1 GC调优
Spark立足内存计算,常常需要在内存中存放大量数据,因此也更依赖JVM的垃圾回收机制。与此同时,它也兼容批处理和流式处理,对于程序吞吐量和延迟都有较高要求,因此GC参数的调优在Spark应用实践中显得尤为重要。
按照经验来说,当我们配置垃圾收集器时,主要有两种策略——Parallel GC和CMS GC。前者注重更高的吞吐量,而后者则注重更低的延迟。两者似乎是鱼和熊掌,不能兼得。在实际应用中,我们只能根据应用对性能瓶颈的侧重性,来选取合适的垃圾收集器。例如,当我们运行需要有实时响应的场景的应用时,我们一般选用CMS GC,而运行一些离线分析程序时,则选用Parallel GC。那么对于Spark这种既支持流式计算,又支持传统的批处理运算的计算框架来说,是否存在一组通用的配置选项呢?
通常CMS GC是企业比较常用的GC配置方案,并在长期实践中取得了比较好的效果。例如对于进程中若存在大量寿命较长的对象,Parallel GC经常带来较大的性能下降。因此,即使是批处理的程序也能从CMS GC中获益。不过,在从1.6开始的HOTSPOT JVM中,我们发现了一个新的GC设置项:Garbage-First GC(G1 GC),Oracle将其定位为CMS GC的长期演进。
1.1JVM虚拟机
每个Java开发者都知道Java字节码是执行在JRE(Java Runtime Environment Java运行时环境)上的。JRE中最重要的部分是Java虚拟机(JVM),JVM负责分析和执行Java字节码。Java开发人员并不需要去关心JVM是如何运行的。在没有深入理解JVM的情况下,许多开发者已经开发出了非常多的优秀的应用以及Java类库。不过,如果你了解JVM的话,你会更加了解Java的,并且你会轻松解决那些看似简单但是无从下手的问题。
1.1.1 虚拟机(Virtual Machine)
JRE是由Java API和JVM组成的。JVM的主要作用是通过Class Loader来加载Java程序,并且按照Java API来执行加载的程序。
虚拟机是通过软件的方式来模拟实现的机器(比如说计算机),它可以像物理机一样运行程序。设计虚拟机的初衷是让Java能够通过它来实现WORA(Write Once Run Anywher 一次编译,到处运行),尽管这个目标现在已经被大多数人忽略了。因此,JVM可以在不修改Java代码的情况下,在所有的硬件环境上运行Java字节码。
Java虚拟机的特点如下:
1)基于栈的虚拟机:Intel x86和ARM这两种最常见的计算机体系的机构都是基于寄存器的。不同的是,JVM是基于栈的。
2)符号引用:除了基本类型以外的数据(类和接口)都是通过符号来引用,而不是通过显式地使用内存地址来引用。
3)垃圾回收机制:类的实例都是通过用户代码进行创建,并且自动被垃圾回收机制进行回收。
4)通过对基本类型的清晰定义来保证平台独立性:传统的编程语言,例如C/C++,int类型的大小取决于不同的平台。JVM通过对基本类型的清晰定义来保证它的兼容性以及平台独立性。
5)网络字节码顺序:Java class文件用网络字节码顺序来进行存储:为了保证和小端的Intel x86架构以及大端的RISC系列的架构保持无关性,JVM使用用于网络传输的网络字节顺序,也就是大端。
虽然是Sun公司开发了Java,但是所有的开发商都可以开发并且提供遵循Java虚拟机规范的JVM。正是由于这个原因,使得Oracle HotSpot和IBM JVM等不同的JVM能够并存。Google的Android系统里的Dalvik VM也是一种JVM,虽然它并不遵循Java虚拟机规范。和基于栈的Java虚拟机不同,Dalvik VM是基于寄存器的架构,因此它的Java字节码也被转化成基于寄存器的指令集。
1.1.2 Java字节码(Java bytecode)
为了保证WORA,JVM使用Java字节码这种介于Java和机器语言之间的中间语言。字节码是部署Java代码的最小单位。
在解释Java字节码之前,我们先通过实例来简单了解它。这个案例是一个在开发环境出现的真实案例的总结。
现象
一个一直运行正常的应用突然无法运行了。在类库被更新之后,返回下面的错误。
1.Exception in thread "main" java.lang.NoSuchMethodError: com.wxn.user.UserAdmin.addUser(Ljava/lang/String;)V
2. at com.wxn.service.UserService.add(UserService.java:14)
3. at com.wxn.service.UserService.main(UserService.java:19)
应用的代码如下,而且它没有被改动过。
1.// UserService.java
2.…
3.public void add(String userName) {
4. admin.addUser(userName);
5.}
更新后的类库的源代码和原始的代码如下。
1.// UserAdmin.java - Updated library source code
2.…
3.public User addUser(String userName) {
4. User user = new User(userName);
5. User prevUser = userMap.put(userName, user);
6. return prevUser;
7.}
8.// UserAdmin.java - Original library source code
9.…
10.public void addUser(String userName) {
11. User user = new User(userName);
12. userMap.put(userName, user);
13.}
简而言之,之前没有返回值的addUser()被改修改成返回一个User类的实例的方法。不过,应用的代码没有做任何修改,因为它没有使用addUser()的返回值。
咋一看,com.wxn.user.UserAdmin.addUser()方法似乎仍然存在,如果存在的话,那么怎么还会出现NoSuchMethodError的错误呢?
原因
上面问题的原因是在于应用的代码没有用新的类库来进行编译。换句话来说,应用代码似乎是调了正确的方法,只是没有使用它的返回值而已。不管怎样,编译后的class文件表明了这个方法是有返回值的。你可以从下面的错误信息里看到答案。
1.java.lang.NoSuchMethodError: com.wxn.user.UserAdmin.addUser(Ljava/lang/String;)
NoSuchMethodError出现的原因是“com.wxn.user.UserAdmin.addUser(Ljava/lang/String;)V”方法找不到。注意一下”Ljava/lang/String;”和最后面的“V”。在Java字节码的表达式里,”L;”表示的是类的实例。这里表示addUser()方法有一个java/lang/String的对象作为参数。在这个类库里,参数没有被改变,所以它是正常的。最后面的“V”表示这个方法的返回值。在Java字节码的表达式里,”V”表示没有返回子(Void)。综上所述,上面的错误信息是表示有一个java.lang.String类型的参数,并且没有返回值的com.wxn.user.UserAdmin.addUser方法没有找到。
因为应用是用之前的类库编译的,所以返回值为空的方法被调用了。但是在修改后的类库里,返回值为空的方法不存在,并且添加了一个返回值为“Lcom/wxn/user/User”的方法。因此,就出现了NoSuchMethodError。
这个错误出现的原因是因为开发者没有用新的类库来重新编译应用。不过,出现这种问题的大部分责任在于类库的提供者。这个public的方法本来没有返回值的,但是后来却被修改成返回User类的实例。很明显,方法的签名被修改了,这也表明了这个类库的后向兼容性被破坏了。因此,这个类库的提供者应该告知使用者这个方法已经被改变了。
我们再回到Java字节码上来。Java字节码是JVM很重要的部分。JVM是模拟执行Java字节码的一个模拟器。Java编译器不会直接把高级语言(例如C/C++)编写的代码直接转换成机器语言(CPU指令);它会把开发者可以理解的Java语言转换成JVM能够理解的Java字节码。因为Java字节码本身是平台无关的,所以它可以在任何安装了JVM(确切地说,是相匹配的JRE)的硬件上执行,即使是在CPU和OS都不相同的平台上(在Windows PC上开发和编译的字节码可以不做任何修改就直接运行在Linux机器上)。编译后的代码的大小和源代码大小基本一致,这样就可以很容易地通过网络来传输和执行编译后的代码。
Java class文件是一种人很难去理解的二进文件。为了便于理解它,JVM提供者提供了javap,反汇编器。使用javap产生的结果是Java汇编语言。在上面的例子中,下面的Java汇编代码是通过javap-c对UserServiceadd()方法进行反汇编得到的。
1.public void add(java.lang.String);
2. Code:
3. 0: aload_0
4. 1: getfield #15; //Field admin:Lcom/wxn/user/UserAdmin;
5. 4: aload_1
6. 5: invokevirtual #23; //Method com/wxn/user/UserAdmin.addUser:(Ljava/lang/String;)
7. 8: return
invokeinterface:调用一个接口方法在这段Java汇编代码中,addUser()方法是在第四行的“5:invokevitual#23″进行调用的。这表示对应索引为23的方法会被调用。索引为23的方法的名称已经被javap给注解在旁边了。invokevirtual是Java字节码里调用方法的最基本的操作码。在Java字节码里,有四种操作码可以用来调用一个方法,分别是:invokeinterface,invokespecial,invokestatic以及invokevirtual。操作码的作用分别如下:
1)invokespecial: 调用一个初始化方法,私有方法或者父类的方法
2)invokestatic:调用静态方法
3)invokevirtual:调用实例方法
Java字节码的指令集由操作码和操作数组成。类似invokevirtual这样的操作数需要2个字节的操作数。
用更新的类库来编译上面的应用代码,然后反编译它,将会得到下面的结果。
1.public void add(java.lang.String);
2. Code:
3. 0: aload_0
4. 1: getfield #15; //Field admin:Lcom/wxn/user/UserAdmin;
5. 4: aload_1
6. 5: invokevirtual #23; //Method com/wxn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/wxn/user/User;
7. 8: pop
8. 9: return
你会发现,对应索引为23的方法被替换成了一个返回值为”Lcom/wxn/user/User”的方法。
在上面的反汇编代码里,代码前面的数字代码什么呢?
它表示的是字节数。大概这就是为什么运行在JVM上面的代码成为Java“字节”码的原因。简而言之,Java字节码指令的操作码,例如aload_0,getfield和invokevirtual等,都是用一个字节的数字来表示的(aload_0=0x2a,getfield=0xb4,invokevirtual=0xb6)。由此可知Java字节码指令的操作码最多有256个。
aload_0和aload_1这样的指令不需要任何操作数。因此,aload_0指令的下一个字节是下一个指令的操作码。不过,getfield和invokevirtual指令需要2字节的操作数。因此,getfiled的下一条指令是跳过两个字节,写在第四个字节的位置上的。十六进制编译器里查看字节码的结果如下所示。
1.2a b4 00 0f 2b b6 00 17 57 b1
表一:Java字节码中的类型表达式在Java字节码里,类的实例用字母“L;”表示,void 用字母“V”表示。通过这种方式,其他的类型也有对应的表达式。下面的表格对此作了总结。

