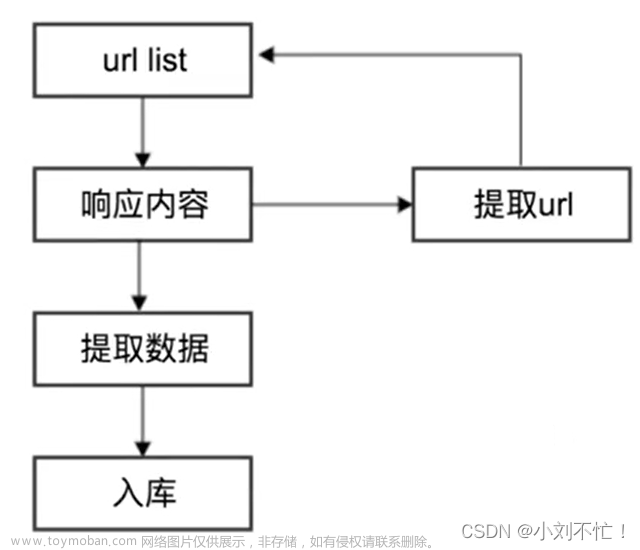
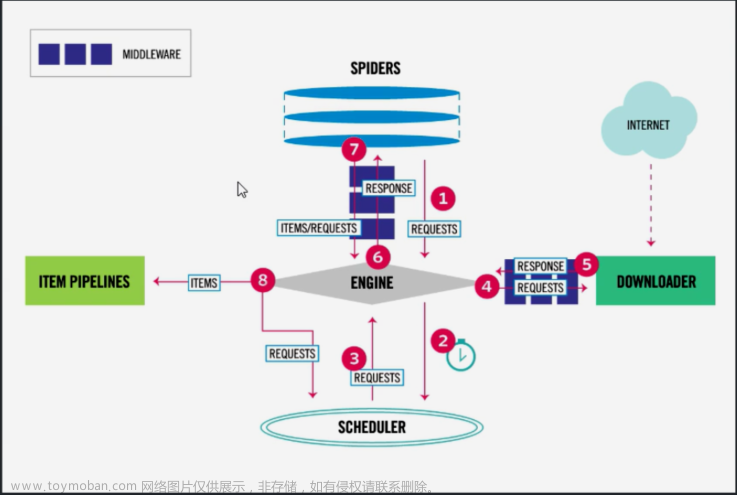
网络爬虫是一种计算机程序,它通过网络请求从不同的服务器收集和抓取信息,并存储在本地文件或数据库中。
网络爬虫的基本原理主要包含以下几个部分:
首先,选择爬行目标并获得初始URL,然后下载并解析这个URL,接着,根据提取出的新URL,继续进行重复下载和解析。爬虫可以按照一定的策略进行深度优先、广度优先等不同的方式,对原始URL进行遍历,并最终形成一个包括所有相关URL的网页网络。为了避免被目标网站禁止访问,爬虫会采取不同的反爬措施,如使用代理IP、加密等方式来进行隐藏。对于网站内容的提取,爬虫会采用不同的技术,例如正则表达式和XPath,以从网页中抓取特定信息。
最后,为了进行存储和分析,爬虫会将抓取到的信息存入本地文件或数据库中,并且进行一定的处理和分析,以找出其中的规律和模式。
网络爬虫的工作原理包括以下几个步骤:
首先,爬虫程序需要选择要爬行的目标网站,这可以通过爬虫程序从种子URL开始,逐步扩展到整个Web,从而扩大爬取范围和数量。
然后,爬虫程序会以一定的频率向目标网站发送网络请求,请求将可能包含爬虫程序设置的参数,如页面大小限制和代理IP地址等。当请求返回响应后,爬虫程序会解析响应,并从中提取所需信息。爬虫程序还需要记录下每个抓取到的URL,以便后续的爬行和分析。
此外,为了避免因频繁访问导致的被封锁,爬虫程序还需要采用代理IP或随机数等技术来隐藏其真实身份。
那么,如何选择爬虫技术的开发语言呢?
- 明确需求: 在决定选择哪种语言开发爬虫之前,需要明确爬虫的目标网站和数据类型。比如,有些网站的数据可能只支持某种特定的编程语言进行解析,因此在选择语言之前需要了解这些限制条件。
- 编程语言的特性和性能: 不同的编程语言有不同的特性和性能,需要根据项目的需求进行选择。例如,Python因其易学性、高效率和丰富的库而广泛应用于爬虫开发中。而C++可以提供更好的性能和更低的内存占用率,适用于大型爬虫。
- 学习成本和资源可用性: 选择爬虫技术的开发语言需要考虑学习成本和资源可用性。对于初学者,Python是一个不错的选择,因为它拥有丰富的文档和社区支持,易于上手。而对于经验丰富的开发者,可能更倾向于使用C++等语言,以获得更高的性能和灵活性。
- 项目的规模和复杂度: 爬虫技术的开发语言选择也需要根据项目的规模和复杂度进行考虑。对于小型项目,Python或其他脚本语言可能足够满足需求,而对于大型复杂项目,可能需要使用C++等高级语言。
因此,在选择爬虫技术的开发语言时,需要综合考虑需求、特性和性能、学习成本和资源可用性、项目规模和复杂度等因素。最终选择哪种语言,需要根据项目的实际情况和开发者的经验和技能进行权衡。
网络爬虫的常用工具包括:
Python的Scrapy、PyQuery、BeautifulSoup、Requests、urllib、urllib2、mechanize、WebClient和selenium等。其中,Scrapy是一个框架,用于实现爬虫的功能;PyQuery是一个库,用于解析HTML;BeautifulSoup和lxml是用来解析HTML的工具;Requests和urllib是用于发起HTTP请求的库;urllib2和mechanize是可以模拟浏览器行为的库;WebClient是一个可以发送GET请求的库;selenium是一个用于操作网页的库。
网络爬虫还需要遵循哪些规范和法律法规?
由于网络爬虫的爬行过程可能会对目标网站造成一定的压力,因此,对于爬虫程序的使用,需要遵循一定的道德规范和法律法规,如遵守robots.txt协议,不抓取网站的禁止抓取的信息,以及不滥用爬虫程序进行恶意攻击等。此外,在进行信息采集时,需要对目标网站的性能和负载进行合理评估,以避免导致网站瘫痪。同时,爬虫程序还需要对所抓取的信息进行合理的存储和处理,以避免信息的滥用或侵犯个人隐私。文章来源:https://www.toymoban.com/news/detail-824972.html
- 首先,我们需要明确爬取的目的,并确保这些目的合法。
- 其次,我们需要尊重目标网站的隐私和数据安全,避免侵犯他们的权益。
- 同时,我们也要遵循相关的技术和法律标准,以确保我们的爬虫行为合规。
此外,我们还需要关注法律和道德方面的问题,并及时与相关机构进行沟通和合作。这样,我们才能在网络爬虫的领域中稳步前行,同时保护所有相关方的权益。
总体来说,网络爬虫技术可以为人们提供巨大的数据信息,帮助我们更好地理解和使用网络资源。但同时,也需要对其进行有效的管理和监管,以确保网络的安全和稳定。文章来源地址https://www.toymoban.com/news/detail-824972.html
到了这里,关于网络爬虫基本原理的介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍](https://imgs.yssmx.com/Uploads/2024/02/580122-1.png)