线性表的链式存储结构正是所谓的单链表,何谓单链表?通过地址将每一个数据元素串起来,进行使用,这可以弥补顺序表在进行任意位置的插入和删除需要进行大量的数据元素移动的缺点,只需要修改指针的指向即可;单链表的种类又可划分为很多种,本篇博客详细介绍带头结点单链表的设计与实现,掌握单链表的关键是要进行画图分析;单链表同时也是笔试和面试的必考点,因此,掌握好该章节非常重要!
一、单链表的基本概念和结构
线性表的链式存储结构正是所谓的单链表,那么什么是链式存储结构?线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存未被占用的任意位置。链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
1.1 带头结点单链表的概念
单链表的整体结构由一个个的结点组成,每个结点类型包括两个部分:存储的数据元素(数据域)和存放下一个结点地址的指针域(它是一个指向下一个结点的指针,存储的是下一个结点的地址),所谓带头结点,是因为它存在一个标记结点,它的数据域可以不指定,它的指针域存储的是第一个有效结点的地址,通过指针域便可以访问每一个结点,尾结点是最后一个数据元素,因此它的指针域为:NULL;
带头结点的单链表主要包括两部分:指向头结点的指针,即头指针和存储单链表有效数据元素个数的size变量,请注意,与顺序表不同,单链表的结点是按需向堆区动态申请,而不是直接进行扩容,用一个结点,向堆区申请一个结点,因此,它不需要来记录链表总容量的capacity变量。
头结点与头指针的异同:

1.2 带头结点的单向链表的结构

如上所示,清晰的展示了带头结点的单链表结构,需要注意的是:单链表的每一个结点是在堆区进行申请的,而单链表的头指针和有效数据元素个数变量是在栈区开辟的!

二、单链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
2.1. 单向或者双向

2.2 带头或者不带头

2.3 循环或者非循环

虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:

1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
三、带头结点的单向链表接口实现(增删改查函数实现)及算法效率分析
引入的头文件:
#include "SeqList.h"
#include<assert.h>
#include<stdlib.h>单链表的主要操作为增删改查,这里详细展示这些基本操作的实现思想和画图分析以及代码实现和算法效率分析,主要接口函数如下所示:
注意:单链表与顺序表不同,由于它是按需索取,因此,不需要进行判满和扩容操作;
//代码实现 -- 算法效率分析
//1.初始化链表
void InitList(PList plist);
//2.清空链表 --- 释放有效结点(头结点未释放)
void ClearList(PList plist);
//3.销毁链表 -- 释放所有结点
void DestoryList(PList plist);
//4.获取链表的数据元素个数
int GetSize(const PList plist);
//5.链表判空
bool IsEmpty(const PList plist);
//6.头插数据元素
void Push_Front(PList plist, ElemType val);
//7.尾插数据元素
void Push_Back(PList plist, ElemType val);
//按位置插入 插入的第几个有效结点
bool Insert_Pos(PList plist, int pos, ElemType val);
//8.在指定结点之前插入数据元素
bool Insert_Prev(PList plist, Node* ptr, ElemType val);
//9.在指定结点之后插入数据元素
bool Insert_Next(PList plist, Node* ptr, ElemType val);
//10.头删
bool Pop_Front(PList plist);
//11.尾删
void Pop_Back(PList plist);
//按位置删除
bool Delete_Pos(PList plist, int pos, ElemType val);
//12.删除指定结点的前驱结点
bool Erase_Prev(PList plist, Node* ptr);
//13.删除指定结点的后继结点
bool Erase_Next(PList plist, Node* ptr);
//14.删除与val值相等的所有数据结点
void Remove_All(PList plist, ElemType val);
//15.打印链表中的数据元素
void PrintList(const PList plist);
//查找操作,按值查找
//16.返回与val值相等的结点
Node* FindValue(const PList plist, ElemType val);
//17.返回与val值相等的前驱结点
Node* FindValue_Prev(const PList plist, ElemType val);
//18.返回与val值相等的后继结点
Node* FindValue_Next(const PList plist, ElemType val);
//查找操作,按位置查找
//19.返回pos位置的结点
Node* FindPos(const PList plist, int pos);
//20.返回pos位置的前驱结点
Node* FindPos_Prev(const List plist, int pos);
//21.返回pos位置的后继结点
Node* FindPos_Next(const List plist, int pos);3.1 结点设计
每个结点包括两个部分:存储数据的数据域和指针域(指向下一个结点/存储下一个结点地址的指针)构成。因此设计结点主要设计这两个成员变量。
强调结构体自身引用(自己嵌套自己必须使用struct,即使使用typedef关键字进行重命名)结构体内部不可以定义自身的结构体变量,但是可以定义自身结构体指针变量,因为指针与类型无关,占用内存空间就是4个字节!

typedef int ElemType;
typedef struct Node
{
ElemType data; //数据域
struct Node* next; //指针域,保存下一个结点的地址(指向下一个结点)结点类型的指针
}Node;3.2 带头结点单链表设计
带头结点的单链表主要包括两个部分:一个指向头结点的头指针,另一个是记录单链表有效数据个数的变量。

typedef struct SingleLink
{
Node* head; //头指针,指向头结点的指针
int cursize; //有效结点个数
}List, * PList;3.3 单链表的初始化
单链表的初始化主要是申请一个头结点和对有效数据个数进行初始化赋值,为方便后续操作,把申请一个结点封装成函数,后续直接调用。
//申请结点封装成函数,方便后续代码复用
static Node* BuyNode(ElemType data, Node* next)
{
Node* p = (Node*)malloc(sizeof(Node));
assert(p!=NULL);
{
p->data = data;
p->next = next;
}
return p;
}
//1.初始化链表
void InitList(PList plist)
{
assert(plist != NULL);
plist->head = BuyNode(0, NULL); //头部标记结点
assert(plist->head != NULL);
plist->cursize = 0;
}3.4 清空链表(只保留头结点)
思想:文章来源:https://www.toymoban.com/news/detail-826357.html
空链表的标志是:头结点的指针域为NULL,依次进行指针域贯穿,删除有效结点即可;
注意事项:
使用连续指向符,需要进行防止空指针解引用崩溃,边界进行判断,如链表为空,链表只有一个有效结点等;