下面的表格给出了字节码表达式的几个实例。
表二:Java字节码表达式范例
1.1.3 Class文件格式
在讲解Java class文件格式之前,我们先看看一个在Java Web应用中经常出现的问题。
当我们编写完Jsp代码,并且在Tomcat运行时,Jsp代码没有正常运行,而是出现了下面的错误。
现象
当我们编写完Jsp代码,并且在Tomcat运行时,Jsp代码没有正常运行,而是出现了下面的错误。
1.Servlet.service() for servlet jsp threw exception org.apache.jasper.JasperException: Unable to compile class for JSP Generated servlet error:
2.The code of method _jspService(HttpServletRequest, HttpServletResponse) is exceeding the 65535 bytes limit"
原因在不同的Web服务器上,上面的错误信息可能会有点不同,不过有有一点肯定是相同的,它出现的原因是65535字节的限制。这个65535字节的限制是JVM规范里的限制,它规定了一个方法的大小不能超过65535字节。
下面我会更加详细地讲解这个65535字节限制的意义以及它出现的原因。
Java字节码里的分支和跳转指令分别是”goto"和"jsr"。
1.goto [branchbyte1] [branchbyte2]
2.jsr [branchbyte1] [branchbyte2]
这两个指令都接收一个2字节的有符号的分支跳转偏移量做为操作数,因此偏移量最大只能达到65535。不过,为了支持更多的跳转,Java字节码提供了"goto_w"和"jsr_w"这两个可以接收4字节分支偏移的指令。
1.goto_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4]
jsr_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4]
有了这两个指令,索引超过65535的分支也是可用的。因此,Java方法的65535字节的限制就可以解除了。不过,由于Java class文件的更多的其他的限制,使得Java方法还是不能超过65535字节。
为了展示其他的限制,我会简单讲解一下class 文件的格式。
Java class文件的大致结构如下:
1.ClassFile {
2. u4 magic;
3. u2 minor_version;
4. u2 major_version;
5. u2 constant_pool_count;
6. cp_info constant_pool[constant_pool_count-1];
7. u2 access_flags;
8. u2 this_class;
9. u2 super_class;
10. u2 interfaces_count;
11. u2 interfaces[interfaces_count];
12. u2 fields_count;
13. field_info fields[fields_count];
14. u2 methods_count;
15. method_info methods[methods_count];
16. u2 attributes_count;
17. attribute_info attributes[attributes_count];}
之前反汇编的UserService.class文件反汇编的结果的前16个字节在十六进制编辑器中如下所示:
18.ca fe ba be 00 00 00 32 00 28 07 00 02 01 00 1b
通过这些数值,我们可以来看看class文件的格式。
1)magic:class文件最开始的四个字节是魔数。它的值是用来标识Java class文件的。从上面的内容里可以看出,魔数 的值是0xCAFEBABE。简而言之,只有一个文件的起始4字节是0xCAFEBABE的时候,它才会被当作Java class文件来处理。
2)minor_version,major_version:接下来的四个字节表示的是class文件的版本。UserService.class文件里的是0x00000032,所以这个class文件的版本是50.0。JDK 1.6编译的class文件的版本是50.0,JDK 1.5编译出来的class文件的版本是49.0。JVM必须对低版本的class文件保持后向兼容性,也就是低版本的class文件可以运行在高版本的JVM上。不过,反过来就不行了,当一个高版本的class文件运行在低版本的JVM上时,会出现java.lang.UnsupportedClassVersionError的错误。
3)constant_pool_count,constant_pool[]:在版本号之后,存放的是类的常量池。这里保存的信息将会放入运行时常量池(Runtime Constant Pool)中去,这个后面会讲解的。在加载一个class文件的时候,JVM会把常量池里的信息存放在方法区的运行时常量区里。UserService.class文件里的constant_pool_count的值是0x0028,这表示常量池里有39(40-1)个常量。
4)access_flags:这是表示一个类的描述符的标志;换句话说,它表示一个类是public,final还是abstract以及是不是接口的标志。
5)fields_count,fields[]:当前类的成员变量的数量以及成员变量的信息。成员变量的信息包含变量名,类型,修饰符以及变量在constant_pool里的索引。
6)methods_count,methods[]:当前类的方法数量以及方法的信息。方法的信息包含方法名,参数的数量和类型,返回值的类型,修饰符,以及方法在constant_pool里的索引,方法的可执行代码以及异常信息。
7)attributes_count,attributes[]:attribution_info结构包含不同种类的属性。field_info和method_info里都包含了attribute_info结构。
javap简要地给出了class文件的一个可读形式。当你用"java -verbose"命令来分析UserService.class时,会输出如下的内容:
1.Compiled from "UserService.java"
2.
3.public class com.wxn.service.UserService extends java.lang.Object
4. SourceFile: "UserService.java"
5. minor version: 0
6. major version: 50
7. Constant pool:const #1 = class #2; // com/wxn/service/UserService
8. const #2 = Asciz com/wxn/service/UserService;
9. const #3 = class #4; // java/lang/Object
10.const #4 = Asciz java/lang/Object;
11.const #5 = Asciz admin;
12.const #6 = Asciz Lcom/wxn/user/UserAdmin;;// … omitted - constant pool continued …
13.
14.{
15.// … omitted - method information …
16.
17.public void add(java.lang.String);
18. Code:
19. Stack=2, Locals=2, Args_size=2
20. 0: aload_0
21. 1: getfield #15; //Field admin:Lcom/wxn/user/UserAdmin;
22. 4: aload_1
23. 5: invokevirtual #23; //Method com/wxn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
24. 8: pop
25. 9: return LineNumberTable:
26. line 14: 0
27. line 15: 9 LocalVariableTable:
28. Start Length Slot Name Signature
29. 0 10 0 this Lcom/wxn/service/UserService;
30. 0 10 1 userName Ljava/lang/String; // … Omitted - Other method information …
31.}
javap输出的内容太长,我这里只是提出了整个输出的一部分。整个的输出展示了constant_pool里的不同信息,以及方法的内容。
关于方法的65565字节大小的限制是和method_info struct相关的。method_info结构包含Code,LineNumberTable,以及LocalViriable attribute几个属性,这个在“javap -verbose"的输出里可以看到。Code属性里的LineNumberTable,LocalVariableTable以及exception_table的长度都是用一个固定的2字节来表示的。因此,方法的大小是不能超过LineNumberTable,LocalVariableTable以及exception_table的长度的,它们都是65535字节。
许多人都在抱怨方法的大小限制,而且在JVM规范里还说名了”这个长度以后有可能会是可扩展的“。不过,到现在为止,还没有为这个限制做出任何动作。从JVM规范里的把class文件里的内容直接拷贝到方法区这个特点来看,要想在保持后向兼容性的同时来扩展方法区的大小是非常困难的。
如果因为Java编译器的错误而导致class文件的错误,会怎么样呢?或者,因为网络传输的错误导致拷贝的class文件的损坏呢?
为了预防这种场景,Java的类装载器通过一个严格而且慎密的过程来校验class文件。在JVM规范里详细地讲解了这方面的内容。
注意
我们怎样能够判断JVM正确地执行了class文件校验的所有过程呢?我们怎么来判断不同提供商的不同JVM实现是符合JVM规范的呢?为了能够验证以上两点,Oracle提供了一个测试工具TCK(Technology Compatibility Kit)。这个TCK工具通过执行成千上万的测试用例来验证一个JVM是否符合规范,这些测试里面包含了各种非法的class文件。只有通过了TCK的测试的JVM才能称作JVM。
和TCK相似,有一个组织JCP(Java Community Process;http://jcp.org)负责Java规范以及新的Java技术规范。对于JCP而言,如果要完成一项Java规范请求(Java Specification Request, JSR)的话,需要具备规范文档,可参考的实现以及通过TCK测试。任何人如果想使用一项申请JSR的新技术的话,他要么使用RI提供许可的实现,要么自己实现一个并且保证通过TCK的测试。
1.1.4 JVM结构
Java编写的代码会按照下图的流程来执行

