前言
作者:小蜗牛向前冲
如果觉的博主的文章还不错的话,还请
点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正
本期学习:htpp协议,认识URL, 理解htpp协议的基本结构,写一个简单的http协议。
目录
一 、Http协议基础知识
1、基本概念
2、htpp基本结构
2.1认识URL
2.2urlencode和urldecode
2.3其他属性
二、基于Http服务器
1、htppserver服务器
2、Protool.hpp
3、Util.hpp
4、wwwroot
5、程序运行后的细节
一 、Http协议基础知识
1、基本概念
HTTP协议是一种无状态、应用层的协议,它定义了客户端和服务器之间进行通信的规则。它使用请求-响应的模式,客户端发送HTTP请求到服务器,服务器则返回相应的HTTP响应。
在HTTP中,客户端是发起请求的一方,通常是一个Web浏览器,而服务器是接收请求并提供响应的一方。客户端发送一个由请求方法(如GET、POST、PUT等)和URL组成的请求,包含一些附加的请求头信息(如Host、User-Agent等)。服务器解析请求并返回响应,响应包含一个状态码(如200表示成功、404表示未找到等),响应头信息(如Content-Type、Content-Length等),以及可选的响应体(即实际传输的数据)。
HTTP协议的特点包括:
- 简单:HTTP的请求和响应是基于文本的,使用简单明了的格式,易于阅读和理解。
- 无状态:每个请求都是独立的,并不会记住之前的请求状态,每次请求都需要重新验证身份等信息。
- 可扩展:通过HTTP的头部字段和方法,可以扩展和增加功能。
- 资源定位:使用URL定位和标识资源。
对于htpp的请求和响应对是对于的协议格式如下:
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-4.png)
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-5.png)
文章来源地址https://www.toymoban.com/news/detail-826218.html
2、htpp基本结构
2.1认识URL
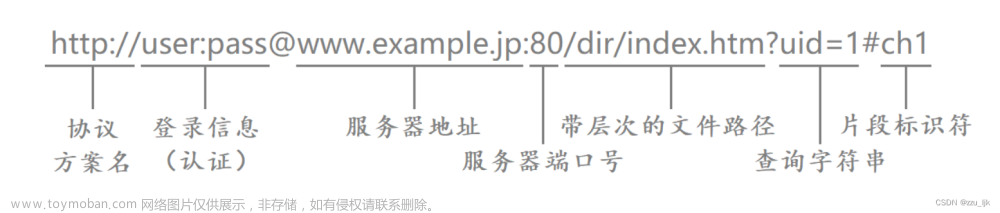
URL(Uniform Resource Locator,统一资源定位符)是用于标识和定位互联网上资源的字符串格式。它是Web浏览器、Web服务器等互联网应用程序中用来访问资源的标准格式。
基本组成:
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-6.png)
协议(Protocol):指定了访问资源所使用的协议,如 HTTP、HTTPS、FTP 等。例如,在
http://或https://中,http和https就是协议。主机名(Host):指定了资源所在的主机(服务器)的域名或IP地址。例如,在
https://www.example.com中,www.example.com就是主机名。端口号(Port):指定了用于访问资源的端口号。端口号是一个可选项,如果未指定,则使用默认端口。例如,在
https://www.example.com:443中,443就是端口号。常用的HTTP协议默认端口号是80,HTTPS协议默认端口号是443。路径(Path):指定了资源在服务器上的路径。它是资源的具体位置。例如,在
https://www.example.com/path/to/resource中,/path/to/resource就是路径。查询字符串(Query String):指定了向服务器传递的参数。它以
?开头,多个参数之间使用&分隔。例如,在https://www.example.com/search?q=keyword&page=1中,?q=keyword&page=1就是查询字符串。片段标识符(Fragment Identifier):用于标识资源中的一个特定部分。它以
#开头。例如,在https://www.example.com/page#section1中,#section1就是片段标识符。
2.2urlencode和urldecode
urlencode:urlencode 函数是用于将 URL 中的特殊字符转换为 %xx 格式的编码形式,其中 xx 是字符的 ASCII 码的十六进制表示。
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-7.png)
我们在网站搜索C++关键字,这时就被 urlencode解析为了c%2B%2B
urldecode:urldecode 函数则是对 URL 编码后的字符串进行解码,将 %xx 格式的编码字符还原为原始字符。
urldecode就是urlencode的逆过程;
2.3其他属性
HTTP的方法:
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-8.png)
GET 方法和 POST 方法是 HTTP 协议中最常用的两种请求方法,它们之间有以下几个主要区别:
数据传输方式:
- GET 方法:通过 URL 向服务器传递数据。数据被包含在 URL 的查询字符串中,以
?开头,多个参数之间使用&分隔。因此,GET 请求的数据在 URL 中是可见的,可以被用户和其他应用程序轻易看到。- POST 方法:通过 HTTP 请求体向服务器传递数据。数据不会显示在 URL 中,而是以表单形式隐式地传递给服务器。因此,POST 请求的数据对于用户来说是不可见的。
数据长度限制:
- GET 方法:由于数据是作为 URL 的一部分传递的,所以传输的数据量受到 URL 长度的限制,不同浏览器和服务器对 URL 长度的限制不同,通常在 2KB 到 8KB 之间。
