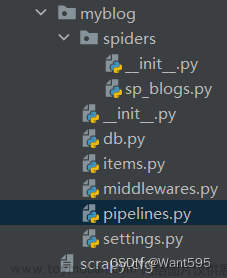
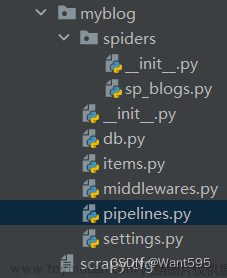
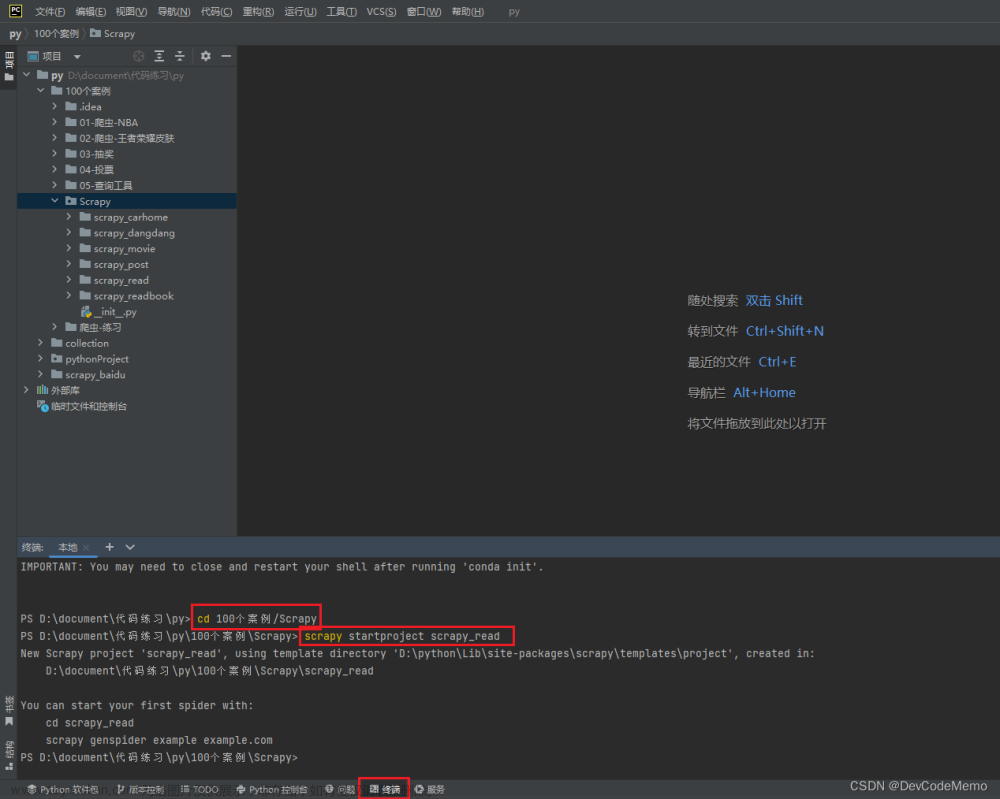
1.终端运行scrapy startproject scrapy_read,创建项目
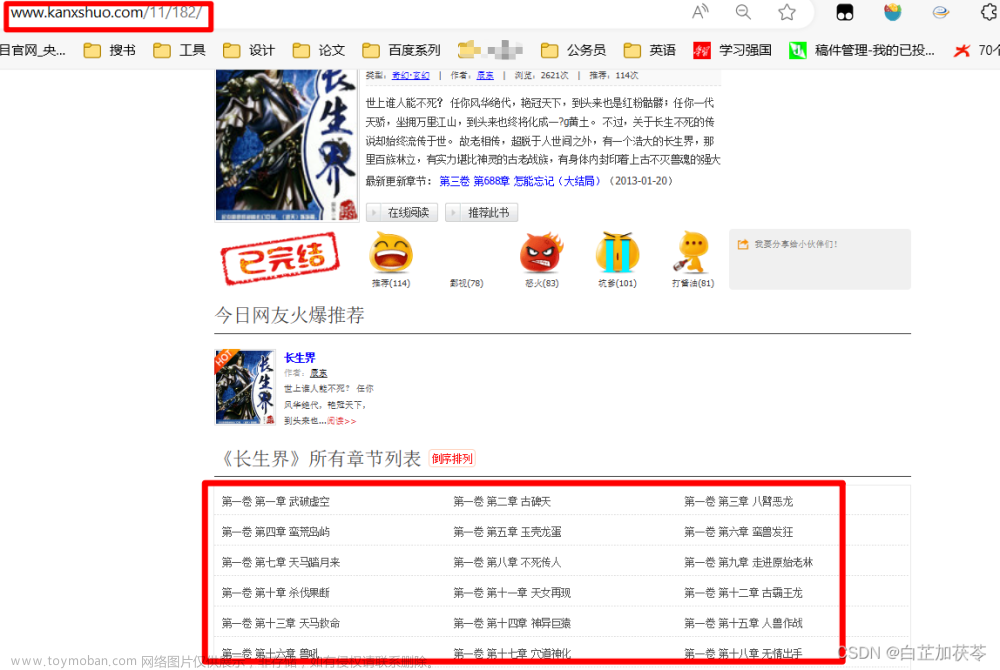
 2.登录读书网,选择国学(随便点一个)
2.登录读书网,选择国学(随便点一个)
 3.复制链接(后面修改为包括其他页)
3.复制链接(后面修改为包括其他页)

4.创建爬虫文件,并打开

5.滑倒下方翻页处,右键2,点击检查,查看到a标签网址,复制
6.修改爬虫文件规则allow(正则表达式),'\d'表示数字,'+'表示多个,'\.'使'.'生效

7.在parse_item中编写打印,scrapy crawl read运行爬虫文件

8.查看结果,成功打印,说明成功访问

9.定义数据结构(爬取的数据)
10.读书网检查查看要爬取的数据

11.使用xpath获取

12.编写代码,打印,成功爬取

13.导包,创建book对象,给到管道

14.打开管道

15.pipelines中编写代码,将数据存储到json文件中,并运行
 16.数据从第二页开始,缺少第一页数据
16.数据从第二页开始,缺少第一页数据 17.不符合规则,修改起始url
17.不符合规则,修改起始url
18.修改后,数据包含第一页数据
19.MySQL创建存储数据的表如下

20.settings中填写连接数据库所需的变量,根据自己的数据库填写

21.创建管道,编写代码,用来保存数据
1).建立连接
2).执行数据插入
3).关闭连接

22.settings中启动管道

23.运行,查看成功存储到数据库文章来源:https://www.toymoban.com/news/detail-826154.html
 文章来源地址https://www.toymoban.com/news/detail-826154.html
文章来源地址https://www.toymoban.com/news/detail-826154.html
到了这里,关于爬虫学习笔记-scrapy链接提取器爬取读书网链接写入MySQL数据库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!