1.HBase安装
相关版本:Hadoop:2.7.3
hbase:1.3.1
hbase相关版本下载
安装HBase需要安装hbase-1.3.1-bin.tar.gz软件包,下载并解压到/opt目录下
2.HBase参数配置
2.1 修改Master节点和Slave节点的/etc/hosts文件
#vi /etc/hosts
添加以下内容:
172.30.0.10 master
172.30.0.11 slave1
172.30.0.12 slave2

2. 2修改Master节点和Slave节点的/root/.bash_profile文件
#vi /root/.bash_profile
添加内容如下
#export HBASE_HOME = /opt/hbase-1.3.1
#export PATH = $PATH:$HBASE_HOME/bin
如图所示:
- 3修改配置文件hbase-env.sh
切换到存放hbase-env.sh文件的目录
#cd /opt/hbase-1.3.1/conf
修改内容如下
# export JAVA_HOME=/usr/java/jdk1.6.0/
# export HBASE_MANAGES_ZK=true
修改成
export JAVA_HOME=/opt/jdk1.8.0_131/
export HBASE_MANAGES_ZK=true
export HBASE_MANAGES_ZK=true表示使用自带的Zookeeper系统,HBase把Zookeeper当作自己的一部分来启动和关闭进程
2.4 修改配置文件Hbase-site.xml,添加以下内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!--设置3台节点,节点越多集群容灾能力越强,一般使用奇数台 -->
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<!-- ZooKeeper集群端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<!-- zookeeper数据路径 -->
