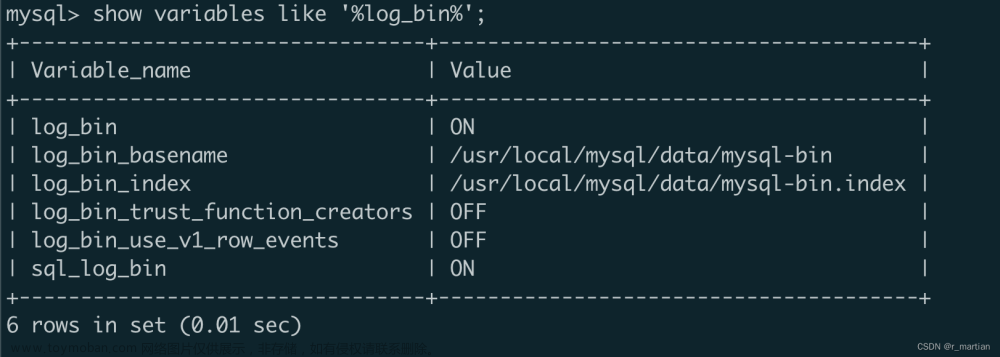
本文介绍的整体方案选型是:使用 Kafka Connect 的 Debezium MySQL Source Connector 将 MySQL 的 CDC 数据 (Avro 格式)接入到 Kafka 之后,通过 Flink 读取并解析这些 CDC 数据,其中,数据是以 Confluent 的 Avro 格式存储的,也就是说,Avro 格式的数据在写入到 Kafka 以及从 Kafka 读取时,都需要和 Confluent Schema Registry 进行交互,从而获取 Schema 信息,消息经 Flink 读取后会写入到 Hudi 表,从而完成全部的数据接入工作。
1. 前置依赖
本文不会展开介绍 CDC 数据进入 Kafka 之前的操作,此部分可以参考: 《CDC一键入湖: 当 Apache Hudi DeltaStreamer 遇见 Serverless Spark》一文的前半部分架构以及第 2 节环境准备部分的介绍,以下是前半部分数据管道使用到的相关组件的构建方法和文档:文章来源:https://www.toymoban.com/news/detail-825208.html
①MySQL:如果仅以测试为目的,建议使用Debezium提供的 官方Docker镜像,构建操作可参考其 官方文档(下文将给出的操作示例所处理的CDC数据就是自于该MyS文章来源地址https://www.toymoban.com/news/detail-825208.html
到了这里,关于CDC 整合方案:MySQL > Kafka Connect + Schema Registry + Avro > Kafka > Hudi的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!