前言
博主主页👉🏻蜡笔雏田学代码
专栏链接👉🏻【前端面试专栏】
今天开始学习前端面试题相关的知识!
感兴趣的小伙伴一起来看看吧~🤞

http 和 https 的基本概念
-
http:超文本传输协议,是互联网上应用最为广泛的一种网络协议,是一个客户端和服 务器端请求和应答的标准(TCP),用于从 WWW 服务器传输超文本到本地浏览器的传 输协议,它可以使浏览器更加高效,使网络传输减少。 -
https:是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。 (https 的 SSL 加密是在传输层实现的。) -
https 协议的主要作用:建立一个信息安全通道,来确保数组的传输,确保网站的真实 性。
http 和 https 的区别
http 传输的数据都是未加密的,也就是明文的,网景公司设置了 SSL 协议来对 http 协议 传输的数据进行加密处理,简单来说 https 协议是由 http 和 ssl 协议构建的可进行加密传 输和身份认证的网络协议,比 http 协议的安全性更高。
主要的区别如下:
- Https 协议需要 ca 证书,费用较高。
- http 是
超文本传输协议,信息是明文传输,https 则是具有安全性的ssl 加密传输协议。 使用不同的链接方式,端口也不同,一般而言,http 协议的端口为 80,https 的端口为 443- http 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传 输、身份认证的网络协议,比 http 协议安全。
https 协议的工作原理
客户端在使用 HTTPS 方式与 Web 服务器通信时有以下几个步骤:
- 客户使用 https url 访问服务器,则要求 web 服务器建立 ssl 链接。
- web 服务器接收到客户端的请求之后,会将网站的证书(证书中包含了公钥),返回或 者说传输给客户端。
- 客户端和 web 服务器端开始协商 SSL 链接的安全等级,也就是加密等级。
- 客户端浏览器通过双方协商一致的安全等级,建立会话密钥,然后通过网站的公钥来加 密会话密钥,并传送给网站。
- web 服务器通过自己的私钥解密出会话密钥。
- web 服务器通过会话密钥加密与客户端之间的通信。
HTTP2.0 的特性
http2.0 的特性如下:
内容安全,应为 http2.0 是基于 https 的,天然具有安全特性,通过 http2.0 的特性可以避免单纯使用 https 的性能下降。二进制格式,http1.X 的解析是基于文本的,http2.0 将所有的传输信息分割为更小的消息和帧,并对他们采用二进制格式编码,基于二进制可以让协议有更多的扩展性,比如引入了帧来传输数据和指令。多路复用,这个功能相当于是长连接的增强,每个 request 请求可以随机的混杂在一 起,接收方可以根据 request 的 id 将 request 再归属到各自不同的服务端请求里面,另外 多路复用中也支持了流的优先级,允许客户端告诉服务器那些内容是更优先级的资源, 可以优先传输。
tcp 三次握手
一句话概括:客户端和服务端都需要直到各自可收发,因此需要三次握手。
简化三次握手:
从图片可以得到三次握手可以简化为:C 发起请求连接 S 确认,也发起连接 C 确认我们 再看看每次握手的作用:第一次握手:S 只可以确认 自己可以接受 C 发送的报文段第 二次握手:C 可以确认 S 收到了自己发送的报文段,并且可以确认 自己可以接受 S 发 送的报文段第三次握手:S 可以确认 C 收到了自己发送的报文段。
TCP 和 UDP 的区别
- TCP 是面向连接的,UDP 是无连接的即发送数据前不需要先建立链接。
- TCP 提供可靠的服务。也就是说,通过 TCP 连接传送的数据,无差错,不丢失, 不重复,且按序到达;UDP 尽最大努力交付,即不保证可靠交付。 并且因为 TCP 可靠, 面向连接,不会丢失数据因此适合大数据量的交换。
- TCP 是面向字节流,UDP 面向报文,并且网络出现拥塞不会使得发送速率降低(因 此会出现丢包,对实时的应用比如 IP 电话和视频会议等)。
- TCP 只能是 1 对 1 的,UDP 支持 1 对 1,1 对多。
- TCP 的首部较大为 20 字节,而 UDP 只有 8 字节。
- TCP 是面向连接的可靠性传输,而 UDP 是不可靠的。
BOM 属性对象方法
什么是 Bom?
