目录
一、环境配置
1、安装anaconda或者miniconda进行环境的管理
2、安装CUDA
3、环境安装
二、配置加载模型
1、建立THUDM文件夹
三、遇到的问题
1、pip install -r requirements.txt
2、运行python web_demo.py遇到的错误——TypeError: Descriptors cannot not be created directly.
3、运行python web_demo.py遇到的错误——AttributeError: module 'numpy' has no attribute 'object'.
四、网页版Demo
基于Streamlit的网页版Demo
五、命令行Demo
六、总结
前言:ChatGLM2-6B 是开源中英双语对话模型ChatGLM-6B的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B拥有更强大的性能、更长的上下文、更高的推理和更开放的协议。
项目仓库链接:https://github.com/THUDM/ChatGLM2-6B
一、环境配置
1、安装anaconda或者miniconda进行环境的管理
安装链接:ubuntu安装Miniconda_Baby_of_breath的博客-CSDN博客
2、安装CUDA
Ubuntu 安装 CUDA11.3_计算机视觉从零学的博客-CSDN博客
3、环境安装
git clone https://github.com/THUDM/ChatGLM2-6B #下载仓库
cd ChatGLM2-6B #进入文件夹
#创建conda环境
conda create -n chatglm python==3.8
conda activate chatglm #进入创建的conda环境
#使用pip安装所需要的依赖项
pip install -r requirements.txt二、配置加载模型
1、建立THUDM文件夹
mkdir THUDM #在ChatGLM2-6B项目文件夹内建立
mkdir chatglm2-6b #将下载的模型和配置文件全部放入到这文件夹中
#文件位置浏览
/home/wxy/ChatGLM2-6B/THUDM/chatglm2-6b
然后在huggingface中将所有的模型文件和配置文件下载下来,建议手动下载然后放入到ChatGLM2-6B/THUDM/chatglm2-6b中。

三、遇到的问题
1、pip install -r requirements.txt
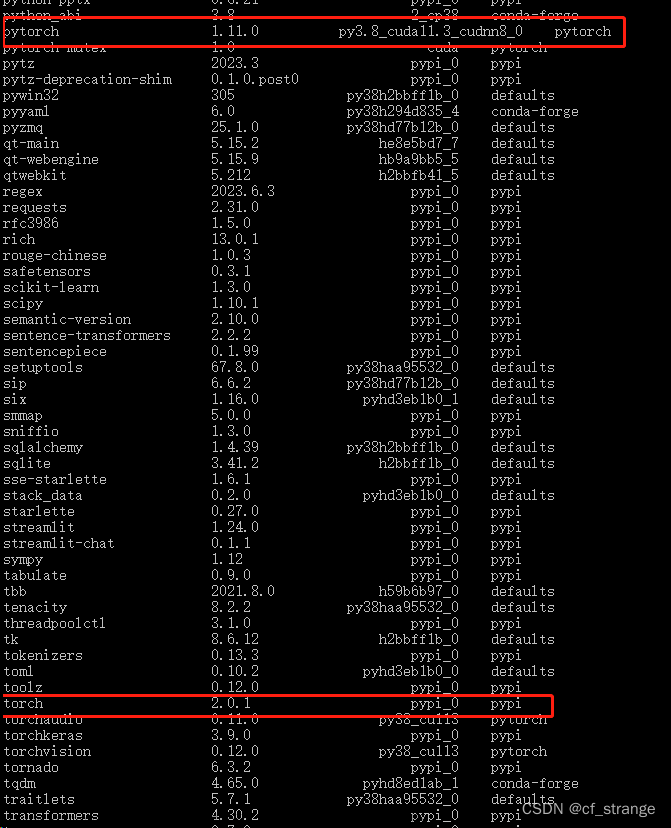
当pip安装requirements.txt时可能会遇到一些依赖项无法安装,如下图所示:

解决方法:直接pip缺少的依赖项
pip install oauthlib==3.0.0
pip install tensorboard==1.15
pip install urllib3==1.25.0
pip install requests-oauthlib==1.3.1
pip install torch-tb-profiler==0.4.1
pip install google-auth==2.18.0
2、运行python web_demo.py遇到的错误——TypeError: Descriptors cannot not be created directly.

出现上面截图的错误TypeError: Descriptors cannot not be created directly。表示protobuf 库的版本问题导致的。错误提示提到需要使用 protoc 的版本大于等于 3.19.0 重新生成代码。
解决方法:
pip uninstall protobuf #卸载protobuf
pip install protobuf==3.19.0 #重新安装3.19.0版本的
3、运行python web_demo.py遇到的错误——AttributeError: module 'numpy' has no attribute 'object'.

如果出现了AttributeError: module 'numpy' has no attribute 'object'这个错误,解决方案如下:
pip uninstall numpy #卸载numpy
pip install numpy==1.23.4 #安装numpy1.23.4
四、网页版Demo
首先安装 Gradio:
pip install gradio然后运行仓库中的web_demo.py,就可以显示如下web页面
python web_demo.py
基于Streamlit的网页版Demo

五、命令行Demo
运行仓库中的cli_demo.py,在终端中就会显示如下页面。程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear可以清空对话历史,输入 stop终止程序。
python cli_demo.py 文章来源:https://www.toymoban.com/news/detail-824552.html
文章来源:https://www.toymoban.com/news/detail-824552.html
六、总结
总体来说ChatGLM2-6B表现的效果还是十分出色的,推理的速度也是非常快,而且输出的篇幅比gpt要多还更有逻辑性,只不过在进行网页版demo和命令行demo的时候会占用很多的显存,因此也是比较消耗计算量的,大概占用了13GB的显存,但是仓库中也给出了低成本的部署,这一点还是比较人性化的。由于我使用的显卡是RTX3090,显存24GB所以我也就没有进行低成本的部署,感兴趣的可以去试一试。文章来源地址https://www.toymoban.com/news/detail-824552.html
到了这里,关于Ubuntu部署ChatGLM2-6B踩坑记录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!