类装载器装载负责装载编译后的字节码,并加载到运行时数据区(Runtime Data Area),然后执行引擎执行会执行这些字节码。
类加载器(Class Loader)
Java提供了动态的装载特性;它会在运行时的第一次引用到一个class的时候对它进行装载和链接,而不是在编译期进行。JVM的类装载器负责动态装载。Java类装载器有如下几个特点:
层级结构:Java里的类装载器被组织成了有父子关系的层级结构。Bootstrap类装载器是所有装载器的父亲。
代理模式:基于层级结构,类的装载可以在装载器之间进行代理。当装载器装载一个类时,首先会检查它是否在父装载器中进行装载了。如果上层的装载器已经装载了这个类,这个类会被直接使用。反之,类装载器会请求装载这个类。
可见性限制:一个子装载器可以查找父装载器中的类,但是一个父装载器不能查找子装载器里的类。
不允许卸载:类装载器可以装载一个类但是不可以卸载它,不过可以删除当前的类装载器,然后创建一个新的类装载器。
每个类装载器都有一个自己的命名空间用来保存已装载的类。当一个类装载器装载一个类时,它会通过保存在命名空间里的类全局限定名(Fully Qualified Class Name)进行搜索来检测这个类是否已经被加载了。如果两个类的全局限定名是一样的,但是如果命名空间不一样的话,那么它们还是不同的类。不同的命名空间表示class被不同的类装载器装载。
下图展示了类装载器的代理模型。

当一个类装载器(class loader)被请求装载类时,它首先按照顺序在上层装载器、父装载器以及自身的装载器的缓存里检查这个类是否已经存在。简单来说,就是在缓存里查看这个类是否已经被自己装载过了,如果没有的话,继续查找父类的缓存,直到在bootstrap类装载器里也没有找到的话,它就会自己在文件系统里去查找并且加载这个类。
启动类加载器(Bootstrap class loader):这个类装载器是在JVM启动的时候创建的。它负责装载Java API,包含Object对象。和其他的类装载器不同的地方在于这个装载器是通过native code来实现的,而不是用Java代码。
扩展类加载器(Extension class loader):它装载除了基本的Java API以外的扩展类。它也负责装载其他的安全扩展功能。
系统类加载器(System class loader):如果说bootstrap class loader和extension class loader负责加载的是JVM的组件,那么system class loader负责加载的是应用程序类。它负责加载用户在$CLASSPATH里指定的类。
用户自定义类加载器(User-defined class loader):这是应用程序开发者用直接用代码实现的类装载器。
类似于web应用服务(WAS)之类的框架会用这种结构来对Web应用和企业级应用进行分离。换句话来说,类装载器的代理模型可以用来保证不同应用之间的相互独立。WAS类装载器使用这种层级结构,不同的WAS供应商的装载器结构有稍许区别。
如果类装载器查找到一个没有装载的类,它会按照下图的流程来装载和链接这个类:

每个阶段的描述如下:
Loading: 类的信息从文件中获取并且载入到JVM的内存里。
Verifying:检查读入的结构是否符合Java语言规范以及JVM规范的描述。这是类装载中最复杂的过程,并且花费的时间也是最长的。并且JVM TCK工具的大部分场景的用例也用来测试在装载错误的类的时候是否会出现错误。
Preparing:分配一个结构用来存储类信息,这个结构中包含了类中定义的成员变量,方法和接口的信息。
Resolving:把这个类的常量池中的所有的符号引用改变成直接引用。
Initializing:把类中的变量初始化成合适的值。执行静态初始化程序,把静态变量初始化成指定的值。
JVM规范定义了上面的几个任务,不过它允许具体执行的时候能够有些灵活的变动。
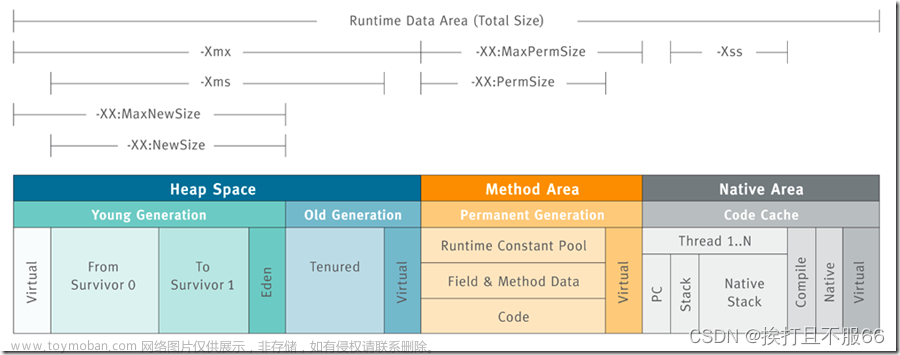
运行时数据区(Runtime Data Areas)

运行时数据区是在JVM运行的时候操作所分配的内存区。运行时内存区可以划分为6个区域。在这6个区域中,一个PC Register,JVM stack 以及Native Method Statck都是按照线程创建的,Heap,Method Area以及Runtime Constant Pool都是被所有线程公用的。
PC寄存器(PC register):每个线程启动的时候,都会创建一个PC(Program Counter ,程序计数器)寄存器。PC寄存器里保存有当前正在执行的JVM指令的地址。
JVM 堆栈(JVM stack):每个线程启动的时候,都会创建一个JVM堆栈。它是用来保存栈帧的。JVM只会在JVM堆栈上对栈帧进行push和pop的操作。如果出现了异常,堆栈跟踪信息的每一行都代表一个栈帧立的信息,这些信息它是通过类似于printStackTrace()这样的方法来展示的。

栈帧(stack frame):每当一个方法在JVM上执行的时候,都会创建一个栈帧,并且会添加到当前线程的JVM堆栈上。当这个方法执行结束的时候,这个栈帧就会被移除。每个栈帧里都包含有当前正在执行的方法所属类的本地变量数组,操作数栈,以及运行时常量池的引用。本地变量数组的和操作数栈的大小都是在编译时确定的。因此,一个方法的栈帧的大小也是固定不变的。
局部变量数组(Local variable array):这个数组的索引从0开始。索引为0的变量表示这个方法所属的类的实例。从1开始,首先存放的是传给该方法的参数,在参数后面保存的是方法的局部变量。
操作数栈(Operand stack):方法实际运行的工作空间。每个方法都在操作数栈和局部变量数组之间交换数据,并且压入或者弹出其他方法返回的结果。操作数栈所需的最大空间是在编译期确定的。因此,操作数栈的大小也可以在编译期间确定。
本地方法栈(Native method stack):供用非Java语言实现的本地方法的堆栈。换句话说,它是用来调用通过JNI(Java Native Interface Java本地接口)调用的C/C++代码。根据具体的语言,一个C堆栈或者C++堆栈会被创建。
方法区(Method area):方法区是所有线程共享的,它是在JVM启动的时候创建的。它保存所有被JVM加载的类和接口的运行时常量池,成员变量以及方法的信息,静态变量以及方法的字节码。JVM的提供者可以通过不同的方式来实现方法区。在Oracle 的HotSpot JVM里,方法区被称为永久区或者永久代(PermGen)。是否对方法区进行垃圾回收对JVM的实现是可选的。
运行时常量池(Runtime constant pool):这个区域和class文件里的constant_pool是相对应的。这个区域是包含在方法区里的,不过,对于JVM的操作而言,它是一个核心的角色。因此在JVM规范里特别提到了它的重要性。除了包含每个类和接口的常量,它也包含了所有方法和变量的引用。简而言之,当一个方法或者变量被引用时,JVM通过运行时常量区来查找方法或者变量在内存里的实际地址。
堆(Heap):用来保存实例或者对象的空间,而且它是垃圾回收的主要目标。当讨论类似于JVM性能之类的问题时,它经常会被提及。JVM提供者可以决定怎么来配置堆空间,以及不对它进行垃圾回收。
现在我们再会过头来看看之前反汇编的字节码
1.public void add(java.lang.String);
2. Code:
3. 0: aload_0
4. 1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
5. 4: aload_1
6. 5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
7. 8: pop
8. 9: return
把上面的反汇编代码和我们平时所见的x86架构的汇编代码相比较,我们会发现这两者的结构有点相似,都使用了操作码;不过,有一点不同的地方是Java字节码并不会在操作数里写入寄存器的名称、内存地址或者偏移量。之前已经说过,JVM用的是栈,它不会使用寄存器。和使用寄存器的x86架构不同,它自己负责内存的管理。它用索引例如15和23来代替实际的内存地址。15和23都是当前类(这里是UserService类)的常量池里的索引。简而言之,JVM为每个类创建了一个常量池,并且这个常量池里保存了实际目标的引用。
每行反汇编代码的解释如下:
aload_0:把局部变量数组中索引为#0的变量添加到操作数栈上。索引#0所表示的变量是this,即是当前实例的引用。
getfield #15:把当前类的常量池里的索引为#15的变量添加到操作数栈。这里添加的是UserAdmin的admin成员变量。因为admin变量是个类的实例,因此添加的是一个引用。
aload_1:把局部变量数组里的索引为#1的变量添加到操作数栈。来自局部变量数组里的索引为1的变量是方法的一个参数。因此,在调用add()方法的时候,会把userName指向的String的引用添加到操作数栈上。
invokevirtual #23:调用当前类的常量池里的索引为#23的方法。这个时候,通过getfile和aload_1添加到操作数栈上的引用都被作为方法的参数。当方法运行完成并且返回时,它的返回值会被添加到操作数栈上。
pop:把通过invokevirtual调用的方法的返回值从操作数栈里弹出来。你可以看到,在前面的例子里,用老的类库编译的那段代码是没有返回值的。简而言之,正因为之前的代码没有返回值,所以没必要吧把返回值从操作数栈上给弹出来。
return:结束当前方法调用
下图可以帮助你更好地理解上面的内容。