Bom 是浏览器对象。
有哪些常用的 Bom 属性呢?location 对象:
location.href——返回或设置当前文档的 URL
location.search——返回 URL 中的查询字符串部分。例 如 http://www.dreamdu.com/dreamdu.php?id=5&name=dreamdu —— 返回包括(?)后面的内 容?id=5&name=dreamdu
location.hash——返回 URL#后面的内容,如果没有#,返回空。
location.host——返回 URL 中的域名部分,例如 www.dreamdu.com
location.hostname——返回 URL 中的主域名部分,例如 dreamdu.com
location.pathname——返回 URL 的域名后的部分。例如 http://www.dreamdu.com/xhtml/ 返 回/xhtml/
location.port——返回 URL 中的端口部分。例如 http://www.dreamdu.com:8080/xhtml/ 返回 8080
location.protocol——返回 URL 中的协议部分。例如 http://www.dreamdu.com:8080/xhtml/ 返 回(//)前面的内容 http:
location.assign——设置当前文档的 URL
location.replace() ——设置当前文档的 URL,并且在 history 对象的地址列表中移除这个 URL location.replace(url);
location.reload()——重载当前页面history 对象
history.go() ——前进或后退指定的页面数 history.go(num);
history.back() ——后退一页
history.forward() ——前进一页Navigator 对象
navigator.userAgent ——返回用户代理头的字符串表示(就是包括浏览器版本信息等的字 符串) navigator.cookieEnabled ——返回浏览器是否支持(启用)cookie
400 和 401、403、304状态码
- 400 状态码:
请求无效
产生原因:前端提交数据的字段名称和字段类型与后台的实体没有保持一致,前端提交到后台的数据应该是 json 字符串类型,但是前端没有将对象 JSON.stringify 转 化成字符串。
解决方法:对照字段的名称,保持一致性 将 obj 对象通过 JSON.stringify 实现序列化- 401 状态码:当前请求需要用户验证
- 403 状态码:服务器已经得到请求,但是拒绝执行
- 304 状态码:如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自 上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个 304 状态码。
fetch 发送 2 次请求的原因
fetch 发送 post 请求的时候,总是发送 2 次,第一次状态码是 204,第二次才成功?
原因很简单,因为你用 fetch 的 post 请求的时候,导致 fetch 第一次发送了一个 Options 请求,询问服务器是否支持修改的请求头,如果服务器支持,则在第二次中发送真正的 请求。
Cookie、sessionStorage、localStorage 的区别
共同点:都是保存在浏览器端,并且是同源的
Cookie:cookie 数据始终在同源的 http 请求中携带(即使不需要),即 cookie 在浏览器 和服务器间来回传递。而 sessionStorage 和 localStorage 不会自动把数据发给服务器,仅 在本地保存。cookie 数据还有路径(path)的概念,可以限制 cookie 只属于某个路径下, 存储的大小很小只有 4K 左右。 (key:可以在浏览器和服务器端来回传递,存储容量 小,只有大约 4K 左右)sessionStorage:仅在当前浏览器窗口关闭前有效,自然也就不可能持久保持,localStorage: 始终有效,窗口或浏览器关闭也一直保存,因此用作持久数据;cookie 只在设置的 cookie 过期时间之前一直有效,即使窗口或浏览器关闭。(key:本身就是一个回话过程,关 闭浏览器后消失,session 为一个回话,当页面不同即使是同一页面打开两次,也被视为 同一次回话)localStorage:localStorage 在所有同源窗口中都是共享的;cookie 也是在所有同源窗口中 都是共享的。(key:同源窗口都会共享,并且不会失效,不管窗口或者浏览器关闭与 否都会始终生效)
补充说明一下 cookie 的作用:
保存用户登录状态。例如将用户 id 存储于一个 cookie 内,这样当用户下次访问该页面 时就不需要重新登录了,现在很多论坛和社区都提供这样的功能。 cookie 还可以设置 过期时间,当超过时间期限后,cookie 就会自动消失。因此,系统往往可以提示用户保 持登录状态的时间:常见选项有一个月、三个 月、一年等。
跟踪用户行为。例如一个天气预报网站,能够根据用户选择的地区显示当地的天气情况。如果每次都需要选择所在地是烦琐的,当利用了 cookie 后就会显得很人性化了,系统能 够记住上一次访问的地区,当下次再打开该页面时,它就会自动显示上次用户所在地区 的天气情况。因为一切都是在后 台完成,所以这样的页面就像为某个用户所定制的一 样,使用起来非常方便定制页面。如果网站提供了换肤或更换布局的功能,那么可以使 用 cookie 来记录用户的选项,例如:背景色、分辨率等。当用户下次访问时,仍然可以 保存上一次访问的界面风格。
对 HTML 语义化标签的理解
HTML5 语义化标签是指正确的标签包含了正确的内容,结构良好,便于阅读,比如 nav 表示导航条,类似的还有 article、header、footer 等等标签。
iframe 是什么?有什么缺点?
