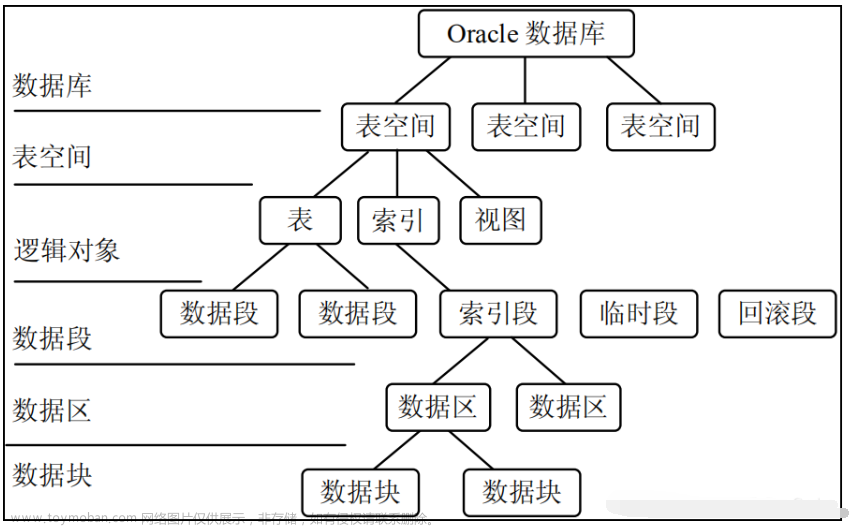
实验环境
sqlplus
记录实验过程的方法:
spool 带有绝对路径的文件名 [append]
--SQL语句
spool off
开启相关服务
oracleserviceORCL
- 控制面板–管理–服务–找到后开启
- 命令行方法: cmd–net start|stop oracleserviceorcl
常用操作
显示当前用户名
show user
常用的用户名和口令
:dba用户,默认口令:change_on_install,Oraclell,必须以sysdba或者sysoper身份登录
system: 普通管理员, 默认口令: manager.
| 用户名 | 身份 | 口令 | 备注 |
|---|---|---|---|
| sys | dba用户 | change_on_install,Oraclell | 必须以sysdba或者sysoper身份登录 |
| system | 普通管理员 | manager | |
| scott | tiger | 默认是锁定状态,需要解锁使用。 | |
| sh | sh | 含有大量的数据。 |
进入sqlplus环境的步骤
- 开启相关服务
- cmd-sqlplus
- 输入用户名和口令: sys/Oracle11 as sysdba
- show user
- 解锁scott用户: alter user scott identified by tiger account unlock
- 切换到scott用户: connect username/password [as sysdba]
- connect scott/tiger
- show user
SQL语句分类
DQL: 数据查询语言
select
-
select * from tablename;
-
--*代表许所有属性 select * from tablename; --查看当前用户有哪些对象 select * from tab; --查看特定表的属性有哪些? describe tablename;
-
-
查看表的特定属性的信息。多个属性之间用逗号分隔。
-
--查询所有员工的工号,姓名和参加工作时间。 select empno,ename,hiredate from emp;
-
-
用distinct关键字去掉重复记录。
-
select distinct deptno from emp; select distinct deptno,sal,empno from emp;
-
-
用||连接运算符把多个结果连在一起。
-
--查询每个员工的工资,要求输出格式为: xxx员工的工资是:xxxx select ename||'员工的工资是:'||sal from emp; --注意:oracle是大小写不敏感的,但当字符型数据出现在条件表达式中时,必须严格区分大小分。 --条件查询:select from where 条件表达式;
-
where从句
-
简单比较运算符:>,<,>=,!=
-
--查询工资超过2000的员工的姓名。 select ename,sal from emp where sal>2000; --查询smith的工号、经理号和工资。 select empno,mgr,sal from emp where ename='SMITH';
-
-
逻辑运算符: not,and,or 优先级从高到低。
-
--查询20号部门工资超过2000的员工的姓名。 select ename,sal from emp where sal>2000 and deptno=20;
-
-
in运算符:取值是几个中的一个时,通常用in。
-
--20号30号部门 deptno=20 or deptno=30 or deptno=40 deptno not in(20,30,40)
-
-
between and.取值是一个连续的值域
-
--工资在2000到3000之间。 sal>=2000 and sal<=3000 sal between 2000 and 3000
-
-
is运算符
-
--空值:其不等于任何一个具体值。null,当其出现在算术、比较、逻辑等表达式中时,其结果永远为空。 2000+null,2000>null, 2000 and null --空值处理函数: nvl(a,b) --a为空,返回b,a非空,返回a. --奖金为空。 comm is null comm is not null --查询所有员工的工资、奖金和月收入. select ename,sal,comm,sal+nvl(comm,0) from emp;
-
-
模糊查询。like运算符。
-
引入两个通配符: _代表任意一个字符 % 任意个字符。
-
模糊查询的效率低下,可以用下列函数代替like运算符
-
length(ename)=5 not like '%R%' instr(a,b) instr('abbc','b',1,2)=2 3 instr(ename,'R')=0 instr(ename,'A')>0 substr
-
-
字符串数据用于条件中时,必须严格区分大小写,下列函数可以解决上述问题
-
initcap(ename)='Smith' lower upper
-
-
-
order by从句
--查询结果的排序:order by .
