文章来源地址https://www.toymoban.com/news/detail-825332.html
文章来源地址https://www.toymoban.com/news/detail-825332.html
1. 聊天机器人
1.1. 人工智能往往掌握不了跨越几段对话语境的讨论
1.1.1. 抓不住连贯的主题,只能单独处理每个句子
1.1.2. 不能将其答案与现实联系起来
1.1.3. 可能会遵循语言规则、统计相关性,甚至查找有关事实来为每个新句子提供答复
1.2. 聊天机器人只是在模拟对话
1.2.1. 操纵着符号,却不了解这些符号的含义
1.2.2. 约翰·塞尔的中文房间论证
1.3. 哲学家深刻地关心真实性的问题,但商业世界并不关心
1.3.1. 对商界来说,重要的是结果,而不是产生这个结果的过程
1.4. 在现实世界的应用中
1.4.1. 一个能自动提供在线客户服务的聊天机器人
1.4.2. 一个能利用产品知识数据库回答客户问题的聊天机器人
1.4.3. 企业必不可少的工具
1.4.3.1. 能让真人腾出手来处理难度更大的咨询
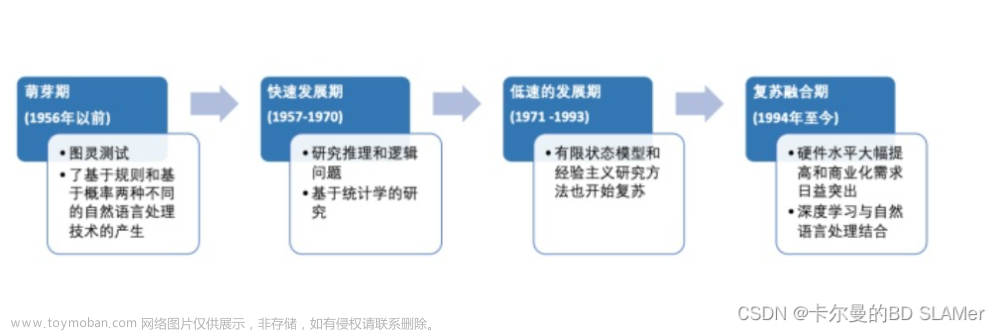
2. 语言规则
2.1. 在自然语言处理领域,诺姆·乔姆斯基是其发展史上的关键人物
2.1.1. 美国语言学家、哲学家
2.1.2. 认知科学领域(关于思维及其能力的科学研究)的创始人之一
2.1.3. 最著名的一大成果是通用语法
2.1.3.1. 在研究儿童的语言能力发展后总结出来的理论
2.1.3.2. 儿童虽然能够学会流利地说话,但他们在学习过程里其实根本没有接收到足够的信息
2.1.3.2.1. 所谓的“刺激的贫乏”
2.1.3.3. 儿童能够发展语言技能的唯一途径是他们拥有先天的沟通能力,在他们的大脑中本来就有相关的连接
2.1.3.4. 先天的语言能力可以被认为是一套语言规则,即一套通用语法
2.1.3.5. 这一想法发展为转换——生成语法的理论,也就是使用“形式语法”来描述嵌入不同语言中的规则,让人们能够比较这些语言
2.1.3.6. 这一思想在20世纪50至70年代主导了语言学,而这正是人工智能研究者开始尝试让计算机处理文字的时候
2.2. 乔姆斯基的层级结构
2.2.1. 所有形式化语法都是第0型,或无限制型(最一般的类型)
2.2.2. 只有一部分第0型语法同时也是第1型
2.2.2.1. 上下文敏感型
2.2.2.2. 这类词根据上下文可能只适合放在某个地方
2.2.3. 只有一部分第1型语法同时也是第2型
2.2.3.1. 上下文自由型
2.2.3.2. 大多数计算机编程语言的设计方式
2.2.3.3. 语句中不能有任何歧义
2.2.4. 只有一部分第2型语法同时也是第3型
2.2.4.1. 其定义的规则语言是如此简单和狭窄,以至于有限状态机都可以理解它们
2.3. 自然语言处理就是聊天机器人内部的符号人工智能
2.3.1. 目的是弄清怎么处理书面文字
2.4. 早期的聊天机器人广泛使用了乔姆斯基的理论,人们可以据此开发出清晰而精确的语言规则
2.5. 正是通过自然语言处理,研究人员现在可以将成千上万互相独立的科学论文整合对照,得出人类无法实现的新发现
3. 语料库语言学
3.1. 随着世界上越来越多的知识、商业活动和社交互动转移到互联网上,人类之间对话的数据量也有了指数级增长
3.2. 这些数据的第一个用途,是通过一种叫作决策树的人工智能方法,自动生成语言规则
3.3. 决策树流行的原因是,它们很容易理解