- POST 方法:由于数据是通过请求体传递的,所以数据量通常没有明确的限制,但是服务器和应用程序可能会设置最大允许的请求体大小。
安全性:
- GET 方法:由于数据在 URL 中可见,因此不适合传输敏感数据,如密码等,因为敏感数据容易被截获或篡改。
- POST 方法:由于数据不会显示在 URL 中,因此更适合传输敏感数据,提供了更高的安全性。
可缓存性:
- GET 方法:请求可被缓存,如果相同的请求再次发送,则可能从缓存中获取响应,以提高性能。
- POST 方法:请求通常不会被缓存,因为它们可能对服务器产生更改或副作用。
注意:POST虽然比GET安全点,但是并不意味着他是安全的
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
HTTP常见Header
- Content-Type: 数据类型(text/html等);
- Content-Length: Body的长度;
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
二、基于Http服务器
实现一个最简单的HTTP服务器, 只在网页上输出 "自己定义的内容"; 按照HTTP协议的要求构造数据,更好的理解htpp服务器。
1、htppserver服务器
htppserver.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <functional>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/wait.h>
#include <signal.h>
#include "Protocol.hpp"
namespace server
{
enum
{
USAGE_ERR = 1,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR
};
static const uint16_t gport = 8080;
static const int gbacklog = 5;
using func_t = std::function<bool(const HttpRequest &, HttpResponse &)>;
class HttpServer
{
public:
HttpServer(func_t func, const uint16_t &port = gport) : _func(func), _listensock(-1), _port(port)
{
}
void initServer()
{
// 1. 创建socket文件套接字对象
_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (_listensock < 0)
{
exit(SOCKET_ERR);
}
// 2. bind绑定自己的网络信息
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY;
if (bind(_listensock, (struct sockaddr *)&local, sizeof(local)) < 0)
{
exit(BIND_ERR);
}
// 3. 设置socket 为监听状态
if (listen(_listensock, gbacklog) < 0) // 第二个参数backlog后面在填这个坑
{
exit(LISTEN_ERR);
}
}
void HandlerHttp(int sock)
{
// 1. 读到完整的http请求
// 2. 反序列化
// 3. httprequst, httpresponse, _func(req, resp)
// 4. resp序列化
// 5. send
char buffer[4096];
HttpRequest req;
HttpResponse resp;
size_t n = recv(sock, buffer, sizeof(buffer) - 1, 0); // 大概率我们直接就能读取到完整的http请求
if (n > 0)
{
buffer[n] = 0;
req.inbuffer = buffer;
req.parse();
_func(req, resp); // req -> resp
send(sock, resp.outbuffer.c_str(), resp.outbuffer.size(), 0);
}
}
void start()
{
for (;;)
{
// 4. server 获取新链接
// sock, 和client进行通信的fd
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int sock = accept(_listensock, (struct sockaddr *)&peer, &len);
if (sock < 0)
{
continue;
}
// version 2 多进程版(2)
pid_t id = fork();
if (id == 0) // child
{
close(_listensock);
if (fork() > 0)
exit(0);
HandlerHttp(sock);
close(sock);
exit(0);
}
close(sock);
// father
waitpid(id, nullptr, 0);
}
}
~HttpServer() {}
private:
int _listensock; // 不是用来进行数据通信的,它是用来监听链接到来,获取新链接的!
