引言
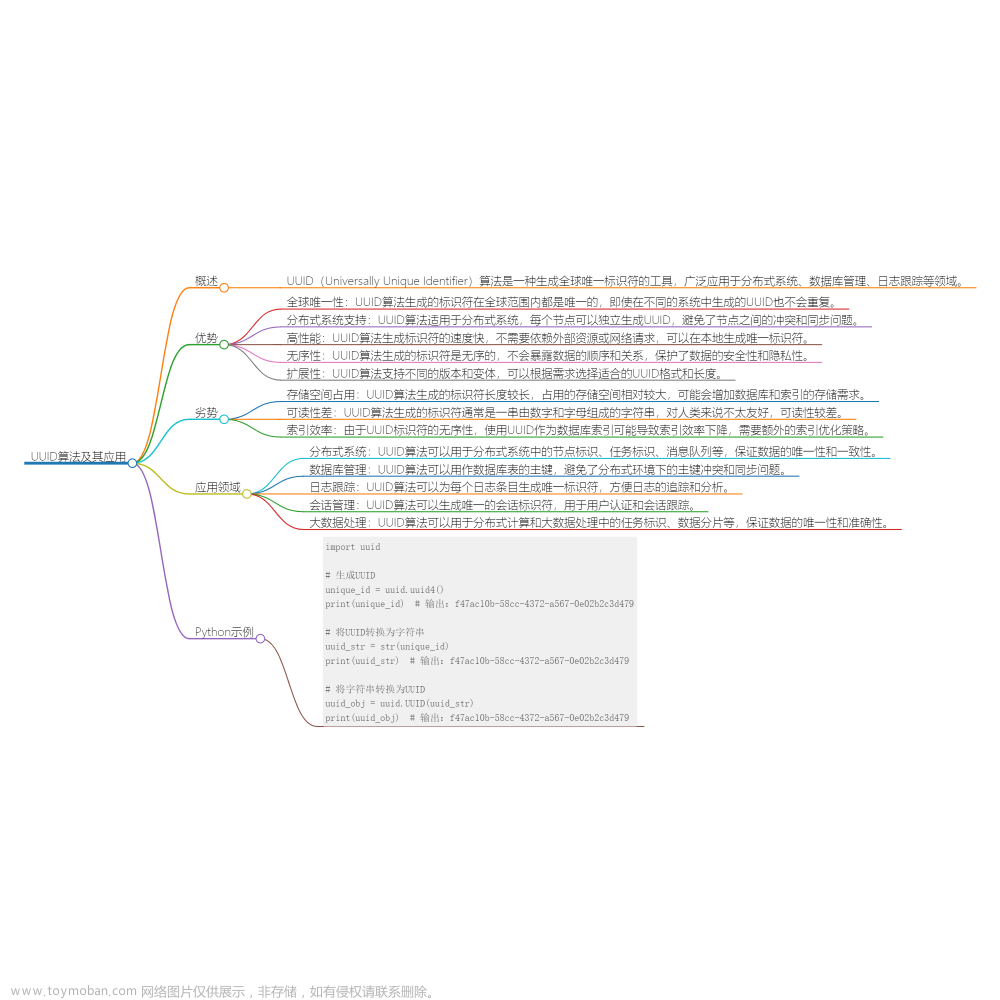
在分布式系统和大数据环境下,唯一标识符的生成和管理是一项关键任务。UUID(Universally Unique Identifier)算法应运而生,成为了解决重复数据和标识符冲突的有效工具。本文将探讨UUID算法的优势和劣势,分析其在分布式系统、大数据环境以及其他领域中的应用,同时给出Python完整示例演示UUID的生成和使用。
UUID/GUID生成器 | 一个覆盖广泛主题工具的高效在线平台(amd794.com)
https://amd794.com/uuidgenerator文章来源:https://www.toymoban.com/news/detail-825273.html
UUID算法的优势
- 全球唯一性:UUID算法可以生成全球唯一的标识符,即使在不同的系统中生成的UUID也不会重复,保证了数据的唯一性。
- 分布式系统支持:UUID算法适用于分布式系统,每个节点可以独立生成UUID,避免了节点之间的冲突和同步问题。
- 高性能:UUID算法生成标识符的速度快,不需要依赖外部资源或网络请求,可以在本地生成唯一标识符。
- 无序性:UUID算法生成的标识符是无序的,不会暴露数据的顺序和关系,保护了数据的安全性和隐私性。
- 扩展性:UUID算法支持不同的版本和变体,可以根据需求选择适合的UUID格式和长度。
UUID算法的劣势
- 存储空间占用:UUID算法生成的标识符长度较长,占用的存储空间相对较大,可能会增加数据库和索引的存储需求。
- 可读性差:UUID算法生成的标识符通常是一串由数字和字母组成的字符串,对人类来说不太友好,可读性较差。
- 索引效率:由于UUID标识符的无序性,使用UUID作为数据库索引可能导致索引效率下降,需要额外的索引优化策略。
UUID算法的应用领域
- 分布式系统:UUID算法可以用于分布式系统中的节点标识、任务标识、消息队列等,保证数据的唯一性和一致性。
- 数据库管理:UUID算法可以用作数据库表的主键,避免了分布式环境下的主键冲突和同步问题。
- 日志跟踪:UUID算法可以为每个日志条目生成唯一标识符,方便日志的追踪和分析。
- 会话管理:UUID算法可以生成唯一的会话标识符,用于用户认证和会话跟踪。
- 大数据处理:UUID算法可以用于分布式计算和大数据处理中的任务标识、数据分片等,保证数据的唯一性和准确性。
Python示例:UUID生成和使用
python
import uuid
# 生成UUID
unique_id = uuid.uuid4()
print(unique_id) # 输出:f47ac10b-58cc-4372-a567-0e02b2c3d479
# 将UUID转换为字符串
uuid_str = str(unique_id)
print(uuid_str) # 输出:f47ac10b-58cc-4372-a567-0e02b2c3d479
# 将字符串转换为UUID
uuid_obj = uuid.UUID(uuid_str)
print(uuid_obj) # 输出:f47ac10b-58cc-4372-a567-0e02b2c3d479
Copy总结
UUID算法作为一种生成唯一标识符的工具,在分布式系统和大数据环境中发挥着重要作用。它具有全球唯一性、分布式系统支持、高性能、无序性和扩展性等优势,可以解决重复数据和标识符冲突的问题。然而,UUID算法也存在存储空间占用、可读性差和索引效率等劣势。在分布式系统、数据库管理、日志跟踪、会话管理和大数据处理等领域,UUID算法都有广泛的应用。通过Python示例,我们展示了UUID的生成和使用过程。希望本文能够帮助读者更好地理解UUID算法的优势和劣势,并在实际应用中选择合适的标识符生成方案,提升系统的性能和数据的一致性。文章来源地址https://www.toymoban.com/news/detail-825273.html
到了这里,关于UUID算法:独一无二的标识符解决方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












