Flink学习笔记
前言:今天是学习flink的第四天啦!学习了物理分区的知识点,这一次学习了前4个简单的物理分区,称之为简单分区篇!
Tips:我相信自己会越来会好的,明天攻克困难分区篇,加油!
二、Flink 流批一体 API 开发
3. 物理分区
3.1 Global Partitioner
该分区器会将所有的数据都发送到下游的某个算子实例(subtask id = 0)
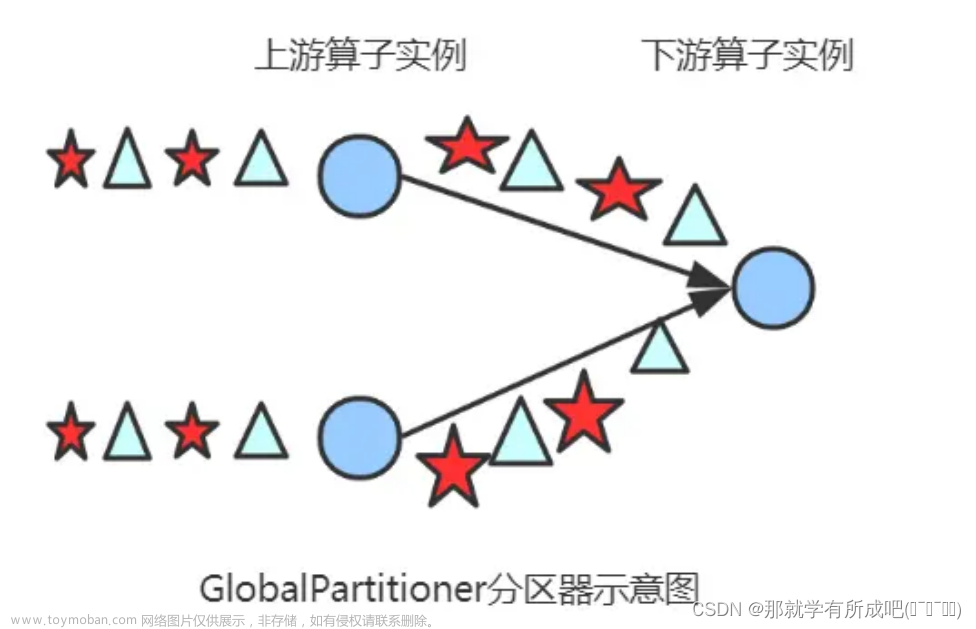
实例:编写Flink程序,接收socket的单词数据,以进程标记查看分区数据情况。
package cn.itcast.day04.partition;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
/**
* @author lql
* @time 2024-02-15 22:54:35
* @description TODO
*/
public class GlobalPartitioningDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//Source是一个非并行的Source
//并行度是1
DataStreamSource<String> lines = env.socketTextStream("node1", 9999);
// 对每个输入的数据进行映射处理,给每个单词添加上一个字符串以及当前所在的子任务编号
SingleOutputStreamOperator<String> mapped = lines.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
return value + " : " + indexOfThisSubtask;
}
}).setParallelism(3); // 针对算子将并行度设置为 3;
// 对数据流进行 global,将其随机均匀地划分到每个分区中
DataStream<String> global = mapped.global();
// 定义一个 sink 函数,输出每个单词和所在的子任务编号
global.addSink(new RichSinkFunction<String>(){
@Override
public void invoke(String value, Context context) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
System.out.println(value + "->" + index);
}
});
env.execute();
}
}
结果:
hadoop : 1->0
hadoop : 2->0
hadoop : 0->0
spark : 1->0
spark : 2->0
总结:
- 1- 多个进程处理的数据,汇总到 sink 第一个分区第一个进程
- 2- 数据多出梳理,合并一处的现象
- 3- getRuntimeContext()方法在 Rich Function 中,最后的 addSink()用心良苦!
- 4- 并行任务之间共享相同状态的场景,如全局计数器等
3.2 Shuffer Partition
根据均匀分布随机划分元素。