select from where order by; --默认是升序asc,可以用desc改为降序输出。
查询20号部门员工的姓名、参加工作时间和工资,按参加工作时间降序输出,若时间相同,则按工资升序输出。
select ename,hiredate,sal from emp where deptno=20 order by hiredate desc,sal asc;
select ename,hiredate,sal from emp where deptno=20 order by 2 desc,3 asc;
常用的数据类型:
数值型
(number(a,b),a代表总的有效数字位数,b为小数点后数字位数,score number(4,1))、
字符型
char(n),varchar2(n)
v_string1 char(10) ‘abc’
v_string2 varchar2(10)
Oracle中的日期型数据
日期型数据要用单引号括起来
默认格式: dd-mon-yy dd-mm月-yyyy
--2023年2月27日 '27-2月-2023'
--2023年2月参加工作
--当前时间的获得:
sysdate
--查看系统当前时间:
select sysdate from dual;
--工龄计算:
(sysdate-hiredate)/365
select ename,sysdate-hiredate from emp;
计算工龄的方式
(sysdate-hiredate)/365
months_between(a,b) months_between(sysdate,hiredate)/12
to_char(sysdate,'yyyy')-to_char(hiredate,'yyyy')
用to_char提取日期型数据信息。
to_char(日期型数据,'format') format: yyyy,mm,ddd,dd,d,hh,hh24,mi,ss
select to_char(sysdate,'yyyy-mm-dd hh:mi:ss') from dual;
to_char(hiredate,'yyyy')='1981'
to_char(hiredate,'yyyy-mm')='1981-02'
函数
单行函数,分组函数(聚集函数)
分组函数
count,max,min,avg,sum
- 只有一个函数的参数可以是*,count(empno)
- 有两个函数的参数要求必须是数值型: avg,sum
- 分组函数可以出现在select从句、having从句和order by从句。
查询emp表有多少条记录
select count(*) from emp;
查询20号部门员工的平均工资.
select avg(sal) from emp where deptno=20;
查询每个部门员工的平均工资.
select deptno,avg(sal) from emp group by deptno;
--一分为二:
select deptno from emp;
--14个dept可以称为单值列.
select avg(sal) from emp; 1个
当查询中既有单值列,又有分组函数时,所有出现在的单值列必须作为分组列。分组用group by引导。
查询部门员工平均工资超过2000的部门号和其平均工资.
--对于分组后的结果进一步筛选,需要使用having子句。
select deptno,avg(sal) from emp group by deptno having avg(sal)>2000 ;
where和having .having是随着group by的出现而出现的,其不能单独使用,除带有分组函数的条件出现在having子句中,其余条件出现在where从句中。
查询20、30号部门员工的平均月收入,输出平均月输入超过3500的部门号和平均月收入,要求按平均月收入降序输出,若平均月收入相同,则按部门号升序输出。
select deptno,avg(sal+nvl(comm,0)) from emp where deptno in(20,30) group by deptno having avg(sal+nvl(comm,0))>3500 order by avg(sal+nvl(comm,0)) desc, deptno; --效率高。
select deptno,avg(sal+nvl(comm,0)) from emp group by deptno having avg(sal+nvl(comm,0))>3500 and deptno in(20,30) order by avg(sal+nvl(comm,0)) desc, deptno;
小结: 简单查询; select from where group by having order by;
从from指定的表中筛选出满足where从句的记录,按照group by 分组列进行分组,并计算分组函数的值,再根据having子句对分组后的结果进一步筛选,按照order by 指定的排序列对查询结果进行排序输出。
查询的集合运算
并运算 union all| union , 交运算 intersect,差运算 minus
select distinct deptno from emp; --10 20 30
select distinct deptno from dept; --10 20 30 40
select distinct deptno from emp
union all
select distinct deptno from dept; --10 20 30 10 20 30 40
union: --10 20 30 40
intersect:10 --20 30
minus: --40
rownum
伪列,作用是给输出加行号。当其出现在where子句中时,其值总是从1开始。
查询emp表的第4、第6条记录
(select rownum,empno,ename,sal from emp where rownum<5
minus
select rownum,empno,ename,sal from emp where rownum<4)
union
(select rownum,empno,ename,sal from emp where rownum<7
minus
select rownum,empno,ename,sal from emp where rownum<6);
if else功能。
-
decode函数
-
decode(a,b,c,d) if a=b return c else return d decode(a,b,c,d,e,f,g) if a=b return c elseif a=d return e elseif a=f return g
-
-
case语句
-
--简单case语句 case 表达式 when value1 then return1 when value2 then return2 ...... else return N end --搜索case语句 case when 条件表达式1 then return1 when 条件表达式2 then return2 ...... else return N end
-
查询每个部门的名称,若部门名为accounting,则显示财务处,若部门名为sales,显示销售部,否则显示其它部门。
--decode函数
select dname,decode(lower(dname),'accounting','财务处','sales','销售部','其它部门') from dept;
--简单case语句
select dname, case lower(dname) when 'accounting' then '财务处'
when 'sales' then '销售部'
else '其它部门'
end from dept;
--搜索case语句
select dname, case when lower(dname)='accounting' then '财务处'
when lower(dname)= 'sales' then '销售部'
else '其它部门'
end case from dept;
别名
列别名,表别名
列别名:列名 空格 别名 ;列名 as 别名, 列别名可以出现在select 从句和order by 从句中。
select deptno 部门号,avg(sal+nvl(comm,0)) 平均月收入 from emp where deptno in(20,30) group by deptno having avg(sal+nvl(comm,0))>1500 order by 平均月收入 desc, deptno;
表别名: 表名 空格 别名 。表别名一经定义,在该查询中只能使用别名,不能使用原名。
连接查询
通常需要书写连接条件,N个表连接至少需要N-1个连接条件。分为内连接和外连接。
查询所有员工的工号empno、姓名 ename 和所在部门名称 dname 。
select empno,ename,dname from emp,dept;
内连接: 只输出满足连接条件的记录。又分为等值连接、不等连接、自连接。
等值连接: 要连接的两个表之间存在公共列(列的数据类型和宽度一致),连接条件: table1.公共列列名=table2.公共列列名 emp.deptno=dept.deptno
select empno,ename,dname from emp,dept where emp.deptno=dept.deptno;
select empno,ename,deptno,dname from emp,dept where emp.deptno=dept.deptno;--二义性问题
要避免二义性问题的出现:建议: 给出现的每个属性列都添加归属对象。
select emp.empno,emp.ename,emp.deptno,dept.dname from emp,dept where emp.deptno=dept.deptno;
select e.empno,e.ename,e.deptno,d.dname from emp e,dept d where e.deptno=d.deptno;
不等连接:没有公共列。 salgrade(grade, losal,hisal)
查询每个员工的工资等级
select e.ename,e.sal,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal;