uint16_t _port;
func_t _func;
};
} // namespace serverhtppserver.cc
#include "HttpServer.hpp"
#include <memory>
using namespace std;
using namespace server;
void Usage(std::string proc)
{
cerr << "Usage:\n\t" << proc << " port\r\n\r\n";
}
// 文件后缀来生成相应的 Content-Type 字符串
std::string suffixToDesc(const std::string suffix)
{
std::string ct = "Content-Type: ";
if (suffix == ".html")
ct += "text/html";
else if (suffix == ".jpg")
ct += "application/x-jpg"; // application申请
ct += "\r\n";
return ct;
}
// 1. 服务器和网页分离,html
// 2. url -> / : web根目录
bool Get(const HttpRequest &req, HttpResponse &resp)
{
// for test
cout << "----------------------http start---------------------------" << endl;
cout << req.inbuffer << std::endl;
std::cout << "method: " << req.method << std::endl;
std::cout << "url: " << req.url << std::endl;
std::cout << "httpversion: " << req.httpversion << std::endl;
std::cout << "path: " << req.path << std::endl;
std::cout << "suffix: " << req.suffix << std::endl;
std::cout << "size: " << req.size << "字节" << std::endl;
cout << "----------------------http end---------------------------" << endl;
std::string respline = "HTTP/1.1 200 OK\r\n";
std::string respheader = "Content-Type: text/html\r\n";
respheader += "Set-Cookie: name=1234567abcdefg; Max-age=120\r\n"; // 这个 Cookie 的最大有效期是 120 秒。
std::string respblank = "\r\n";
// std::string body = "<html lang=\"en\"><head><meta charset=\"UTF-8\"><title>for test</title><h1>hello world</h1></head><body><p>北京交通广播《一路畅通》“交通大家谈”节目,特邀北京市交通委员会地面公交运营管理处处长赵震、北京市公安局公安交通管理局秩序处副处长 林志勇、北京交通发展研究院交通规划所所长 刘雪杰为您解答公交车专用道6月1日起社会车辆进出公交车道须注意哪些?</p></body></html>";
std::string body;
body.resize(req.size + 1);
if (!Util::readFile(req.path, (char *)body.c_str(), req.size))
Util::readFile(html_404, (char *)body.c_str(), req.size);
respheader += "Content-Length";
respheader += std::to_string(body.size());
respheader += "\r\n";
resp.outbuffer += respline;
resp.outbuffer += respheader;
resp.outbuffer += respblank;
cout << "----------------------http response start---------------------------" << endl;
std::cout << resp.outbuffer << std::endl;
cout << "----------------------http response end---------------------------" << endl;
resp.outbuffer += body;
return true;
}
// ./httpServer 8080
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(0);
}
uint16_t port = atoi(argv[1]);
unique_ptr<HttpServer> httpsvr(new HttpServer(Get, port));
httpsvr->initServer();
httpsvr->start();
return 0;
}2、Protool.hpp
服务器的请求和响应
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include "Util.hpp"
const std::string sep = "\r\n";
const std::string default_root = "./wwwroot";
const std::string home_page = "index.html";
const std::string html_404 = "wwwroot/404.html";
class HttpRequest
{
public:
HttpRequest() {}
~HttpRequest() {}
void parse()
{
// 1. 从inbuffer中拿到第一行,分隔符\r\n
std::string line = Util::getOneLine(inbuffer, sep);
if (line.empty())
return;
// 2. 从请求行中提取三个字段
// std::cout << "line: " << line << std::endl;
std::stringstream ss(line);
ss >> method >> url >> httpversion; // method方法
// 3. 添加web默认路径
path = default_root; // ./wwwroot,
path += url; //./wwwroot/a/b/c.html, ./wwwroot/
if (path[path.size() - 1] == '/')
path += home_page;
// 4. 获取path对应的资源后缀
// ./wwwroot/index.html
// ./wwwroot/test/a.html
// ./wwwroot/image/1.jpg
auto pos = path.rfind(".");
if (pos == std::string::npos)
suffix = ".html";
else
suffix = path.substr(pos);
// 5 获取资源大小
struct stat st; // struct stat 是用于获取文件或文件系统状态信息的结构体
int n = stat(path.c_str(), &st);
if (n == 0)
size = st.st_size;
else
size = -1;
}
public:
std::string inbuffer;
// std::string reqline;
// std::vector<std::string> reqheader;
// std::string body;
std::string method;
std::string url;
std::string httpversion;