顺便提一下,在这个方法里,局部变量数组没有被修改。所以上图只显示了操作数栈的变化。不过,大部分的情况下,局部变量数组也是会改变的。局部变量数组和操作数栈之间的数据传输是使用通过大量的load指令(aload,iload)和store指令(astore,istore)来实现的。
在这个图里,我们简单验证了运行时常量池和JVM栈的描述。当JVM运行的时候,每个类的实例都会在堆上进行分配,User,UserAdmin,UserService以及String等类的信息都会保存在方法区。
执行引擎(Execution Engine)通过类装载器装载的,被分配到JVM的运行时数据区的字节码会被执行引擎执行。执行引擎以指令为单位读取Java字节码。它就像一个CPU一样,一条一条地执行机器指令。每个字节码指令都由一个1字节的操作码和附加的操作数组成。执行引擎取得一个操作码,然后根据操作数来执行任务,完成后就继续执行下一条操作码。
不过Java字节码是用一种人类可以读懂的语言编写的,而不是用机器可以直接执行的语言。因此,执行引擎必须把字节码转换成可以直接被JVM执行的语言。字节码可以通过以下两种方式转换成合适的语言。
解释器:一条一条地读取,解释并且执行字节码指令。因为它一条一条地解释和执行指令,所以它可以很快地解释字节码,但是执行起来会比较慢。这是解释执行的语言的一个缺点。字节码这种“语言”基本来说是解释执行的。
即时(Just-In-Time)编译器:即时编译器被引入用来弥补解释器的缺点。执行引擎首先按照解释执行的方式来执行,然后在合适的时候,即时编译器把整段字节码编译成本地代码。然后,执行引擎就没有必要再去解释执行方法了,它可以直接通过本地代码去执行它。执行本地代码比一条一条进行解释执行的速度快很多。编译后的代码可以执行的很快,因为本地代码是保存在缓存里的。
不过,用JIT编译器来编译代码所花的时间要比用解释器去一条条解释执行花的时间要多。因此,如果代码只被执行一次的话,那么最好还是解释执行而不是编译后再执行。因此,内置了JIT编译器的JVM都会检查方法的执行频率,如果一个方法的执行频率超过一个特定的值的话,那么这个方法就会被编译成本地代码。

JVM规范没有定义执行引擎该如何去执行。因此,JVM的提供者通过使用不同的技术以及不同类型的JIT编译器来提高执行引擎的效率。
大部分的JIT编译器都是按照下图的方式来执行的:

JIT编译器把字节码转换成一个中间层表达式,一种中间层的表示方式,来进行优化,然后再把这种表示转换成本地代码。
Oracle Hotspot VM使用一种叫做热点编译器的JIT编译器。它之所以被称作”热点“是因为热点编译器通过分析找到最需要编译的“热点”代码,然后把热点代码编译成本地代码。如果已经被编译成本地代码的字节码不再被频繁调用了,换句话说,这个方法不再是热点了,那么Hotspot VM会把编译过的本地代码从cache里移除,并且重新按照解释的方式来执行它。Hotspot VM分为Server VM和Client VM两种,这两种VM使用不同的JIT编译器。