自连接: 数据来源于同一个表。
查询每个员工的经理名。
select e.ename 员工名,m.ename 经理名 from emp e, emp m where e.mgr=m.empno;
除满足连接条件的记录要输出外,部分不满足连接条件的记录也要输出,此时需要用外连接。外连接在oracle 中引入外连接运算符(+),该运算符添加到信息缺失方。外连接分为左外连接、右外连接和全外连接。
查询每个员工的经理名。
select e.ename 员工名,m.ename 经理名 from emp e, emp m where e.mgr=m.empno(+);
--左外连接,信息完整方e出现在连接条件的左边,所以是左外连接。
select e.ename 员工名,m.ename 经理名 from emp e, emp m where m.empno(+)=e.mgr;
--右外连接
查询哪些员工的工资比7788员工的工资高。
select ename from emp where sal>(select sal from emp where empno=7788);
子查询:一个查询a作为另外一个查询b的一部分,则a成为子查询,b成为主查询。子查询可以分为单行子查询、多行子查询、多列子查询和相关子查询。子查询可以出现在from从句、where从句和having从句中。
单行子查询: 子查询的返回值最多只有一个。使用简单比较运算符。
查询哪些部门的平均工资比7788员工的工资高。
select deptno,avg(sal) from emp group by deptno having avg(sal)>(select sal from emp where empno=7788);
多行子查询: 返回值有多个。这时需要使用多行子查询运算符。in,any,all,in单独使用,any,all需要与简单比较运算符结合使用。
查询比20号部门任一员工工资高的员工姓名。
select ename from emp where sal>any(select sal from emp where deptno=20);
>(select min(sal) from emp where deptno=20)
查询比20号部门任意员工工资高的员工姓名。
select ename from emp where sal>all(select sal from emp where deptno=20);
sal>max(sal)
查出哪些雇员的工资高于他所在的部门的平均工资。
select ename,sal from emp outer where sal>(select avg(sal) from emp inner where inner.deptno=outer.deptno); 相关子查询。 exists
select emp.ename,emp.sal from (select deptno,avg(sal) avgsal from emp group by deptno) a,emp where a.deptno=emp.deptno and emp.sal>a.avgsal;
查询emp表的第4、第6条记录
select * from (select rownum r,empno,ename,sal,hiredate from emp) where r in(4,6);
求薪水最高的第6到第10名雇员
select * from (select rownum r,empno,ename,sal,hiredate from emp order by sal desc) where r beween 6 and 10;
select * from (select rownum r,a.* from (select empno,ename,sal,hiredate from emp order by sal desc) a) b where r beween 6 and 10;
row_number() over()函数的用法:
row_number() over(order by column1) --把表中的数据按照column1进行排序后,输出对应的序号。
select row_number() over(order by sal desc) rank ,empno,ename,sal,hiredate from emp;
row_number() over(partition by column1 a order by column2)--把表中的数据按照column1列进行分组,在每个分组的内部按照column2排序后输出相应的序号。
select row_number() over(partition by deptno order by sal desc) rank ,deptno,empno,ename,sal,hiredate from emp;
DDL: 数据定义语言
如create ,alter,drop ,对数据库对象的增改删。table,view,index,sequence,user
表的管理
新建表
通过查询建表
-- create table tablename as select;
create table emp_bak as select * from emp;
select * from (select * from emp) emp_bak;
create table t_avgsal as select deptno,avg(sal) avgsal from emp group by deptno;
新建表
--create table tablename
--(columnname datatype [constraint_type],,,,,);
student(s_no,s_name,s_card,s_gender,s_birth)
create table student
(s_no char(11),
s_name varchar2(20),
s_card char(18),
s_gender char(2),
s_birth date);
保证表中数据的准确性:数据完整性。怎么实现完整性?可以通过约束、触发器、门电路等。
约束:直接添加到表上,向表中添加数据时会进行相应的完整性检查。
分类: 主键、唯一性、非空、检查、外键。
主键约束
primary key,约束名通常以PK_开头,约束列特点: 列值不能为空,不能重复。一个表最多有一个主键约束。
create table student
(s_no char(11) primary key,
s_name varchar2(20),
s_card char(18),
s_gender char(2),
s_birth date);
唯一性约束
unique,uk_开头。约束列特点: 列值不能重复。
create table student
(s_no char(11) primary key,
s_name varchar2(20) unique,
s_card char(18),
s_gender char(2),
s_birth date);
非空约束
not null. 约束列特点: 列值不能为空值。
create table student
(s_no char(11) primary key,
s_name varchar2(20) unique not null,
s_card char(18) not null,
s_gender char(2),
s_birth date);
检查约束
check(包含约束列的条件表达式),ck_开头. 约束列特点: 列值需要满足指定条件。
create table student
(s_no char(11) primary key,
s_name varchar2(20) unique not null,
s_card char(18) not null,
s_gender char(2) check(s_gender in('男','女')),
s_birth date);
--s_gender可以为空值
外键约束
foreign key(约束列) references 主表(引用列). 约束列列值特点: 列值在引用列范围内。
外键约束列和引用列的数据类型和宽度必须保持完全一致。引用列列值在主表中具有唯一性。
分析“ 未找到父项关键字”产生的原因。
create table test1( id char(4) primary key);
insert into test1 values(1);
insert into test1 values(2);
commit;
create table test2( id char(4) references test1(id));
insert into test2 values(3); --引用数据在主表中不存在。
create table test3( id char(3) references test1(id));
insert into test3 values(1); --外键约束列与引用列数据类型不匹配。
列级约束与表级约束
create table student
(s_no char(11) primary key, --列级约束
s_name varchar2(20) unique not null,
s_card char(18) not null,
s_gender char(2) check(s_gender in('男','女')),
s_birth date);
course(c_no,c_name,c_credit)
score(s_no,c_no,s_score)
create table score
(s_no char(11) references student(s_no) ,
c_no varchar2(20) references course(c_no) ,
s_score number(4,1),
primary key(s_no,c_no)); --表级约束
修改表
添加新列、删除已有列、修改已有列属性。
添加新列
alter table tablename add (列名 数据类型,,,,,);
给test1添加t_name列。
alter table test1 add (t_name varchar2(20));
删除已有列
(数据库运行时,删除表中的某个列会影响数据库的工作效率,慎用!!!)