std::string path;
std::string suffix;
int size;
std::string parm;
};
class HttpResponse
{
public:
std::string outbuffer;
};3、Util.hpp
这里完成文件的读取
#pragma once
#include <iostream>
#include <string>
#include <fstream>
#include <fcntl.h>
class Util
{
public:
// XXXX XXX XXX\r\nYYYYY
// 找到空行的出现
static std::string getOneLine(std::string &buffer, const std::string &sep)
{
auto pos = buffer.find(sep);
if (pos == std::string::npos)
return "";
std::string sub = buffer.substr(0, pos);
buffer.erase(0, sub.size() + sep.size());
return sub;
}
static bool readFile(const std::string resource, char *buffer, int size)
{
std::ifstream in(resource, std::ios::binary); // 读取文件
if (!in.is_open())
return false;
in.read(buffer, size);
in.close();
return close;
}
};4、wwwroot
在这里完成网站的设计,这里注意使用的是Html
网站的首页
网页中我们设计二个板块新闻,电商,梅花图片,账号密码的设计 。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>我的首页</title>
</head>
<body>
<h1>我是网站的首页</h1>
<!-- <img src="https://img1.baidu.com/it/u=2812417321,4100104782&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750" alt="石榴花"> -->
<!-- <a href="http://pic1.win4000.com/wallpaper/c/5799c80de4900.jpg"></a> -->
<a href="/test/a.html">新闻</a>
<a href="/test/c.html">电商</a>
<img src="/image/1.jpg" alt="梅花">
<form action="/a/b/c.py" method="POST">
姓名:<br>
<input type="text" name="xname">
<br>
密码:<br>
<input type="password" name="ypwd">
<br><br>
<input type="submit" value="登陆">
</form>
</body>
</html>网站新闻设计
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>a网页</title>
</head>
<body>
<h1>我是a网页,负责新闻的入口</h1>
<a href="/">返回</a>
</body>
</html>网站的电商设计
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>b网页</title>
</head>
<body>
<h1>我是b网页,负责电商的入口</h1>
<a href="/">返回</a>
</body>
</html>网站报错误
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>资源不存在</title>
</head>
<body>
<h1>你所访问的资源并不存在,404!</h1>
</body>
</html>5、程序运行后的细节
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-9.png)
服务器运行后,我们在网站上输入自己的主机号:端口号
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-10.png) 当我们点击新闻时候,会跳转在新闻网站,这是对应的是Http的长链接
当我们点击新闻时候,会跳转在新闻网站,这是对应的是Http的长链接
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-11.png)
HTTP协议中的长连接(Keep-Alive)是一种在单个TCP连接上可以传送多个HTTP请求和响应的机制。在默认情况下,HTTP/1.0 版本中的每个请求/响应交互都需要建立一个新的TCP连接,处理完成后即关闭连接。而长连接则允许在一次TCP连接中传输多个请求和响应,而不需要每次都重新建立连接。
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-12.png)
账号输入密码,我们就可以进行跳转
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-13.png)
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-14.png)
Htpp协议的会话保持
HTTP协议的会话保持是一种机制,用于在客户端和服务器之间保持持久的连接状态,使得在多个HTTP请求之间能够保持同一个会话的相关信息。通常,会话保持是通过使用Cookie或者URL重写的方式实现的。
Cookie:
- Cookie 是一种在客户端存储的小型数据片段,由服务器通过 HTTP 响应头发送给客户端,客户端会将其保存起来,在以后的请求中通过 HTTP 请求头发送给服务器。
- 通过在客户端存储会话标识符等信息,服务器可以在多个HTTP请求之间识别出同一个用户的会话,并保持会话状态。
- 使用 Cookie 的方式可以实现更加灵活和复杂的会话管理,例如,可以存储用户的登录状态、购物车信息等。
URL 重写:
- URL 重写是一种在URL中包含会话标识符的方式,通过在每个URL后面添加会话标识符参数来实现会话保持。
- 服务器会将会话标识符作为参数附加在URL后面,客户端在每个请求中都需要将该标识符带回服务器。
- 虽然URL重写可以实现基本的会话保持,但其缺点是会在URL中暴露会话信息,可能存在安全隐患,并且会导致URL的长度增加,影响可读性。
文章来源:https://www.toymoban.com/news/detail-826218.html
![[计算机网络]---Http协议,网络,计算机网络](https://imgs.yssmx.com/Uploads/2024/02/826218-15.png)
Linux命令
mv 是 Linux 和 Unix 操作系统中用于移动或重命名文件和目录的命令。它的基本语法如下:
mv [options] source destination
mv 命令选项包括:
-i, --interactive: 在执行前进行交互式确认,防止覆盖已存在的目标文件。
-u, --update: 仅在源文件比目标文件新或目标文件不存在时才执行移动操作。
-b, --backup[=CONTROL]: 在移动文件前进行备份,可以指定备份的方式,如 -b 或 -b=numbered。
-f, --force: 强制执行移动操作,即使目标文件已存在,也会覆盖。例子:
1 将文件从一个目录移动到另一个目录:
mv /path/to/sourcefile /path/to/destination/
2 重命名文件:
mv oldfile.txt newfile.txt
3 移动并覆盖目标文件
mv -f sourcefile.txt /path/to/destination/
4 移动目录:
mv /path/to/sourcedir /path/to/destination/
到了这里,关于[计算机网络]---Http协议的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!