定义:iframe 元素会创建包含另一个文档的内联框架
提示:可以将提示文字放在
<
<
<iframe>
<
<
</iframe>之间,来提示某些不支持 iframe 的浏览器。
缺点:会阻塞主页面的 onload 事件 搜索引擎无法解读这种页面,不利于 SEO iframe 和主页面共享连接池,而浏览器对相同区域有限制所以会影响性能。
输入 URL 到页面加载显示完成发生了什么?
这是一个必考的面试问题。
- 输入 url 后,首先需要找到这个 url 域名的服务器 ip,为了寻找这个 ip,浏览器首先会
寻找缓存,查看缓存中是否有记录,缓存的查找记录为:浏览器缓存 => 系统缓存 => 路由器缓存,缓存中没有则查找系统的hosts 文件中是否有记录,如果没有则查询DNS 服务器。- 得到服务器的 ip 地址后,浏览器根据这个 ip 以及相应的端口号,
构造一个 http 请求,这个请求报文会包括这次请求的信息,主要是请求方法,请求说明和请求附带的数据,并将这个 http 请求封装在一个 tcp 包中,这个 tcp 包会依次经过传输层,网络层, 数据链路层,物理层到达服务器,服务器解析这个请求来作出响应,返回相应的 html 给浏览器。- 因为 html 是一个树形结构,浏览器根据这个 html 来构建 DOM 树,在 dom 树的构建过程中如果遇到 JS 脚本和外部 JS 连接,则会停止构建 DOM 树来执行和下载相应的代码,这会造成阻塞,这就是为什么推荐 JS 代码应该放在 html 代码的后面,之后根据外部样式,内部样式,内联样式构建一个 CSS 对象模型树 CSSOM 树,构建完成后和 DOM 树合并为渲染树,这里主要做的是排除非视觉节点,比如 script,meta 标签和 排除 display 为 none 的节点。
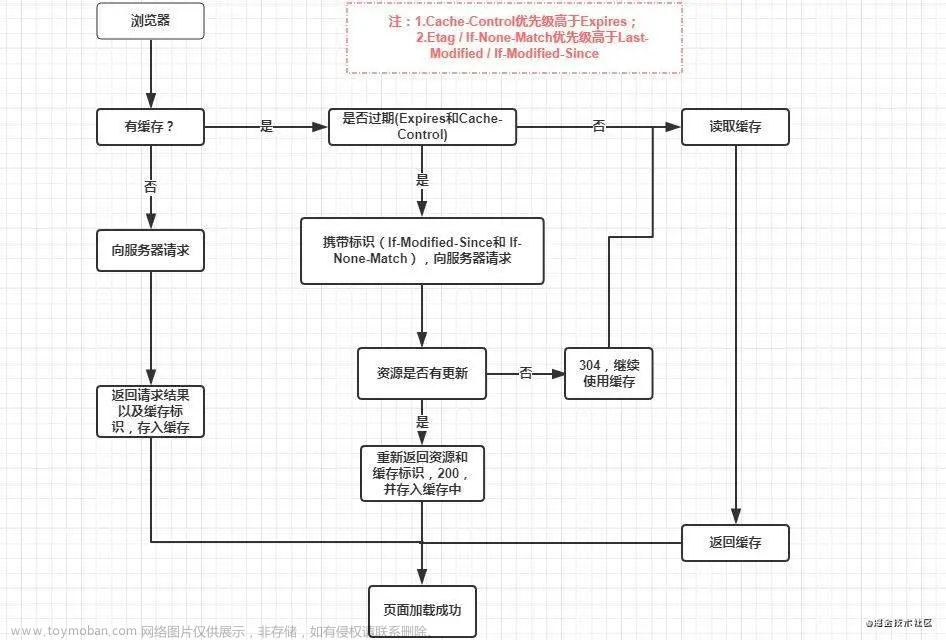
- 之后进行布局,布局主要是确定各个元素的位置和尺寸,之后是渲染页面,因为 html 文件中会含有图片,视频,音频等资源,在解析 DOM 的过 程中,遇到这些都会进行并行下载,浏览器对每个域的并行下载数量有一定的限制,一 般是 4-6 个,当然在这些所有的请求中我们还需要关注的就是缓存,缓存一般通过 Cache-Control、Last-Modify、Expires 等首部字段控制。
- Cache-Control 和 Expires 的区别在于
Cache-Control 使用相对时间,Expires 使用的是基于服务器端的绝对时间,因为存在时差问题,一般采用 Cache-Control,在请求这些设置了缓存的数据时,会先查看是否过期,如果没有过期则直接使用本地缓存,过期则请求并在服务器校验文件是否修 改,如果上一次 响应设置了 ETag 值会在这次请求的时候作为 If-None-Match 的值交给 服务器校验,如果一致,继续校验 Last-Modified,没有设置 ETag,则直接验证 Last-Modified,再决定是否返回 304。