alter table tablename drop column 列名;
修改已有列属性
alter table tablename modify 列名 新数据类型;
alter table test3 modify id char(4);
约束维护
约束的添加、删除等。
添加约束的语法:
alter table tablename add constriant constraint_name constraint_type(constraint_column,,,);
删除、禁用和启用约束:
alter table tablename drop|disable|enable constraint constraint_name;
create table test4(id char(5),name varchar2(20),gender char(2));
create table test5(id char(5));
--添加主键约束:
alter table test4 add constraint pk_test4_id primary key(id);
--给name添加唯一性约束。
alter table test4 add constraint uk_test4_name unique(name);
--给gender添加检查约束,m,f
alter table test4 add constraint ck_test4_gender check(gender in('m','f'));
--给test5.id添加外键约束。
alter table test5 add constraint fk_test5_id foreign key(id) references test4(id);
--给test5.id 添加非空约束。
alter table test5 modify id not null;
查看约束信息: 根据约束名查询约束的类型和约束列。
user_constraints,user_cons_columns
DML: 数据修改语言
如insert,update,delete. 数据库表中记录的增、改、删。
insert
形式一: insert into tablename(column_name,) values(value1,);一次只能加一行。
create table student
(s_no char(11) primary key, --列级约束
s_name varchar2(20) unique not null,
s_card char(18) not null,
s_gender char(2) check(s_gender in('男','女')),
s_birth date);
--添加一条完整信息(1,'aa','111','男',1981-1-1)
insert into student(s_no,s_name,s_card,s_gender,s_birth) values('1','aa','111','男','1-1月-1999');
insert into student(s_name,s_card,s_no,s_gender,s_birth) values('bb','222','2','女','1-2月-1998');
insert into student values('1','aa','111','男','1-1月-1981');
insert into student(s_no,s_name,s_card) values('3','ccc','333');
形式二:可以一次添加多行。insert into tablename(column_name,) select;
(4,ddd,444) (5,eee,555) (6,fff,666)
insert into student(s_no,s_name,s_card)
select '4','ddd','444' from dual
union
select '5','eee','555' from dual
union
select '6','fff','666' from dual;
update
update tablename set columnname=新值,[where条件];
给所有员工提薪20%
update emp set sal=sal*1.2 ;
给20号部门所有员工提薪20%
update emp set sal=sal*1.2,comm=300 where deptno=20;
delete
delete from tablename [where];
delete from emp;
delete from emp where deptno=20;
删除数据方法的比较:
delete from table [where];-- 一条一条的删除。可以实现有选择的删除数据。该方法是可逆的。
truncate table tablename;--截断表。一次性把表中的所有数据删除掉,但表仍然存在。不可逆。
drop table tablename;--删除表。把表和数据一次性删除。从oracle10g开始,该方法可逆。
drop
drop table tablename;
回收站:
recyclebin. drop table --把表放到回收站中,而不是直接从数据库中删除。这时可以从回收站中还原误删的表。
查询回收站中的信息–回收站中的表名对应表原名。
select object_name,original_name from recyclebin;
还原回收站中的表: 闪回
flashback table test to before drop;
清空回收站
purge recyclebin;
删除时不使用回收站
drop table tablename purge;
DCL: 数据控制语言
如commit,rollbac,grant,revoke
事务:事务中的所有操作,要么全部成功,要么全部失败。每一个DML语句都不是一个完整的事务,必须要有一个确认过程(确认提交commit或者确认撤销rollback).每个DDL语句都是一个完整的事务。
视图
视图:view。本质就是一个虚表,其不包含任何数据,所有数据来源于创建视图的基表。
视图带来的好处:简化编程,保护了基表数据。
新建视图
create [or replace] view view_name
as select
[with read only]
[with check option];
scott用户没有权限创建视图,需要管理员授权
conn sys/Oracle11 as sysdba
grant create view to scott;
conn scott/tiger
create view view1 as select item.itemid,location,itemname,mark,sporterid,row_num
ber() over(partition by location,itemname order by item.itemid,mark desc) rank
from item,grade where item.itemid=grade.itemid;
select * from view1;
创建一个视图,查询每个部门的平均工资。
create view view_avgsal as select deptno,avg(sal) avgsal from emp group by deptno;
创建一个视图,查询20号部门所有员工的工号、姓名和参加工作时间。
create view view_20 as select empno,ename,hiredate from emp where deptno=20;
create view view_30 as select empno,ename,hiredate,deptno from emp where deptno=30 with read only;
with check option的作用
向视图中添加的数据必须满足创建视图时对应的子查询指定的where条件。
create or replace view view_30 as select empno,ename,hiredate,deptno from emp where deptno=30 with check option;
insert into view_30 values(1112,'aa',sysdate,30);
insert into view_30 values(1113,'bb',sysdate,20);
对视图进行DML操作:
向view_20添加一条
insert into view_20 values(1111,'asa',sysdate);
insert into view_avgsal --不能执行。
删除视图
drop view view_name;
索引
索引:提高查询效率。有没有必要给表的每个列都创建索引?因为索引需要维护,所以索引不是越多越好。
什么样的列适合建索引?列值重复率低的列。主键约束列和唯一性约束列系统自动创建唯一性索引。表的记录数(<100)少的没必要建立索引。
索引创建后,由系统确定是否使用索引,作为程序员来说,应最大限度的保证索引列按顺序出现在where子句中。
创建索引
create unique index index_name on tablename(列名,,,);
在emp.ename列创建一个降序索引。
create index idx1 on emp(ename desc); --普通索引
create unique index idx2 on emp(ename desc); --唯一性索引
create index idx3 on emp(lower(ename)); --基于函数的索引。
create index idx4 on emp(ename desc,sal,deptno); --复合索引
重建索引
先drop,再create.