Client VM 和Server VM使用完全相同的运行时,不过如上图所示,它们所使用的JIT编译器是不同的。Server VM用的是更高级的动态优化编译器,这个编译器使用了更加复杂并且更多种类的性能优化技术。
IBM 在IBM JDK 6里不仅引入了JIT编译器,它同时还引入了AOT(Ahead-Of-Time)编译器。它使得多个JVM可以通过共享缓存来共享编译过的本地代码。简而言之,通过AOT编译器编译过的代码可以直接被其他JVM使用。除此之外,IBM JVM通过使用AOT编译器来提前把代码编译器成JXE(Java EXecutable)文件格式来提供一种更加快速的执行方式。
大部分Java程序的性能都是通过提升执行引擎的性能来达到的。正如JIT编译器一样,很多优化的技术都被引入进来使得JVM的性能一直能够得到提升。最原始的JVM和最新的JVM最大的差别之处就是在于执行引擎。
Hotspot编译器在1.3版本的时候就被引入到Oracle Hotspot VM里了,JIT编译技术在Anroid 2.2版本的时候被引入到Dalvik VM里。
引入一种中间语言,例如字节码,虚拟机执行字节码,并且通过JIT编译器来提升JVM的性能的这种技术以及广泛应用在使用中间语言的编程语言上。例如微软的.Net,CLR(Common Language Runtime 公共语言运行时),也是一种VM,它执行一种被称作CIL(Common Intermediate Language)的字节码。CLR提供了AOT编译器和JIT编译器。因此,用C#或者VB.NET编写的源代码被编译后,编译器会生成CIL并且CIL会执行在有JIT编译器的CLR上。CLR和JVM相似,它也有垃圾回收机制,并且也是基于堆栈运行。
Java 虚拟机规范,Java SE 第7版2011年7月28日,Oracle发布了Java SE的第7个版本,并且把JVM规也更新到了相应的版本。在1999年发布《The Java Virtual Machine Specification,Second Edition》后,Oracle花了12年来发布这个更新的版本。这个更新的版本包含了这12年来累积的众多变化以及修改,并且更加细致地对规范进行了描述。此外,它还反映了《The Java Language Specificaion,Java SE 7 Edition》里的内容。主要的变化总结如下:
来自Java SE 5.0里的泛型,支持可变参数的方法
从Java SE 6以来,字节码校验的处理技术所发生的改变
添加invokedynamic指令以及class文件对于该指令的支持
删除了关于Java语言概念的内容,并且指引读者去参考Java语言规范
删除关于Java线程和锁的描述,并且把它们移到Java语言规范里
最大的改变是添加了invokedynamic指令。也就是说JVM的内部指令集做了修改,使得JVM开始支持动态类型的语言,这种语言的类型不是固定的,例如脚本语言以及来自Java SE 7里的Java语言。之前没有被用到的操作码186被分配给新指令invokedynamic,而且class文件格式里也添加了新的内容来支持invokedynamic指令。
Java SE 7的编译器生成的class文件的版本号是51.0。Java SE 6的是50.0。class文件的格式变动比较大,因此,51.0版本的class文件不能够在Java SE 6的虚拟机上执行。
尽管有了这么多的变动,但是Java方法的65535字节的限制还是没有被去掉。除非class文件的格式彻底改变,否者这个限制将来也是不可能去掉的。
值得说明的是,Oracle Java SE 7 VM支持G1这种新的垃圾回收机制,不过,它被限制在Oracle JVM上,因此,JVM本身对于垃圾回收的实现不做任何限制。也因此,在JVM规范里没有对它进行描述。
switch语句里的StringJava SE 7里添加了很多新的语法和特性。不过,在Java SE 7的版本里,相对于语言本身而言,JVM没有多少的改变。那么,这些新的语言特性是怎么来实现的呢?我们通过反汇编的方式来看看switch语句里的String(把字符串作为switch()语句的比较对象)是怎么实现的?
例如,下面的代码:
1.// SwitchTest
2.public class SwitchTest {
3. public int doSwitch(String str) {
4. switch (str) {
5. case "abc": return 1;
6. case "123": return 2;
7. default: return 0;
8. }
9. }
10.}
因为这是Java SE 7的一个新特性,所以它不能在Java SE 6或者更低版本的编译器上来编译。用Java SE 7的javac来编译。下面是通过javap -c来反编译后的结果。
1.C:Test>javap -c SwitchTest.classCompiled from "SwitchTest.java"
2.public class SwitchTest {
3. public SwitchTest();
4. Code:
5. 0: aload_0
6. 1: invokespecial #1 // Method java/lang/Object."<init>":()V
7. 4: return public int doSwitch(java.lang.String);
8. Code:
9. 0: aload_1
10. 1: astore_2
11. 2: iconst_m1
12. 3: istore_3
13. 4: aload_2
14. 5: invokevirtual #2 // Method java/lang/String.hashCode:()I
15. 8: lookupswitch { // 2
16. 48690: 50
17. 96354: 36
18. default: 61
19. }
20. 36: aload_2
21. 37: ldc #3 // String abc
22. 39: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
23. 42: ifeq 61
24. 45: iconst_0
25. 46: istore_3
26. 47: goto 61
27. 50: aload_2
28. 51: ldc #5 // String 123
29. 53: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
30. 56: ifeq 61
31. 59: iconst_1
32. 60: istore_3
33. 61: iload_3
34. 62: lookupswitch { // 2
35. 0: 88
36. 1: 90
37. default: 92
38. }
39. 88: iconst_1
40. 89: ireturn
41. 90: iconst_2
42. 91: ireturn
43. 92: iconst_0
44. 93: ireturn
在#5和#8字节处,首先是调用了hashCode()方法,然后它作为参数调用了switch(int)。在lookupswitch的指令里,根据hashCode的结果进行不同的分支跳转。字符串“abc"的hashCode是96354,它会跳转到#36处。字符串”123“的hashCode是48690,它会跳转到#50处。生成的字节码的长度比Java源码长多了。首先,你可以看到字节码里用lookupswitch指令来实现switch()语句。不过,这里使用了两个lookupswitch指令,而不是一个。如果反编译的是针对Int的switch()语句的话,字节码里只会使用一个lookupswitch指令。也就是说,针对string的switch语句被分成用两个语句来实现。留心标号为#5,#39和#53的指令,来看看switch()语句是如何处理字符串的。
在第#36,#37,#39,以及#42字节的地方,你可以看见str参数被equals()方法来和字符串“abc”进行比较。如果比较的结果是相等的话,‘0’会被放入到局部变量数组的索引为#3的位置,然后跳抓转到第#61字节。
在第#50,#51,#53,以及#56字节的地方,你可以看见str参数被equals()方法来和字符串“123”进行比较。如果比较的结果是相等的话,10’会被放入到局部变量数组的索引为#3的位置,然后跳转到第#61字节。
在第#61和#62字节的地方,局部变量数组里索引为#3的值,这里是’0’,‘1’或者其他的值,被lookupswitch用来进行搜索并进行相应的分支跳转。
换句话来说,在Java代码里的用来作为switch()的参数的字符串str变量是通过hashCode()和equals()方法来进行比较,然后根据比较的结果,来执行swtich()语句。
在这个结果里,编译后的字节码和之前版本的JVM规范没有不兼容的地方。Java SE 7的这个用字符串作为switch参数的特性是通过Java编译器来处理的,而不是通过JVM来支持的。通过这种方式还可以把其他的Java SE 7的新特性也通过Java编译器来实现。
1.2GC算法原理
在传统JVM内存管理中,我们把Heap空间分为Young/Old两个分区,Young分区又包括一个Eden和两个Survivor分区,如下图所示。新产生的对象首先会被存放在Eden区,而每次minor GC发生时,JVM一方面将Eden分区内存活的对象拷贝到一个空的Survivor分区,另一方面将另一个正在被使用的Survivor分区中的存活对象也拷贝到空的Survivor分区内。在此过程中,JVM始终保持一个Survivor分区处于全空的状态。一个对象在两个Survivor之间的拷贝到一定次数后,如果还是存活的,就将其拷入Old分区。当Old分区没有足够空间时,GC会停下所有程序线程,进行Full GC,即对Old区中的对象进行整理。这个所有线程都暂停的阶段被称为Stop-The-World(STW),也是大多数GC算法中对性能影响最大的部分。
而G1 GC则完全改变了这一传统思路。它将整个Heap分为若干个预先设定的小区域块(如图2),每个区域块内部不再进行新旧分区, 而是将整个区域块标记为Eden/Survivor/Old。当创建新对象时,它首先被存放到某一个可用区块(Region)中。当该区块满了,JVM就会创建新的区块存放对象。当发生minor GC时,JVM将一个或几个区块中存活的对象拷贝到一个新的区块中,并在空余的空间中选择几个全新区块作为新的Eden分区。当所有区域中都有存活对象,找不到全空区块时,才发生Full GC。而在标记存活对象时,G1使用RememberSet的概念,将每个分区外指向分区内的引用记录在该分区的RememberSet中,避免了对整个Heap的扫描,使得各个分区的GC更加独立。在这样的背景下,我们可以看出G1 GC大大提高了触发Full GC时的Heap占用率,同时也使得Minor GC的暂停时间更加可控,对于内存较大的环境非常友好。这些颠覆性的改变,将给GC性能带来怎样的变化呢?最简单的方式,我们可以将老的GC设置直接迁移为G1 GC,然后观察性能变化。