实例:编写Flink程序,接收socket的单词数据,并将每个字符串均匀的随机划分到每个分区。
package cn.itcast.day04.partition;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
/**
* @author lql
* @time 2024-02-15 23:26:49
* @description TODO:编写Flink程序,接收socket的单词数据,并将每个字符串均匀的随机划分到每个分区
*/
public class ShufflePartitioningDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//Source是一个非并行的Source
//并行度是1
DataStreamSource<String> lines = env.socketTextStream("node1", 9999);
//并行度2
SingleOutputStreamOperator<String> mapped = lines.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
return value + " : " + indexOfThisSubtask;
}
}).setParallelism(1);
//shuffle!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
DataStream<String> shuffled = mapped.shuffle();
shuffled.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
System.out.println(value + " -> " + index);
}
});
env.execute();
}
}
结果:
结果现象:(没有规律)
hadoop : 0 -> 0
hadoop : 0 -> 4
flink : 0 -> 6
flink : 0 -> 7
总结:
- 1- 它将数据均匀地分配到下游任务的每个并行实例中,然后再对每个并行任务的数据进行分区
- 2- 这种分发方式适用于数据量比较大的场景,可以减少网络传输压力和降低数据倾斜的概率。
3.3 Broadcast Partition
发送到下游所有的算子实例

实例:编写Flink程序,接收socket的单词数据,并将每个字符串广播到每个分区。
package cn.itcast.day04.partition;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
/**
* @author lql
* @time 2024-02-15 23:35:59
* @description TODO
*/
public class BroadcastPartitioningDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//Source是一个非并行的Source
//并行度是1
DataStreamSource<String> lines = env.socketTextStream("node1", 9999);
//并行度2
SingleOutputStreamOperator<String> mapped = lines.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
return value + " : " + indexOfThisSubtask;
}
}).setParallelism(1);
//广播,上游的算子将一个数据广播到下游所以的subtask
DataStream<String> shuffled = mapped.broadcast();
shuffled.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
System.out.println(value + " -> " + index);
}
});
env.execute();
}
}
结果:
hadoop : 0 -> 0
hadoop : 0 -> 2
hadoop : 0 -> 1
hadoop : 0 -> 3
hadoop : 0 -> 4
hadoop : 0 -> 6
hadoop : 0 -> 5
hadoop : 0 -> 7
spark : 0 -> 3
spark : 0 -> 2
spark : 0 -> 6
spark : 0 -> 4
spark : 0 -> 0
spark : 0 -> 1
spark : 0 -> 5
spark : 0 -> 7
总结:
- 均匀广播数据
3.4 Rebalance Partition
通过循环的方式依次发送到下游的task

实例:轮询发送数据
package cn.itcast.day04.partition;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author lql
* @time 2024-02-15 23:41:46
* @description TODO: flink的数据倾斜解决方案:轮询发送(当设置并行度为1时)
*/
public class RebalanceDemo {
public static void main(String[] args) throws Exception {
/**
* 构建批处理运行环境
* 使用 env.generateSequence 创建0-100的并行数据
* 使用 fiter 过滤出来 大于8 的数字
* 使用map操作传入 RichMapFunction ,将当前子任务的ID和数字构建成一个元组
* 在RichMapFunction中可以使用 getRuntimeContext.getIndexOfThisSubtask 获取子任务序号
* 打印测试
*/
//TODO 构建批处理运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//TODO 使用 env.generateSequence 创建0-100的并行数据
DataStream<Long> dataSource = env.generateSequence(0, 100);
//TODO 使用 fiter 过滤出来 大于8 的数字
SingleOutputStreamOperator<Long> filteredDataSource = dataSource.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long aLong) throws Exception {
return aLong > 8;
}
});
//解决数据倾斜的问题
DataStream<Long> rebalance = filteredDataSource.rebalance();
//TODO 使用map操作传入 RichMapFunction ,将当前子任务的ID和数字构建成一个元组
//查看92条数据分别被哪些线程处理的,可以看到每个线程处理的数据条数
//spark中查看数据属于哪个分区使用哪个函数?mapPartitionWithIndex
//TODO 在RichMapFunction中可以使用 getRuntimeContext.getIndexOfThisSubtask 获取子任务序号
SingleOutputStreamOperator<Tuple2<Long, Integer>> tuple2MapOperator = rebalance.map(new RichMapFunction<Long, Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long, Integer> map(Long aLong) throws Exception {
return Tuple2.of(aLong, getRuntimeContext().getIndexOfThisSubtask());
}
});
//TODO 打印测试
tuple2MapOperator.print();
env.execute();
}
}
结果:文章来源:https://www.toymoban.com/news/detail-825254.html
* 0-0
* 0-1
* 0-2
* 0-0
* 0-1
* 0-2
总结:文章来源地址https://www.toymoban.com/news/detail-825254.html
- 1- 轮询发送数据
- 2- 解决数据倾斜问题
到了这里,关于flink重温笔记(四):Flink 流批一体 API 开发——物理分区(上)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