alter index index_name rebuild;
user_indexes
序列号
自动生成序号。通常用于主键约束列列值得自动生成。
创建序列号
--create sequence sequence_name;
create sequence seq1;
--create sequence sequence_name start with m increment by n;
create sequence seq2 start with 2 increment by 2;
create sequence sequence_name
start with m
increment by n
minvalue A
maxvalue B
cycle|nocycle
cache C;
使用序列号
两个伪列: currval,nextval 序列名.currval,序列号初次使用,必须用nextval初始化。
序列号用于主键约束列的自动生成。
create table test(id number(100) primary key);
insert into test values(seq1.nextval);
user_sequences
用户管理
创建、修改和删除用户。在管理员下完成的。
oracle数据库的工作模式: 一个数据库—多个用户–每个用户下都有自己的数据
SQL Server工作模式: 一个用户–多个数据库–每个数据库都有自己的数据
创建用户
--create user username identified by password [account unlock|lock];
create user test identified by oracle;
授予相应权限,让test用户能够建立自己的对象并有相应的数据。
修改用户
alter user username identified by password account unlock|lock;
删除用户
drop user username;
权限管理
权限分为系统权限和对象权限。
系统权限
对数据库进行操作的能力。常见: create table,create session,create view,create any table,drop any table…。系统权限的管理通常由超级管理员完成。
系统权限的授权
--grant 系统权限名,,, to username,,,[with admin option];
conn sys/Oracle11 as sysdba
grant create session,create table to test; --普通授权
grant create session,create table to test with admin option; --级联授权
grant unlimited tablespace to test;
sys(create session,create table) test--test1
系统权限的回收
系统权限的回收不具有级联性
--revoke 系统权限名,,, from username,,,;
conn sys/Oracle11 as sysdba
revoke create table,create session from test;
对象权限
对数据库对象(表,函数,存储过程)进行操作的能力。select,insert,update,delete,execute. 对象权限由对象的所有者进行管理。
对象权限的授权
--grant 对象权限名 on 对象名 to username [with grant option];
--给test用户查询dept表的权限。
conn scott/tiger
grant select on dept to test;
grant select on dept to test with grant option;
conn test/oracle
select * from scott.dept;
scott(select on dept) test test1
对象权限的回收
对象权限的回收具有级联性。
--revoke 对象权限名 on 对象名 from username;
conn scott/tiger
revoke select on dept from test
跟权限相关的有关视图:
user_sys_privs
(可以查询系统权限信息)
user_tab_privs
(对象权限信息)
角色管理
role,提升权限管理的效率。默认角色: connect, resource,sysdba,sysoper,dba
grant connect to test;
需求: 给100个用户授予100个权限,一次只能给一个用户授予一个权限。
不使用角色: 100*100=10000
使用角色: 先创建一个角色,把100个权限授予角色(100),给角色授予100个用户(100),100+100=200
数据库编程
数据库编程要在屏幕上看到结果,需要开启屏幕打印。
set serveroutput on
PL/SQL procedure language.
从一个简单的程序看起:hello world!
begin
dbms_output.put_line('hello world!');
end;
/
块
未命名块:编译和执行都在客户端完成,只能短时存储。
命名块: 编译和执行都在服务器端完成,执行完在不删除的情况下永久性存在。存储过程、函数、包、触发器
快的组成
声明部分
变量、常量、游标、自定义数据类型等. declare
执行部分
块的主要功能的实现。 begin
异常处理部分
对于程序中可能出现的错误进行预处理。a/b exception
declare
begin
exception
end;
begin
end;
SQL哪些语句可以出现在块中?
