MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye View Maps
MotionNet:基于鸟瞰图的自动驾驶联合感知和运动预测
论文地址:MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye View Maps | IEEE Conference Publication | IEEE Xplore
代码地址:GitHub - pxiangwu/MotionNet: CVPR 2020, "MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird's Eye View Maps"
概要
The ability to reliably perceive the environmental states, particularly the existence of objects and their motion behavior, is crucial for autonomous driving. In this work, we propose an efficient deep model, called MotionNet, to jointly perform perception and motion prediction from 3D point clouds. MotionNet takes a sequence of LiDAR sweeps as input and outputs a bird's eye view (BEV) map, which encodes the object category and motion information in each grid cell. The backbone of MotionNet is a novel spatiotemporal pyramid network, which extracts deep spatial and temporal features in a hierarchical fashion. To enforce the smoothness of predictions over both space and time, the training of MotionNet is further regularized with novel spatial and temporal consistency losses. Extensive experiments show that the proposed method overall outperforms the state-of-the-arts, including the latest scene-flow- and 3D-object-detection-based methods. This indicates the potential value of the proposed method serving as a backup to the bounding-box-based system, and providing complementary information to the motion planner in autonomous driving.
可靠地感知环境状态的能力,尤其是物体的存在及其运动行为,对于自动驾驶至关重要。在这项工作中,我们提出了一种称为 MotionNet 的高效深度模型,以从 3D 点联合执行感知和运动预测云。MotionNet 将一系列 LiDAR 扫描作为输入并输出鸟瞰图 (BEV) 地图,该地图在每个网格单元中编码对象类别和运动信息 MotionNet 的主干是一种新颖的时空金字塔网络,它提取深度空间和分层方式的时间特征。为了加强空间和时间预测的平滑性,MotionNet 的训练进一步规范化了新的空间和时间一致性损失。广泛的实验表明,所提出的方法总体上优于最先进的方法,包括最新的基于场景流和 3D 对象检测的方法。这表明所提出的方法作为基于边界框的系统的备份的潜在价值,并为自动驾驶中的运动规划器提供补充信息。
Motivation
这篇论文旨在解决在自动驾驶领域中传统方法所无法解决的问题,即在动态环境中,基于点云数据的目标检测和运动预测是一项至关重要的任务。因此,该论文提出了一个基于时间混合网络的新方法——MotionNet,可以同时对点云数据进行目标检测和运动预测。
- 对象检测器很难泛化到训练集中从未出现过的类,从而导致下游模块出现灾难性故障。
- OGM 的一个主要弱点是难以找到细胞之间跨时间的对应关系。这使得明确地模拟对象的动力学变得困难。此外,对象类别信息通常在 OGM 中被丢弃,因此不可能考虑对交通参与者运动的类别特定约束以进行关系理解。
整体架构流程
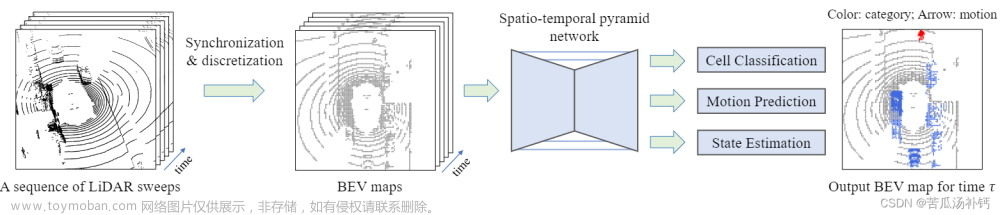
MotionNet 概述。给定一系列 LiDAR 扫描,我们首先将原始点云表示为 BEV 地图,这些地图本质上是具有多个通道的2D 图像。 BEV 图中的每个像素(单元格)都与沿高度维度的特征向量相关联。然后,我们将 BEV 映射输入时空金字塔网络(STPN) 以进行特征提取。 STPN的输出最终传递给三个head:(1)cell classification,感知每个cell的类别,比如车辆、行人或背景; (2)运动预测,预测每个细胞未来的运动轨迹; (3)状态估计,估计每个细胞当前的运动状态,如静止或运动。最终输出是 BEV 图,其中包括感知和运动预测信息。