3.3.1. 与神经网络方法不同的是,神经网络像“黑箱”
3.3.1.1. 你不知道信息是如何存储的,也不知道决策是如何做出的
3.3.2. 在决策树中,你可以看清整个过程
3.3.2.1. 决策树就像用于机器人控制的行为树
3.4. 过度拟合
3.4.1. 人工智能学到的模型过于贴合训练数据,而不能泛化应用到新数据上
3.5. 随机森林就是把一组决策树结合在一起使用,每一个决策树都是在较小的数据子集上训练出来的,以防止过度拟合
3.6. Word2Vec
3.6.1. 目前最受欢迎的方法之一
3.6.2. 使用简单的神经网络与大量的数据来学习哪些词语的组合倾向于出现在彼此靠近的地方
3.6.3. 可以从一组上下文词汇中预测中间的词可能是什么
3.6.4. 从一个中间的词预测一组可能的上下文词汇
3.7. 卷积神经网络、强化学习和其他类型的循环神经网络、递归神经网络、注意力机制和生成模型,这都有助于计算机理解跨越多个句子的概念,并生成更好的回复
4. 交流
4.1. 人类毕竟是社会动物,我们喜欢交谈
4.1.1. 我们喜欢把字眼安排在无限变化的句子中,每个句子的含义都略有不同
4.2. 人工智能能理解文字已经难能可贵
4.2.1. 苹果的Siri、微软的Cortana、亚马逊的Echo和谷歌的Assistant都是人类现有的最复杂算法的组合
4.3. 用于交流的人工智能并不总是特别可靠
4.3.1. 只要问它们一些意想不到的问题,或者用系统没有训练过的口音提问,即使是精巧的技术也会失败
4.4. 机器不可能总是听清每个声音
4.4.1. 人工智能会将初始的理解修正为人们更有可能说出来的话语
4.4.2. 毕竟大多数人每天都会说很多相同的话
4.5. 除了几百万美元的云计算成本外,它们的碳足迹可能与五辆汽车的整个生命周期一样高
4.6. 虽然人工智能技术在训练结束后的应用可能会很高效,但创造人工智能的过程并不高效或便宜
4.7. 人工智能的许多最新研究都忽视了效率问题
4.7.1. 因为人们发现规模极大的神经网络对多种多样的任务都很有用,那些拥有丰富计算资源的公司和机构可以利用这一点来获得竞争优势
4.8. Tay
4.8.1. 2016年3月23日推出
4.8.2. 微软在2016年探索过一个方案:利用众包来提供数据,帮助他们的推特聊天机器人学习
4.8.3. 仅仅16个小时后就被匆忙关闭
4.8.4. 网友教给Tay各种粗话和与毒品相关的语句,然后它顺理成章地把这些语句推送给了众多关注者
4.9. 伪装成人类的聊天机器人可以给我们发送一些具有针对性的广告或政治信息
4.10. 舆论意见可以由此被监测和管理
4.11. 我们获取信息的方式也是由人工智能策划的
4.12. 推荐系统会监测我们在移动设备上喜欢阅读哪些内容,并向我们推送更多类似的内容,让我们看到的世界变得更加狭窄,由此进一步加强我们的偏见
4.12.1. 那些不受欢迎的政权更容易控制人民,民粹领袖也更容易赢得权力
4.13. 通过人工智能,才可以真正了解千百万人民的意见和看法,并帮助政治家和机构更好地满足人民的需求
4.14. 所有的新技术都可能被用于为善或作恶
4.14.1. 我们需要意识到人工智能的影响,并确保它得到恰当的应用
文章来源:https://www.toymoban.com/news/detail-825332.html
到了这里,关于读十堂极简人工智能课笔记06_自然语言处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!