select(select from )可以出现,但是以select into(select into from )的形式出现,这时查询的返回值只能有一行;DML可以直接出现;DDL不可以出现。
声明变量
变量名 数据类型 [:=初值| default 默认值];
数据类型
number(a,b),date,char,varchar2,boolean(true,false,null). LOB(大对象数据类型)
普通变量的声明建议以v_开头。
写一个PL/SQL程序,输出7788员工的姓名。 要求输出形式为:xxx员工的姓名:xxx
select ename from emp where empno=7788;
declare
v_ename varchar2(10);
begin
select ename into v_ename from emp where empno=7788;
dbms_output.put_line('7788员工的姓名:'||v_ename);
end;
/
块中的DBMS_OUTPUT的解释:这是系统的输出包,里边包含了3个常用的输出函数:
put_line(a):参数a是字符型,作用是输出a的值并换行。
put(a);作用是输出a值不换行。
new_line:作用是输出一个新行
替代变量作用是当程序运行时,从键盘接收数据。 &变量名
declare
v_ename varchar2(10);
v_empno number(4);
begin
v_empno:=&v_empno;
select ename into v_ename from emp where empno=v_empno;
dbms_output.put_line(v_empno||'员工的姓名:'||v_ename);
end;
/
定义一个变量,与已有变量或者表中某个属性列的数据类型保持一致。 %type 表名.列名%type
declare
v_ename emp.ename%type;
v_empno emp.empno%type;
begin
v_empno:=&v_empno;
select ename into v_ename from emp where empno=v_empno;
dbms_output.put_line(v_empno||'员工的姓名:'||v_ename);
end;
/
写一个PL/SQL程序,输出7788员工的姓名、参加工作时间、工资、部门号、奖金。
declare
v_ename emp.ename%type;
v_hiredate emp.hiredate%type;
v_sal emp.sal%type;
v_deptno emp.deptno%type;
v_comm emp.comm%type;
begin
select ename,hiredate,sal,deptno,comm into v_ename,v_hiredate,v_sal,v_deptno,v_comm from emp where empno=7788;
dbms_output.put_line(v_ename||' '||v_hiredate);
end;
/
emp(empno,ename,hiredate,sal,deptno,comm,,)--记录类型record
声明一个记录变量,与已有记录或者表的结构保持一致。rec_ 记录变量名 表名%rowtype;
declare
declare
rec_emp emp%rowtype;
begin
select * into rec_emp from emp where empno=7788;
dbms_output.put_line(rec_emp.ename||' '||rec_emp.hiredate);
end;
/
存储过程
属于命名块的一种,其没有返回值。
创建存储过程
create procedure
create [or replace] procedure procedure_name[(参数1 参数类型 参数数据类型,,,)]
as|is
变量声明;
begin
exception
end;
写一个PL/SQL存储过程,输出员工的工号、姓名、参加工作时间。
select empno,ename,hiredate from emp;
create or replace procedure proc1
as
cursor cur1 is select empno,ename,hiredate from emp;
v_empno emp.empno%type;
v_ename emp.ename%type;
v_hiredate emp.hiredate%type;
begin
open cur1;
loop
fetch cur1 into v_empno,v_ename,v_hiredate;
exit when cur1%notfound;
dbms_output.put_line(v_empno||' '||v_ename||' '||v_hiredate);
end loop;
close cur1;
end;
查看出现的错误
show errors
调用方法
块调用
begin
proc1;
end;
execute调用
execute proc1;
带有参数的存储过程:参数类型: in ,out, in out
带有输入参数的存储过程
写一个PL/SQL存储过程,输出特定员工的姓名和参加工作时间。
create or replace procedure proc2(v_empno emp.empno%type)
as
v_ename emp.ename%type;
v_hiredate emp.hiredate%type;
begin
select ename,hiredate into v_ename,v_hiredate from emp where empno=v_empno;
dbms_output.put_line(v_empno||'的姓名:'||v_ename||' '||'参加工作时间:'||v_hiredate);
exception
when no_data_found then
dbms_output.put_line(v_empno||'不存在');
end;
begin
proc2(v_empno=>7788);
end;
/
execute proc2(7788);
带有输出参数的存储过程
写一个PL/SQL存储过程,输出特定员工的姓名,要求用输出参数输出姓名。
create or replace procedure proc3(v_empno in emp.empno%type,v_ename out emp.ename%type)
as
begin
select ename into v_ename from emp where empno=v_empno;
-- dbms_output.put_line(v_empno||'的姓名:'||v_ename);
exception
when no_data_found then
dbms_output.put_line(v_empno||'不存在');
end;
--调用proc3: 对于参数传递,输入参数传递一个具体值,输出参数传递一个变量名。
declare
v_ename1 emp.ename%type;
begin
proc3(7788,v_ename1);
dbms_output.put_line(v_ename1);
end;
--execute调用:
execute proc3(7788,v_ename1);
结合变量
variable 变量名 数据类型; --不能使用%type,%rowtype
variable v_ename1 varchar2(20);
execute proc3(7788,:v_ename1);
print :v_ename;
grant execute on proc1 to username;
函数和包
编写一个PL/SQL过程,统计dept表的部门个数。
create or replace procedure proc1
as
v_count int;
begin
select count(*) into v_count from dept ;
dbms_output.put_line(v_count);
end;
/
begin
proc1;
end;
/
execute proc1;
函数
有且仅有一个返回值。
创建函数
create [or replace] function function_name[(参数1 参数类型 参数数据类型,,,)] return 函数返回值类型 --函数返回值类型不需要指定宽度
as|is
变量声明;
begin
return 表达式;
exception
return 表达式;
end;
编写一个PL/SQL函数,返回dept表的部门个数。
create or replace function fun1
return number
as
v_count int;
begin
select count(*) into v_count from dept ;
return v_count;
end;
/
调用
--(1)块调用
begin
dbms_output.put_line(fun1);
end;
--(2)execute调用
variable v_count1 int;
execute :v_count:=fun1;
print :v_count1;
--(3)select调用
select sysdate from dual;
select lower('AAA') from dual;
select fun1 from dual;
存储过程和函数调用: 存储过程没有返回值,在调用时不能作为其他任何表达式的一部分;函数有且仅有一个返回值,在调用必须作为其它表达式的一部分。
带有输入参数的函数的使用
写一个PL/SQL函数,返回特定员工的姓名。
create or replace function fun2(v_empno emp.empno%type)
return emp.ename%type
as
v_ename emp.ename%type;