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase-1.3.1/zk_data/</value>
</property>
</configuration>
- 5修改regionjservers文件,添加内容如下
master
slave1
slave2
3.启动Hadoop
- 1 启动Hadoop
运行HBase前需要先启动Hadoop服务。
需要切换到/hadoop/sbin目录下才能启动
#start-dfs.sh
#start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
- 2启动HBase服务
需要切换到/hbase/bin目录下
#start-hbase.sh
有HMaster说明已经开起来了,
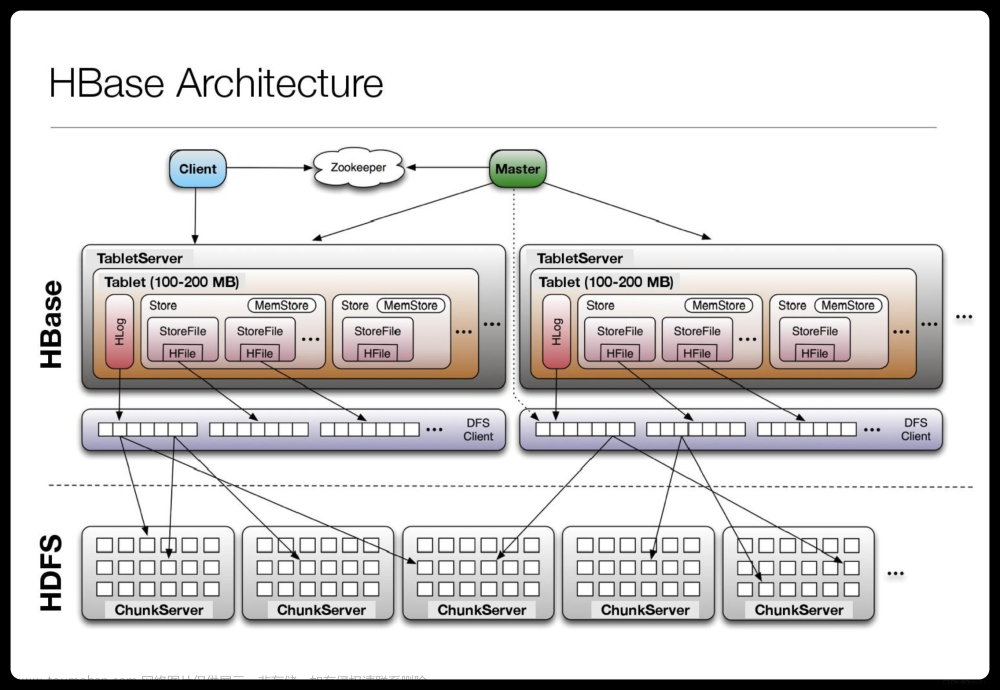
也可以登录http://master:16010查看Master信息,如下图所示:
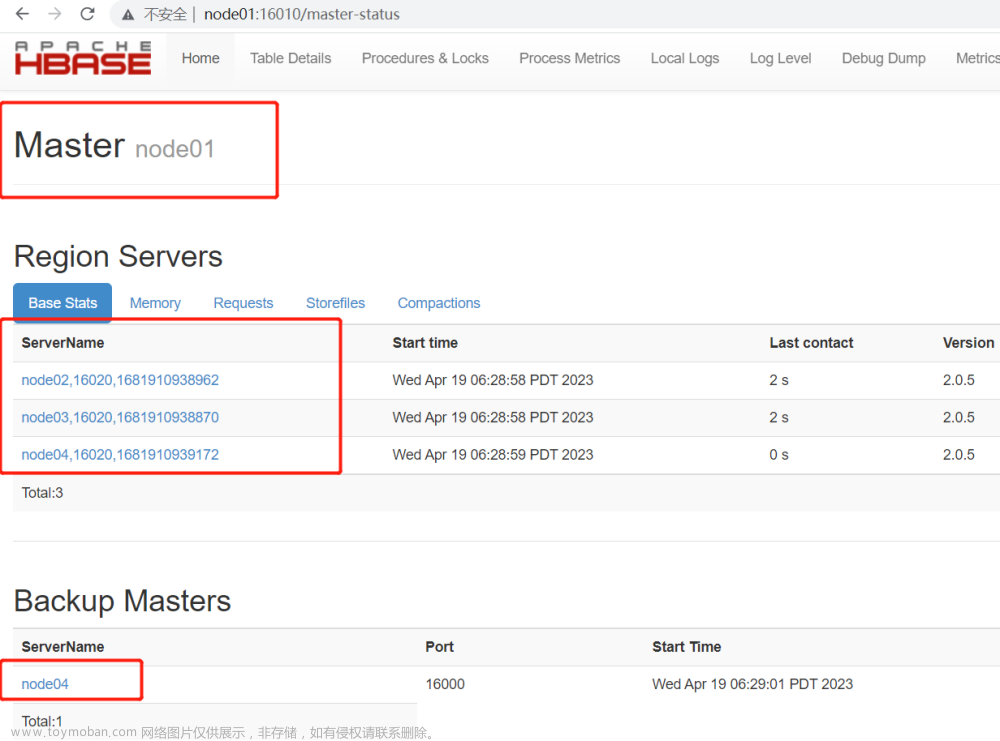
3. 3slave节点启动Backup Master服务
如果Master服务停止,Backup Master服务会自动切换到Master服务。
需要切换到/hbase/bin目录下才能执行,如图所示;
也可以登录http://slave1:16010查看Backup Master信息,如下图所示:
也可以登录http://slave1:16030查看Region Server信息。
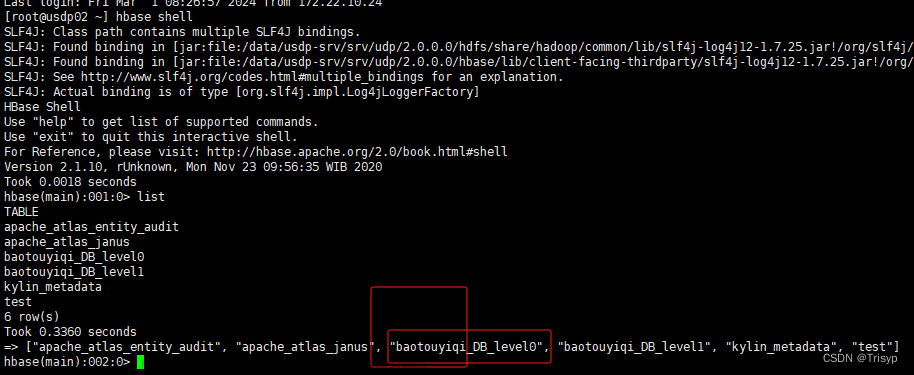
3. 4启动hbase shell
需要切换到/hbase/bin目录下执行文章来源:https://www.toymoban.com/news/detail-825909.html
#hbase shell
运行结果如下: 文章来源地址https://www.toymoban.com/news/detail-825909.html
文章来源地址https://www.toymoban.com/news/detail-825909.html
到了这里,关于HBase集群部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!