由于G1取消了对于heap空间不同新旧对象固定分区的概念,所以我们需要在GC配置选项上作相应的调整,使得应用能够合理地运行在G1 GC收集器上。一般来说,对于原运行在Parallel GC上的应用,需要去除的参数包括-Xmn, -XX:-UseAdaptiveSizePolicy, -XX:SurvivorRatio=n等;而对于原来使用CMS GC的应用,我们需要去掉-Xmn -XX:InitialSurvivorRatio -XX:SurvivorRatio -XX:InitialTenuringThreshold -XX:MaxTenuringThreshold等参数。另外在CMS中已经调优过的-XX:ParallelGCThreads -XX:ConcGCThreads参数最好也移除掉,因为对于CMS来说性能最好的不一定是对于G1性能最好的选择。我们先统一置为默认值,方便后期调优。此外,当应用开启的线程较多时,最好使用-XX:-ResizePLAB来关闭PLAB()的大小调整,以避免大量的线程通信所导致的性能下降。
关于Hotspot JVM所支持的完整的GC参数列表,可以使用参数-XX:+PrintFlagsFinal打印出来,也可以参见Oracle官方的文档中对部分参数的解释。
1.3Spark的内存管理
Spark的核心概念是RDD,实际运行中内存消耗都与RDD密切相关。Spark允许用户将应用中重复使用的RDD数据持久化缓存起来,从而避免反复计算的开销,而RDD的持久化形态之一就是将全部或者部分数据缓存在JVM的Heap中。Spark Executor会将JVM的heap空间大致分为两个部分,一部分用来存放Spark应用中持久化到内存中的RDD数据,剩下的部分则用来作为JVM运行时的堆空间,负责RDD转化等过程中的内存消耗。我们可以通过spark.storage.memoryFraction参数调节这两块内存的比例,Spark会控制缓存RDD总大小不超过heap空间体积乘以这个参数所设置的值,而这块缓存RDD的空间中没有使用的部分也可以为JVM运行时所用。因此,分析Spark应用GC问题时应当分别分析两部分内存的使用情况。
而当我们观察到GC延迟影响效率时,应当先检查Spark应用本身是否有效利用有限的内存空间。RDD占用的内存空间比较少的话,程序运行的heap空间也会比较宽松,GC效率也会相应提高;而RDD如果占用大量空间的话,则会带来巨大的性能损失。下面我们从一个用户案例展开:
该应用是利用Spark的组件Bagel来实现的,其本质就是一个简单的迭代计算。而每次迭代计算依赖于上一次的迭代结果,因此每次迭代结果都会被主动持续化到内存空间中。当运行用户程序时,我们观察到随着迭代次数的增加,进程占用的内存空间不断快速增长,GC问题越来越突出。但是,仔细分析Bagel实现机制,我们很快发现Bagel将每次迭代产生的RDD都持久化下来了,而没有及时释放掉不再使用的RDD,从而造成了内存空间不断增长,触发了更多GC执行。经过简单的修改,我们修复了这个问题(SPARK-2661)。应用的内存空间得到了有效的控制后,迭代次数三次以后RDD大小趋于稳定,缓存空间得到有效控制(如表1所示),GC效率得以大大提高,程序总的运行时间缩短了10%~20%。

小结:当观察到GC频繁或者延时长的情况,也可能是Spark进程或者应用中内存空间没有有效利用。所以可以尝试检查是否存在RDD持久化后未得到及时释放等情况。
1.4选择垃圾收集器
在解决了应用本身的问题之后,我们就要开始针对Spark应用的GC调优了。基于修复了SPARK-2661的Spark版本,我们搭建了一个4个节点的集群,给每个Executor分配88G的Heap,在Spark的Standalone模式下来进行我们的实验。在使用默认的Parallel GC运行我们的Spark应用时,我们发现,由于Spark应用对于内存的开销比较大,而且大部分对象并不能在一个较短的生命周期中被回收,Parallel GC也常常受困于Full GC,而每次Full GC都给性能带来了较大的下降。而Parallel GC可以进行参数调优的空间也非常有限,我们只能通过调节一些基本参数来提高性能,如各年代分区大小比例、进入老年代前的拷贝次数等。而且这些调优策略只能推迟Full GC的到来,如果是长期运行的应用,Parallel GC调优的意义就非常有限了。因此,本文中不会再对Parallel GC进行调优。表2列出了Parallel GC的运行情况,其中CPU利用率较低的部分正是发生Full GC的时候。

Parallel GC运行情况(未调优)
至于CMS GC,也没有办法消除这个Spark应用中的Full GC,而且CMS的Full GC的暂停时间远远超过了Parallel GC,大大拖累了该应用的吞吐量。
接下来,我们就使用最基本的G1 GC配置来运行我们的应用。实验结果发现,G1 GC竟然也出现了不可忍受的Full GC(表3的CPU利用率图中,可以明显发现Job 3中出现了将近100秒的暂停),超长的暂停时间大大拖累了整个应用的运行。如表4所示,虽然总的运行时间比Parallel GC略长,不过G1 GC表现略好于CMS GC。