begin
select ename into v_ename from emp where empno=v_empno;
return v_empno||'的姓名:'||v_ename;
exception
when no_data_found then
return v_empno||'不存在';
end;
/
---调用fun2:
select fun2(7788) from dual;
begin
dbms_output.put_line(fun2(7788));
end;
variable v_ename1 varchar2(30);
execute :v_ename1:=fun2(7788)l;
print :v_ename1;
包
对象的集合。 创建和使用包
包的头部
create or replace package package_name
as
包的公有成员(变量、游标、存储过程、函数,,,)的声明;
end;
包的实现
create or replace package body package_name
as
公有成员的实现;
私有成员的实现;
end;
生成一个pack1,包含proc1和fun1两个对象。
--pack1的头部:
create or replace package pack1
as
procedure proc1;
function fun1 return number;
end;
/
--pack1的实现:
create or replace package body pack1
as
---proc2--- proc2属于包的私有成员。
procedure proc2
as
begin
dbms_output.put_line('hello package');
end;
----proc1的实现----
procedure proc1
as
v_count int;
begin
proc2;
select count(*) into v_count from dept ;
dbms_output.put_line(v_count);
end;
----fun1的实现----
function fun1 return number
as
v_count int;
begin
select count(*) into v_count from dept ;
return v_count;
end;
end;
/
流程控制语句
顺序、选择、循环
选择结构
if 语句
if 条件 then 处理1; end if;
if 条件 then 处理1; else 处理2; end if;
if 条件1 then 处理1; elsif 条件2 then 处理2;... else 处理N; end if;
查询特定员工的工资,若工资超过3000,显示高工资。
declare
v_sal emp.sal%type;
v_empno emp.empno%type;
begin
v_empno:=&v_empno;
select sal into v_sal from emp where empno=v_empno;
if v_sal>3000 then
dbms_output.put_line(v_empno||'高工资');
end if;
end;
/
查询特定员工的工资,若工资超过3000,显示高工资,否则显示低工资。
declare
v_sal emp.sal%type;
v_empno emp.empno%type;
begin
v_empno:=&v_empno;
select sal into v_sal from emp where empno=v_empno;
if v_sal>3000 then
dbms_output.put_line(v_empno||'高工资');
else
dbms_output.put_line(v_empno||'低工资');
end if;
end;
/
查询特定员工的工资,若工资超过3000,显示高工资;在2000到3000之间,显示一般工资;否则显示低工资。
declare
v_sal emp.sal%type;
v_empno emp.empno%type;
begin
v_empno:=&v_empno;
select sal into v_sal from emp where empno=v_empno;
if v_sal>3000 then
dbms_output.put_line(v_empno||'高工资');
elsif v_sal between 2000 and 3000 then
dbms_output.put_line(v_empno||'一般工资');
else
dbms_output.put_line(v_empno||'低工资');
end if;
end;
/
case语句
简单case
case 表达式 when 值1 then 处理1;
when 值2 then 处理2;
......
else 处理N;
end case;
根据成绩,给出对应描述。A,优秀,B,良好,C,合格,D,不合格
declare
v_score char(2);
begin
v_score:=&v_score
case v_score
when 'A' then dbms_output.put_line('优秀');
when 'B' then dbms_output.put_line('良好');
when 'C' then dbms_output.put_line('合格');
when 'D' then dbms_output.put_line('不合格');
end case;
end;
/
搜索case
case when 条件1 then 处理1;
when 条件2 then 处理2;
......
else 处理N;
end case;
declare
v_sal emp.sal%type;
v_empno emp.empno%type;
begin
v_empno:=&v_empno;
select sal into v_sal from emp where empno=v_empno;
case
when v_sal>3000 then
dbms_output.put_line(v_empno||'高工资');
when v_sal between 2000 and 3000 then
dbms_output.put_line(v_empno||'一般工资');
else
dbms_output.put_line(v_empno||'低工资');
end case;
end;
/
循环结构
简单循环
loop
循环体;
exit when 条件;
end loop;
计算1+2+…+100。
declare
v_i int:=1; --存储基础数据
v_sum int:=0; --存储结果
begin
loop
v_sum:=v_sum+v_i;
v_i:=v_i+1;
exit when v_i>100;
end loop;
dbms_output.put_line('1+2+...+100='||v_sum);
end;
while循环
while 条件
loop
循环体;
end loop;
declare
v_i int:=1; --存储基础数据
v_sum int:=0; --存储结果
begin
while v_i<=100
loop
v_sum:=v_sum+v_i;
v_i:=v_i+1;
end loop;
dbms_output.put_line('1+2+...+100='||v_sum);
end;
for循环
for 循环控制变量 in [reverse] a..b
loop
循环体;
end loop;
注意:循环控制变量不需要事先声明,其作用主要用于控制循环的次数(b-a+1);
不能再for循环内部改变循环控制变量的值。
declare
v_i int:=1; --存储基础数据
v_sum int:=0; --存储结果
begin
for v_j in 1..50
loop
v_sum:=v_sum+v_i;
v_i:=v_i+2;
end loop;
dbms_output.put_line('1+2+...+100='||v_sum);
end;
/
declare
v_sum int:=0; --存储结果
begin
for v_j in 1..100
loop
if mod(v_j,2)=1 then
v_sum:=v_sum+v_j;
end if;
end loop;
dbms_output.put_line('1+2+...+100='||v_sum);
end;
LiveSQL
LiveSQL的使用:oracle官方提供的在线编程工具。
livesql.oracle.com
游标
用来处理多条记录。本质上就是一个内存区域。
分为隐式游标和显式游标。
隐式游标
在PL/SQL块中运行select into from,DML时,系统自动生成的游标。
隐式游标名: SQL
隐式游标的四个属性
%isopen
%found
%notfound
%rowcount
显式游标
用户定义的游标
显式游标使用步骤:
声明游标
declare部分, cursor cursor_name is select ;
打开游标
begin部分:open cursor_name; --此时执行游标对应的子查询,并把查询结果读入相应内存区域。
提取数据
fetch cursor_name into 变量名,;
关闭游标:
close cursor_name; 释放所占用的内存。
显式游标的四个属性
%isopen
游标是否打开。打开为真,失败为假。
%found
数据提取成功为真,失败为假
%notfound
数据提取失败为真,成功为假
%rowcount
当前提取的行数(此时的“行数”既表示当前提取的是第几行,又表示已提取的总行数)
写一个PL/SQL程序,输出员工的工号、姓名、参加工作时间。
select empno,ename,hiredate from emp;
declare
cursor cur1 is select empno,ename,hiredate from emp;
