官网教程:gem5: Classic memory system coherence
M5 2.0b4引入了一个经过大量重写和简化的缓存模型,包括一个新的一致性协议。一致性协议是用于确保多个缓存之间的数据一致性的规则和机制。这意味着在多个缓存中存储的数据将保持一致,以避免数据不一致的问题。
(在此之前的 M5 2.0 版本之前,缓存模型已经进行了修补,以适应引入的新内存系统。然而,旧的缓存模型并没有重新编写以充分利用新内存系统所提供的功能。因此,在 2.0beta 版本中,对缓存模型进行了彻底的重写,以使其能够更好地利用新内存系统的功能。)
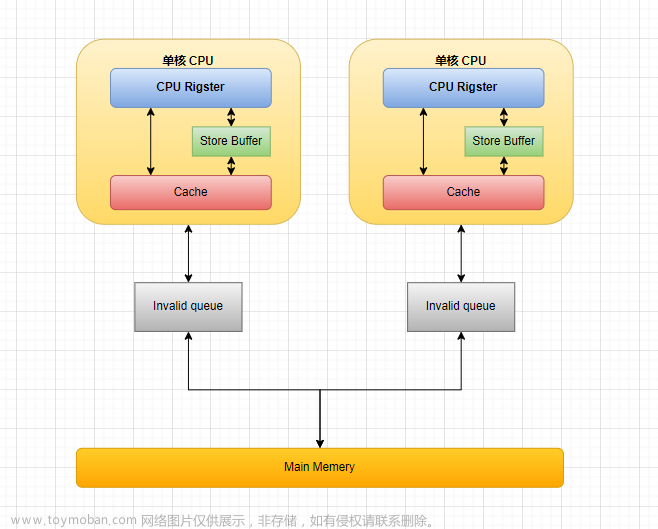
新一致性协议的关键特性是它可以与多样化的缓存层次结构(多个层次上的多个缓存)配合工作。在计算系统中,通常会使用多个层次的缓存来加速数据访问。每个层次的缓存可以存储不同级别的数据,例如 L1 缓存、L2 缓存等。旧协议将缓存之间的数据共享限制在一个总线上,这就意味着只有通过总线才能进行数据的交互和传输。
在现实世界中,系统架构对协议可以适应的缓存数量或配置有限制。由于系统的多样性和复杂性,设计一个在任意配置下都既适用又高效的协议是不切实际的。因此,在设计一致性协议时,我们需要在现实性和可配置性方面做出一些妥协。
这意味着我们可能无法找到一种通用的协议,适用于所有可能的系统配置。相反,我们采取了一种折衷的方法,以满足在(几乎)任意配置上工作的需求。这意味着协议在大多数常见的系统配置下都能有效运行,但在某些特殊或定制的配置下可能会存在限制或不够高效。
尽管如此,我们的目标是确保协议对于研究系统行为的其他方面是足够的。这意味着协议能够满足一致性方面的基本需求,并在常见的系统配置下表现出良好的性能和可靠性。然而,对于专门研究一致性的研究人员来说,他们可能更倾向于使用特定的协议来替换默认的一致性机制,以满足其研究的特定需求。
该协议是一个MOESI(Modified, Owned, Exclusive, Shared, Invalid)嗅探协议,不强制实施包含性(Inclusion)。MOESI是一种常见的缓存一致性协议,用于管理多级缓存系统中的数据一致性。它定义了不同状态来表示缓存中数据的状态,包括被修改(Modified)、被拥有(Owned)、独占(Exclusive)、共享(Shared)和无效(Invalid)。
在一个CMP(Chip-level Multiprocessing)配置中,如果有多个L1缓存,它们的总容量是共享的L2缓存容量的显著一部分。在这种情况下,强制实施包含性可能非常低效。包含性是指较低级别缓存中的数据拷贝也存在于较高级别缓存中,以确保数据的一致性。
来自较高级别缓存(靠近CPU的缓存)的请求按预期的方式向内存传播:当L1缓存发生缺失时,它会在本地L1/L2总线上广播该缺失请求,并被其他L1缓存进行嗅探。如果没有响应,那么L2缓存将提供服务。如果L2中的请求也未命中,经过一段延迟后(通常等于L2的命中延迟),L2将在其内存侧总线上发出请求,可能被其他L2缓存进行嗅探,然后发送到L3缓存或内存。
然而,逐级向上传播嗅探请求可能会引发大量难以解决的竞争条件。实际系统通常不会按照这种方式进行处理。相反,通常希望在L2总线上执行单个嗅探操作,以告知整个L1/L2层次结构中该数据块的状态。为了实现这一点,可以采用多种方法:
- 只嗅探L2缓存,但强制实施包含性,以便L2具有关于L1缓存的所有所需信息。这种方法可以确保L2缓存具有关于L1缓存的完整状态信息,但可能会导致配置上的麻烦,需要根据上层缓存的数量、大小和配置来确定较低级别缓存的标记大小。
- 在L2上保留一组额外的标记,以便可以同时嗅探它们(如Compaq Piranha)。这种方法在层次结构不太深的情况下是合理的,但需要在设计中考虑额外的标记,并根据上层缓存的配置来确定标记的大小。
- 并行嗅探L1和L2缓存,特别是当它们都位于同一芯片上时。这种方法在一些处理器架构中被使用,如Intel的Pentium Pro。然而,为了实现这种并行嗅探,需要在设计中添加显式路径,这可能导致配置过程变得复杂。
为了解决以上问题,提出了引入"express snoops"的方法。"express snoops"是一种特殊的嗅探请求,即使在系统运行于时序模式时,也可以瞬间和原子地传播到整个层次结构上。这种方法类似于前述的第二或第三种选择,但由于嗅探是沿着常规总线互连传播的,所以没有额外的配置开销。然而,这可能引入一些时间上的不准确性,但如果系统中有专用路径用于这些嗅探,或者在较低级别缓存中维护额外的上层标记副本,那么差异可能是很小的。文章来源:https://www.toymoban.com/news/detail-825504.html
最后,注意到该协议在某些配置下可能存在错误,特别是当有多个L2缓存,每个L2缓存后面有多个L1缓存时。这个问题可能在较新的版本中得到修复,但在较旧版本中,该协议在大多数有效的配置下是适用的。文章来源地址https://www.toymoban.com/news/detail-825504.html
到了这里,关于gem5学习(22):经典内存系统的一致性——Classic Memory System coherence的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!