1.5据日志进一步调优
在让G1 GC跑起来之后,我们下一步就是需要根据GC log,来进一步进行性能调优。首先,我们要让JVM记录比较详细的GC日志. 对于Spark而言,我们需要在SPARK_JAVA_OPTS中设置参数使得Spark保留下我们需要用到的日志. 一般而言,我们需要设置这样一串参数:
-XX:+PrintFlagsFinal
-XX:+PrintReferenceGC -verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintAdaptiveSizePolicy
-XX:+UnlockDiagnosticVMOptions
-XX:+G1SummarizeConcMark
有了这些参数,我们就可以在SPARK的EXECUTOR日志中(默认输出到各worker节点的 S P A R K H O M E / w o r k / SPARK_HOME/work/ SPARKHOME/work/app_id/$executor_id/stdout中)读到详尽的GC日志以及生效的GC 参数了。接下来,我们就可以根据GC日志来分析问题,使程序获得更优性能。我们先来了解一下G1中一次GC的日志结构。
251.354: [G1Ergonomics (Mixed GCs) continue mixed GCs,
reason: candidate old regions available,
candidate old regions: 363 regions,
reclaimable: 9830652576 bytes (10.40 %),
threshold: 10.00 %]
[Parallel Time: 145.1 ms, GC Workers: 23]
[GC Worker Start (ms): Min: 251176.0, Avg: 251176.4, Max: 251176.7, Diff: 0.7]
[Ext Root Scanning (ms): Min: 0.8, Avg: 1.2, Max: 1.7, Diff: 0.9, Sum: 28.1]
[Update RS (ms): Min: 0.0, Avg: 0.3, Max: 0.6, Diff: 0.6, Sum: 5.8]
[Processed Buffers: Min: 0, Avg: 1.6, Max: 9, Diff: 9, Sum: 37]
[Scan RS (ms): Min: 6.0, Avg: 6.2, Max: 6.3, Diff: 0.3, Sum: 143.0]
[Object Copy (ms): Min: 136.2, Avg: 136.3, Max: 136.4, Diff: 0.3, Sum: 3133.9]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.3]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 1.9]
[GC Worker Total (ms): Min: 143.7, Avg: 144.0, Max: 144.5, Diff: 0.8, Sum: 3313.0]
[GC Worker End (ms): Min: 251320.4, Avg: 251320.5, Max: 251320.6, Diff: 0.2]
[Code Root Fixup: 0.0 ms]
[Clear CT: 6.6 ms]
[Other: 26.8 ms]
[Choose CSet: 0.2 ms]
[Ref Proc: 16.6 ms]
[Ref Enq: 0.9 ms]
[Free CSet: 2.0 ms]
[Eden: 3904.0M(3904.0M)->0.0B(4448.0M) Survivors: 576.0M->32.0M Heap: 63.7G(88.0G)->58.3G(88.0G)]
[Times: user=3.43 sys=0.01, real=0.18 secs]
以G1 GC的一次mixed GC为例,从这段日志中,我们可以看到G1 GC日志的层次是非常清晰的。日志列出了这次暂停发生的时间、原因,并分级各种线程所消耗的时长以及CPU时间的均值和最值。最后,G1 GC列出了本次暂停的清理结果,以及总共消耗的时间。
而在我们现在的G1 GC运行日志中,我们明显发现这样一段特殊的日志:
(to-space exhausted), 1.0552680 secs]
[Parallel Time: 958.8 ms, GC Workers: 23]
[GC Worker Start (ms): Min: 759925.0, Avg: 759925.1, Max: 759925.3, Diff: 0.3]
[Ext Root Scanning (ms): Min: 1.1, Avg: 1.4, Max: 1.8, Diff: 0.6, Sum: 33.0]
[SATB Filtering (ms): Min: 0.0, Avg: 0.0, Max: 0.3, Diff: 0.3, Sum: 0.3]
[Update RS (ms): Min: 0.0, Avg: 1.2, Max: 2.1, Diff: 2.1, Sum: 26.9]
[Processed Buffers: Min: 0, Avg: 2.8, Max: 11, Diff: 11, Sum: 65]
[Scan RS (ms): Min: 1.6, Avg: 2.5, Max: 3.0, Diff: 1.4, Sum: 58.0]
[Object Copy (ms): Min: 952.5, Avg: 953.0, Max: 954.3, Diff: 1.7, Sum: 21919.4]
[Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 2.2]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.6]
[GC Worker Total (ms): Min: 958.1, Avg: 958.3, Max: 958.4, Diff: 0.3, Sum: 22040.4]
[GC Worker End (ms): Min: 760883.4, Avg: 760883.4, Max: 760883.4, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 96.0 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.4 ms]
[Ref Enq: 0.0 ms]
[Free CSet: 0.1 ms]
[Eden: 160.0M(3904.0M)->0.0B(4480.0M) Survivors: 576.0M->0.0B Heap: 87.7G(88.0G)->87.7G(88.0G)]
[Times: user=1.69 sys=0.24, real=1.05 secs]
760.981: [G1Ergonomics (Heap Sizing) attempt heap expansion, reason: allocation request failed, allocation request: 90128 bytes]
760.981: [G1Ergonomics (Heap Sizing) expand the heap, requested expansion amount: 33554432 bytes, attempted expansion amount: 33554432 bytes]
760.981: [G1Ergonomics (Heap Sizing) did not expand the heap, reason: heap expansion operation failed]
760.981: [Full GC 87G->36G(88G), 67.4381220 secs]
显然最大的性能下降是这样的Full GC导致的,我们可以在日志中看到类似To-space Exhausted或者To-space Overflow这样的输出(取决于不同版本的JVM,输出略有不同)。这是G1 GC收集器在将某个需要垃圾回收的分区进行回收时,无法找到一个能将其中存活对象拷贝过去的空闲分区。这种情况被称为Evacuation Failure,常常会引发Full GC。而且很显然,G1 GC的Full GC效率相对于Parallel GC实在是相差太远,我们想要获得比Parallel GC更好的表现,一定要尽力规避Full GC的出现。对于这种情况,我们常见的处理办法有两种:
将InitiatingHeapOccupancyPercent参数调低(默认值是45),可以使G1 GC收集器更早开始Mixed GC;但另一方面,会增加GC发生频率。
提高ConcGCThreads的值,在Mixed GC阶段投入更多的并发线程,争取提高每次暂停的效率。但是此参数会占用一定的有效工作线程资源。
调试这两个参数可以有效降低Full GC出现的概率。Full GC被消除之后,最终的性能获得了大幅提升。但是我们发现,仍然有一些地方GC产生了大量的暂停时间。比如,我们在日志中读到很多类似这样的片断:
280.008: [G1Ergonomics (Concurrent Cycles)
request concurrent cycle initiation,
reason: occupancy higher than threshold,
occupancy: 62344134656 bytes,
allocation request: 46137368 bytes,
threshold: 42520176225 bytes (45.00 %),
source: concurrent humongous allocation]
这里就是Humongous object,一些比G1的一个分区的一半更大的对象。对于这些对象,G1会专门在Heap上开出一个个Humongous Area来存放,每个分区只放一个对象。但是申请这么大的空间是比较耗时的,而且这些区域也仅当Full GC时才进行处理,所以我们要尽量减少这样的对象产生。或者提高G1HeapRegionSize的值减少HumongousArea的创建。不过在内存比较大的时,JVM默认把这个值设到了最大(32M),此时我们只能通过分析程序本身找到这些对象并且尽量减少这样的对象产生。当然,相信随着G1 GC的发展,在后期的版本中相信这个最大值也会越来越大,毕竟G1号称是在1024~2048个Region时能够获得最佳性能。
接下来,我们可以分析一下单次cycle start到Mixed GC为止的时间间隔。如果这一时间过长,可以考虑进一步提升ConcGCThreads,需要注意的是,这会进一步占用一定CPU资源。
对于追求更短暂停时间的在线应用,如果观测到较长的Mixed GC pause,我们还要把G1RSetUpdatingPauseTimePercent调低,把G1ConcRefinementThreads调高。前文提到G1 GC通过为每个分区维护RememberSet来记录分区外对分区内的引用,G1RSetUpdatingPauseTimePercent则正是在STW阶段为G1收集器指定更新RememberSet的时间占总STW时间的期望比例,默认为10。而G1ConcRefinementThreads则是在程序运行时维护RememberSet的线程数目。通过对这两个值的对应调整,我们可以把STW阶段的RememberSet更新工作压力更多地移到Concurrent阶段。
另外,对于需要长时间运行的应用,我们不妨加上AlwaysPreTouch参数,这样JVM会在启动时就向OS申请所有需要使用的内存,避免动态申请,也可以提高运行时性能。但是该参数也会大大延长启动时间。
最终,经过几轮GC参数调试,其结果如下表5所示。较之先前的结果,我们最终还是获得了较满意的运行效率。文章来源:https://www.toymoban.com/news/detail-825251.html

小结:综合考虑G1 GC是较为推崇的默认Spark GC机制。进一步的GC日志分析,可以收获更多的GC优化。经过上面的调优过程,我们将该应用的运行时间缩短到了4.3分钟,相比调优之前,我们获得了1.7倍左右的性能提升,而相比Parallel GC也获得了1.5倍左右的性能提升。
对于大量依赖于内存计算的Spark应用,GC调优显得尤为重要。在发现GC问题的时候,不要着急调试GC。而是先考虑是否存在Spark进程内存管理的效率问题,例如RDD缓存的持久化和释放。至于GC参数的调试,首先我们比较推荐使用G1 GC来运行Spark应用。相较于传统的垃圾收集器,随着G1的不断成熟,需要配置的选项会更少,能同时满足高吞吐量和低延迟的寻求。当然,GC的调优不是绝对的,不同的应用会有不同应用的特性,掌握根据GC日志进行调优的方法,才能以不变应万变。最后,也不能忘了先对程序本身的逻辑和代码编写进行考量,例如减少中间变量的创建或者复制,控制大对象的创建,将长期存活对象放在Off-heap中等等。文章来源地址https://www.toymoban.com/news/detail-825251.html
到了这里,关于Spark调优解析-GC调优3(七)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!