技术细节
MotionNet管道包括三个部分:(1)从原始3D点云到BEV地图的数据表示;(2)时空金字塔网络为骨干;(3)特定任务的head,负责网格单元的分类和运动预测。
1. 自我运动补偿
输入是一系列3D点云,其中每个原始点云帧均由其本地坐标系描述。需要将所有过去的帧与当前帧同步,即通过坐标变换表示自我车辆当前坐标系内的所有点云。这对于抵消自动驾驶车辆的自我运动并避免虚假的运动估计至关重要。此外,它还为静态背景聚合了更多点,同时提供了有关运动对象运动的线索。
2. 基于BEV地图的表示
与2D图像不同,3D点云稀疏且不规则散布,因此无法使用标准卷积直接进行处理。为了解决这个问题,将点云转换为BEV地图,适用于经典2D卷积。具体来说,我们首先将3D点量化为常规体素。与Voxelnet与second通过PointNet 将每个体素内的点分布编码为高级特征不同,仅使用二进制状态作为体素的代理,指示体素是否被至少一个点占据。然后,将3D体素晶格表示为2D伪图像,其高度尺寸对应于图像通道。这样的2D图像实际上是BEV图,其中每个单元都与沿垂直轴的二进制矢量相关联。通过这种表示,可以将2D卷积应用于BEV地图而不是3D卷积。
与依靠3D体素或原始点云的现有技术相比,该方法允许使用标准2D卷积,在软件和硬件级别上都很好地支持它们,因此效率非常高。此外,BEV地图保留了高度信息以及度量空间,从而使网络可以利用先验技术对物体进行物理扩展。
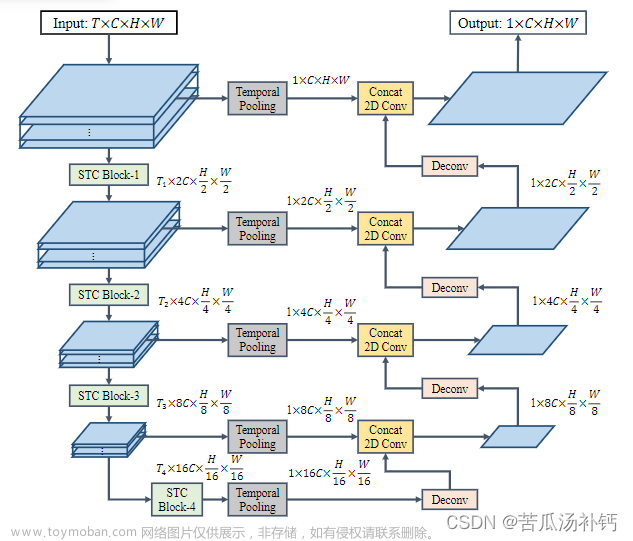
3. 时空金字塔网络
如上所述,我们模型的输入实际上是2D伪图像序列。为了有效地捕获时空特征,遵循了有关视频分类任务的最新研究精神,即建议将庞大的3D卷积替换为低成本的卷积(例如2D卷积)。但是,与经典视频分类任务仅预测整个图像序列的一个类别标签不同,该任务的目标是在当前时间对每个BEV晶格单元进行分类,并估计其未来位置。特别地,有两个问题需要解决。首先,何时以及如何汇总时间特征,时间卷积的时间对于实现良好的性能至关重要 。其次,如何提取多尺度时空特征,这些特征对于捕获密集预测任务中的局部和全局上下文都是必不可少的。
为了解决这些问题,开发了时空金字塔网络(STPN),以分层的方式沿空间和时间维度提取特征;参见图3。STPN的基本构建块是时空卷积(STC)块。每个STC块均由标准2D卷积和紧随其后的退化3D卷积组成,以分别捕获空间和时间特征。3D卷积的核大小为k×1×1,其中k对应于时间维。这样的3D滤波器本质上是伪1D卷积,因此可以降低模型的复杂性。
为了促进多尺度特征学习,STPN使用STC块在空间和时间上计算特征层次。特别是,对于空间维,以缩放比例为2的比例在多个尺度上计算特征图。类似地,对于时间维,在每次时间卷积后逐渐降低时间分辨率,从而提取不同尺度的时间语义。为了在不同级别上融合时空特征,执行全局时间池化以捕获显著的时间特征,并通过横向连接将其传递到特征解码器的上采样层。这种设计鼓励局部和全局时空上下文的流动,这有利于密集预测任务。STPN的整体结构仅依赖2D和伪1D卷积,因此非常高效。

细胞分类和状态估计头的输出可用于抑制不需要的抖动(例如,背景可能具有非零运动)。灰色:背景;蓝色:车辆。箭头:动作。 (放大以获得最佳视图。)
4. 输出头
为了生成最终输出,在STPN的末尾附加三个头:(1)单元分类头,本质上执行BEV图分割并感知每个单元格的类别;(2)运动预测头,预测未来单元的位置;(3)状态估计头,估计每个小区的运动状态(即静止或运动),并提供用于运动预测的辅助信息。
小结
在大规模nuScenes数据集上评估了方法,并与环境状态估计的不同现有技术进行了比较,包括基于场景流和对象检测的现有技术。实验结果证明了该方法的有效性和优越性。研究表明MotioNet在现实环境中对自动驾驶的潜在价值:它可以与其他模块协同工作,并为运动计划提供互补的感知和运动信息。总而言之,工作的主要贡献是:
•提出了一种名为MotionNet的新型模型,用于基于BEV地图的联合感知和运动预测。MotionNet没有边界盒,可以为自动驾驶提供补充信息;
•提出了一种新颖的时空金字塔网络,以分层方式提取时空特征。这种结构简单且效率高,因此适合实时部署。
•发展出时空一致性损失,以约束网络训练,从而增强时空预测的平滑性;
•广泛的实验验证了方法的有效性,并提供了深入的分析来说明设计背后的动机。文章来源:https://www.toymoban.com/news/detail-826116.html
本文主要介绍了一种名为MotionNet的模型,通过将LiDAR扫描转换成鸟瞰图,实现了对自动驾驶中物体的感知和运动预测。该模型采用了一种新颖的空间时间金字塔网络,可逐层提取深度的空间和时间特征。为了保证预测的平滑性,该模型还采用了新颖的空间和时间一致性损失。实验表明,MotionNet的性能优于目前最先进的方法,可以为自动驾驶提供补充信息。文章来源地址https://www.toymoban.com/news/detail-826116.html
到了这里,关于论文阅读:MotionNet基于鸟瞰图的自动驾驶联合感知和运动预测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!