一句话概括:DNS解析 => TCP 连接 => 发送 HTTP 请求 => 服务器处理请求并返回 HTTP 报文 => 浏览器解析渲染页面 => 连接结束
浏览器在生成页面的时候,会生成那两颗树?
构造两棵树,DOM 树和 CSSOM 规则树
当浏览器接收到服务器相应来的 HTML 文档后,会遍历文档节点,生成 DOM树, CSSOM 规则树由浏览器解析 CSS 文件生成。
csrf 和 xss 的网络攻击及防范
CSRF:跨站请求伪造,可以理解为攻击者盗用了用户的身份,以用户的名义发送了恶意请求,比如用户登录了一个网站后,立刻在另一个tab页面访问量攻击者用来制造攻击的网站,这个网站要求访问刚刚登陆的网站,并发送了一个恶意请求,这时候 CSRF 就产生了,比如这个制造攻击的网站使用一张图片,但是这种图片的链接却是可以修改 数据库的,这时候攻击者就可以以用户的名义操作这个数据库,防御方式:使用验证码,检查 https 头部的 refer字段,使用 tokenXSS:跨站脚本攻击,是说攻击者通过注入恶意的脚本,在用户浏览网页的时候进行攻击,比如获取 cookie,或者其他用户身份信息,可以分为存储型和反射型,存储型是攻击者输入一些数据并且存储到了数据库中,其他浏览者看到的时候进行攻击,反射型的话不存储在数据库中,往往表现为将攻击代码放在 url 地址的请求参数中,防御方式:为 cookie 设置 httpOnly 属性,对用户的输入进行检查,进行特殊字符过滤。文章来源:https://www.toymoban.com/news/detail-825231.html
今天的分享就到这里啦✨ \textcolor{red}{今天的分享就到这里啦✨} 今天的分享就到这里啦✨
原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
🤞 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{green}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{green}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!
文章来源地址https://www.toymoban.com/news/detail-825231.html
到了这里,关于【学姐面试宝典】—— 前端基础篇Ⅰ(HTTP/HTML/浏览器)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!