Scrapy:Python中强大的网络爬虫框架
在当今信息爆炸的时代,从互联网上获取数据已经成为许多应用程序的核心需求。Scrapy是一款基于Python的强大网络爬虫框架,它提供了一种灵活且高效的方式来提取、处理和存储互联网上的数据。本文将介绍Scrapy的主要特性和优势,以及如何使用它来构建强大的网络爬虫。
Scrapy简介
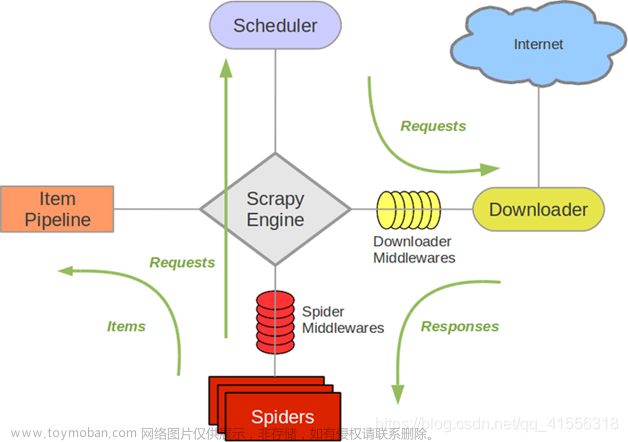
Scrapy是一个开源的网络爬虫框架,由Python编写而成。它提供了一套强大的工具和API,用于处理网页的下载、解析、数据提取和存储。Scrapy的设计目标是高效、可扩展和易于使用,使开发者能够快速构建复杂的网络爬虫应用程序。

主要特性
- 强大的爬取能力:Scrapy提供了强大的爬取能力,可以处理大规模的网站和海量的数据。它支持异步网络请求和多线程操作,使得爬取速度更快,并能够处理复杂的爬取任务。
- 灵活的数据提取:Scrapy提供了灵活的数据提取功能,可以从网页中提取结构化数据。它使用XPath或CSS选择器来定位和提取数据,支持正则表达式和自定义的数据处理管道,使得数据提取变得简单而灵活。
- 自动化的流程控制:Scrapy提供了自动化的流程控制机制,可以定义爬取流程和处理逻辑。开发者可以定义起始URL、跟踪链接、处理重定向、设置爬取速度等,使得整个爬取过程更加可控和可定制。
- 分布式和去重机制:Scrapy支持分布式爬取和去重机制,可以在多台机器上并行运行爬虫任务,提高爬取效率。它还提供了强大的去重功能,避免重复爬取相同的数据,节省带宽和存储空间。
- 扩展性和插件支持:Scrapy具有高度的扩展性,提供了丰富的插件和中间件机制。开发者可以根据自己的需求编写自定义的插件和中间件,以扩展Scrapy的功能和适应特定的爬取任务。
使用示例
以下是一个简单的示例,展示了如何使用Scrapy来爬取网页并提取数据:
- 安装Scrapy库:
pip install scrapy - 创建一个Scrapy爬虫项目:
$ scrapy startproject myspider$ cd myspider - 定义一个爬虫类,编写爬取逻辑和数据提取规则:
# myspider/spiders/example_spider.py import scrapy class ExampleSpider(scrapy.Spider): name = "example" start_urls = ["http://example.com"] def parse(self, response): title = response.css("h1::text").get() yield {"title": title} - 运行爬虫:
$ scrapy crawl example
爬虫将会访问"http://example.com"网页,提取标题数据,并输出结果。文章来源:https://www.toymoban.com/news/detail-825005.html
总结
Scrapy是一款功能强大的Python网络爬虫框架,为开发者提供了一种高效、灵活和可扩展的方式来构建网络爬虫应用程序。它具有强大的爬取能力、灵活的数据提取、自动化的流程控制、分布式和去重机制,以及扩展性和插件支持等特性。无论是进行数据挖掘、信息收集还是网站监测,Scrapy都是一个强大而可靠的选择。如果你正在寻找一种优秀的网络爬虫框架,Scrapy绝对值得一试。它将帮助你更轻松地构建和管理复杂的爬虫项目,并从互联网上获取所需的数据。文章来源地址https://www.toymoban.com/news/detail-825005.html
到了这里,关于Scrapy:Python中强大的网络爬虫框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!