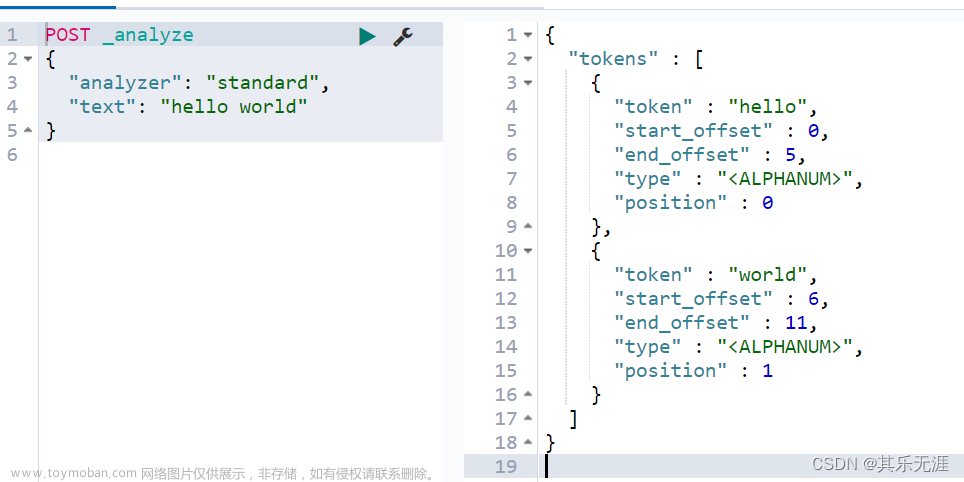
在大数据时代,搜索技术变得尤为重要。ElasticSearch作为一款强大的开源搜索引擎,提供了丰富的功能来满足各种搜索需求。其中,分词器是ElasticSearch中一个非常核心的概念,它决定了如何将用户输入的文本切分成一个个的词汇单元。
一、什么是分词器?
简单来说,分词器就是将文本切分成一个个词汇的功能。在中文语境下,分词的目的是将连续的汉字序列划分为一个个独立的词汇。例如,“我/爱/北京/天安门”中的“我”、“爱”、“北京”和“天安门”都是独立的词汇。
二、为什么需要分词器?
分词是搜索技术中的基础步骤。只有将文本切分成准确的词汇,搜索引擎才能正确理解用户的查询意图,从而返回准确的搜索结果。对于中文这样的非字母语言,分词的准确性尤为重要,因为中文的词汇之间没有明显的分隔符。
三、ElasticSearch的分词器种类
ElasticSearch提供了多种内置的分词器,每种分词器都有其特点和适用场景:
- Standard Analyzer:这是默认的分词器,适用于大多数情况。它会将文本切分成一系列的词素(token)。
- Whitespace Analyzer:这个分词器仅根据空白字符(如空格、换行等)来切分文本。
- Simple Analyzer:这个分词器会将文本切分成单个字符的token。
- Stop Analyzer:这个分词器会移除文本中的停用词(如“的”、“和”等常用词)。
- Keyword Analyzer:这个分词器会将文本视为一个整体,不进行任何切分。常用于需要精确匹配的场景。
- 语言特定制分析器(Language-specific analyzers):除了上述通用分词器外,ElasticSearch还针对各种语言提供了预制的分词器,如中文、阿拉伯语等。这些分词器通常基于特定的语言规则和词典进行分词。
四、如何选择合适的分词器?
选择合适的分词器取决于你的具体需求。例如,如果你需要处理英文文本,使用默认的Standard Analyzer通常就足够了。如果你需要处理中文文本,可以选择中文分词器(如IK Analyzer)来获得更好的分词效果。另外,如果需要更精细的控制,你可以创建自定义的分词器来满足特定的需求。
五、总结文章来源:https://www.toymoban.com/news/detail-824790.html
分词器是ElasticSearch中非常重要的组件,它决定了如何对文本进行基本的处理和切分。通过选择合适的分词器,你可以优化搜索的性能和准确性。了解和掌握各种分词器的特性和适用场景,对于有效地使用ElasticSearch至关重要。文章来源地址https://www.toymoban.com/news/detail-824790.html
到了这里,关于ElasticSearch分词器介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!