础
 文章来源:https://www.toymoban.com/news/detail-824540.html
文章来源:https://www.toymoban.com/news/detail-824540.html
# spark写入数据到kafka
from pyspark.sql import SparkSession,functions as F
ss = SparkSession.builder.getOrCreate()
# 创建df数据
df = ss.createDataFrame([[9, '王五', 21, '男'], [10, '大乔', 20, '女'], [11, '小乔', 22, '女']],
schema='id int,name string,age int,gender string')
df.show()
# todo 注意一:需要拼接一个value
# 在写入kafka时需要拼接一个value
df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'))
df_kafka.show()
# 将df写入kafka
# todo 注意二:这个和读取kafka时的配置是一样,不过这里应该是没有读取起始量和读取结束量
options = {
# 指定kafka的连接的broker服务节点信息
'kafka.bootstrap.servers': 'node1:9092',
# 指定写入主题
'topic': 'user'
}
df_kafka.write.save(format='kafka', mode='append', **options)
kafka写入策略
 文章来源地址https://www.toymoban.com/news/detail-824540.html
文章来源地址https://www.toymoban.com/news/detail-824540.html
# kafka数据写入策略
from pyspark.sql import SparkSession,functions as F
ss = SparkSession.builder.getOrCreate()
# 创建df数据
df = ss.createDataFrame([[200, '王五22222', 21, '男'], [201, '大乔22222', 20, '女'], [202, '小乔2222', 22, '女']],
schema='id int,name string,age int,gender string')
df.show()
# 在写入kakfa时需要拼接一个value
# # df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'),F.lit(1).alias('partition'))
# # df_kafka.show()
# 指定分区 增加一个分区字段
options = {
# 指定kafka的连接的broker服务节点信息
'kafka.bootstrap.servers': 'node1:9092',
# 指定写入主题
'topic': 'user',
}
# df_kafka.write.save(format='kafka', mode='append', **options)
# 指定key 会key进行hash计算,相同key的数据会写入同一分区
# hash(key)%分区数 =
# df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'),df.gender.alias('key'))
# df_kafka.show()
# 同时指定key和partition 按照分区写入
df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'),df.gender.alias('key'),F.lit(2).alias('partition'))
df_kafka.show()
df_kafka.write.save(format='kafka', mode='append', **options)
写入kafka应答响应级别
# spark写入数据到kafka
# 指定ack应答级别
from pyspark.sql import SparkSession, functions as F
ss = SparkSession.builder.getOrCreate()
# 创建df数据
df = ss.createDataFrame([[9, '王五', 21, '男'], [10, '大乔', 20, '女'], [11, '小乔', 22, '女']],
schema='id int,name string,age int,gender string')
df.show()
# 在写入kakfa时需要拼接一个value
df_kafka = df.select(F.concat_ws(',', df.id.cast('string'), df.name, df.age.cast('string'), df.gender).alias('value'))
df_kafka.show()
# 将df写入kafka
options = {
# 指定kafka的连接的broker服务节点信息
'kafka.bootstrap.servers': 'node1:9092',
# 指定写入主题
'topic': 'user',
# 指定级别
'acks':'all'
}
df_kafka.write.save(format='kafka', mode='append', **options)
Sprak写入kafka流式处理
到了这里,关于Spark写入kafka(批数据和流式)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!