v_empno emp.empno%type;
v_ename emp.ename%type;
v_hiredate emp.hiredate%type;
begin
open cur1;
fetch cur1 into v_empno,v_ename,v_hiredate;
dbms_output.put_line(v_empno||' '||v_ename||' '||v_hiredate);
close cur1;
end;
declare
cursor cur1 is select empno,ename,hiredate from emp;
rec_cur1 cur1%rowtype;
begin
open cur1;
fetch cur1 into rec_cur1;
dbms_output.put_line(rec_cur.empno||' '||rec_cur1.ename||' '||rec_cur1.hiredate);
close cur1;
end;
--简单循环:
declare
cursor cur1 is select empno,ename,hiredate from emp;
rec_cur1 cur1%rowtype;
begin
open cur1;
loop
fetch cur1 into rec_cur1;
exit when cur1%notfound;
dbms_output.put_line(rec_cur1.empno||' '||rec_cur1.ename||' '||rec_cur1.hiredate);
end loop;
close cur1;
end;
--while循环:
declare
cursor cur1 is select empno,ename,hiredate from emp;
rec_cur1 cur1%rowtype;
begin
open cur1;
fetch cur1 into rec_cur1;
while cur1%found
loop
dbms_output.put_line(rec_cur1.empno||' '||rec_cur1.ename||' '||rec_cur1.hiredate);
fetch cur1 into rec_cur1;
end loop;
close cur1;
end;
--for循环:
declare
cursor cur1 is select empno,ename,hiredate from emp;
begin
for rec_cur1 in cur1
loop
dbms_output.put_line(rec_cur.empno||' '||rec_cur1.ename||' '||rec_cur1.hiredate);
end loop;
end;
begin
for rec_cur1 in (select empno,ename,hiredate from emp)
loop
dbms_output.put_line(rec_cur.empno||' '||rec_cur1.ename||' '||rec_cur1.hiredate);
end loop;
end;
写一个PL/SQL程序,输出特定部门员工的工号、姓名、参加工作时间。
declare
cursor cur1(v_deptno number) is select empno,ename,hiredate from emp where deptno=v_deptno;
begin
for rec_cur1 in cur1(20)
loop
dbms_output.put_line(rec_cur.empno||' '||rec_cur1.ename||' '||rec_cur1.hiredate);
end loop;
end;
异常处理
对程序中可能出现的错误进行预处理。
语法:
exception
when 异常1 then
处理1;
when 异常2 or 异常3 then
处理2;
......
when others then
处理n;
分类
系统预定义异常
no_data_found
too_many_rows(select into from)
invalid_cursor
zero_divide
others
declare
cursor cur1 is select empno,ename,hiredate from emp;
rec_cur1 cur1%rowtype;
begin
--open cur1;
loop
fetch cur1 into rec_cur1;
exit when cur1%notfound;
dbms_output.put_line(rec_cur1.empno||' '||rec_cur1.ename||' '||rec_cur1.hiredate);
end loop;
close cur1;
exception
when invalid_cursor then
dbms_output.put_line('游标未打开');
end;
用户自定义异常
三步骤法
声明异常
declare
异常名 exception;
激活异常
begin raise 异常名;
处理异常
exception when 异常名 then 处理;
通过用户自定义异常实现zero_divide预定义异常的功能。c=a/b
declare
v_a number;
v_b number;
v_c number;
begin
v_a:=&v_a;
v_b:=&v_b;
v_c:=v_a/v_b;
dbms_output.put_line(v_c);
exception
when zero_divide then
dbms_output.put_line(v_b||'不能为0');
end;
declare
v_a number;
v_b number;
v_c number;
zero_divide1 exception;
begin
v_a:=&v_a;
v_b:=&v_b;
if v_b=0 then
raise zero_divide1;
else
v_c:=v_a/v_b;
dbms_output.put_line(v_c);
end if;
exception
when zero_divide1 then
dbms_output.put_line(v_b||'不能为0');
end;
通过用户自定义异常实现no_data_found预定义异常的功能. select into from
输出特定员工的姓名和参加工作时间。 select ename,hiredate from emp where empno=v_empno;文章来源:https://www.toymoban.com/news/detail-824991.html
declare
v_ename emp.ename%type;
v_hiredate emp.hiredate%type;
v_empno emp.empno%type;
begin
v_empno:=&v_empno;
select ename,hiredate into v_ename,v_hiredate from emp where empno=v_empno;
dbms_output.put_line(v_empno||'的姓名'||v_ename||' '||'参加工作时间:'||v_hiredate);
exception
when no_data_found then
dbms_output.put_line(v_empno||'不存在');
end;
declare
v_ename emp.ename%type;
v_hiredate emp.hiredate%type;
v_empno emp.empno%type;
no_data_found1 exception;
v_count int;
begin
v_empno:=&v_empno;
select count(*) into v_count from emp where empno=v_empno;
if v_count=0 then
raise no_data_found1;
else
select ename,hiredate into v_ename,v_hiredate from emp where empno=v_empno;
dbms_output.put_line(v_empno||'的姓名'||v_ename||' '||'参加工作时间:'||v_hiredate);
end if;
exception
when no_data_found1 then
dbms_output.put_line(v_empno||'不存在');
end;
使用异常处理函数
raise_application_error(-序号,‘错误提示字符串’);
序号取值范围:20001-20099文章来源地址https://www.toymoban.com/news/detail-824991.html
declare
v_ename emp.ename%type;
v_hiredate emp.hiredate%type;
v_empno emp.empno%type;
v_count int;
begin
v_empno:=&v_empno;
select count(*) into v_count from emp where empno=v_empno;
if v_count=0 then
raise_application_error(-20022,v_empno||'不存在');
else
select ename,hiredate into v_ename,v_hiredate from emp where empno=v_empno;
dbms_output.put_line(v_empno||'的姓名'||v_ename||' '||'参加工作时间:'||v_hiredate);
end if;
end;
到了这里,关于Oracle大型数据库技术的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!