//2.清空链表 --- 释放有效结点(头结点未释放)
void ClearList(PList plist)
{
assert(plist != NULL);
while (plist->head->next != NULL) //依次删除有效结点
{
//1.结点指针保存待删除结点的地址
Node* p = plist->head->next;
//2.进行贯穿
plist->head->next = p->next;
//3.释放待删结点
free(p);
plist->cursize--;
}
}3.5 销毁单链表(头结点+有效结点全部销毁)
思想:
直接调用清空函数,再销毁头结点即可;
void DestoryList(PList plist)
{
assert(plist != NULL);
if (plist->head == NULL)
return;
ClearList(plist);
free(plist->head); //防止野指针
}3.6 获取链表有效数据元素个数
思想:
第一种:直接返回记录链表的有效数据元素个数的变量
第二种:计数器思想,遍历链表,直到遍历到尾结点的指针域为NULL;
//4.获取链表的数据元素个数
第一种:直接返回
int GetSize(const PList plist)
{
assert(plist != NULL);
return plist->cursize;
}
第二种:遍历链表计数器思想
int GetSize(const PList plist)
{
assert(plist != NULL);
int count=0;
for(Node*p=plist->head->next;p->next!=NULL;p=p->next)
{
count++;
}
return count;
}3.7 链表判空
思想:
第一种:比较记录的有效数据元素个数是否为0
第二种:判断头结点的指针域是否为空,如果为空代表没有有效结点
//5.链表判空
bool IsEmpty(const PList plist)
{
assert(plist!=NULL);
return plist->head->next == NULL;
//return plist->cursize == 0;
}3.8 头插数据
思想:
申请一个结点,把他插入到第一个有效数据结点的前面;
注意事项:
先牵右手再牵左手!!!防止内存泄漏

//6.头插数据元素
void Push_Front(PList plist, ElemType val)
{
assert(plist != NULL);
Node* p = BuyNode(val, NULL);
assert(p != NULL);
//先牵右手
p->next = plist->head->next;
//再牵左手
plist->head->next = p;
plist->cursize++;
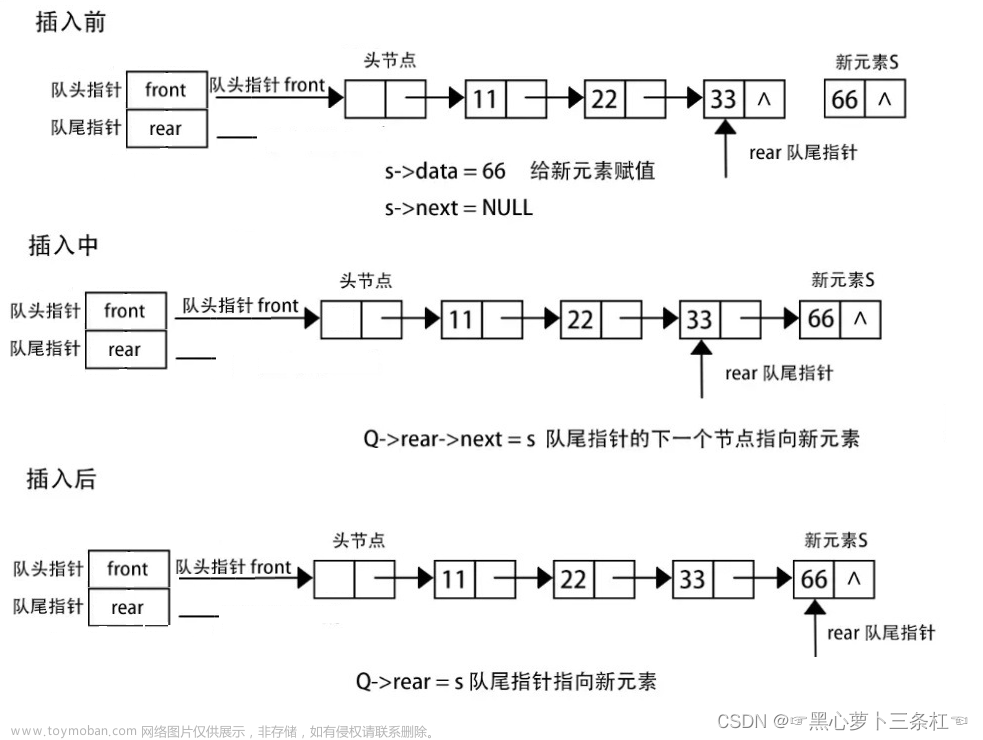
}3.9 尾插数据
思想:
先申请一个结点,然后找到尾巴结点,最后把这个结点通过指针域连接起来
//7.尾插数据元素
void Push_Back(PList plist, ElemType val)
{
assert(plist != NULL);
Node* newnode = BuyNode(val, NULL);
assert(newnode != NULL);
Node* p = plist->head;
while (p->next != NULL)
{
p = p->next;
}
p->next = newnode;
plist->cursize++;
}3.10 任意位置插入数据
思想:
先申请一个结点,再找到插入位置的前一个结点,将这个申请结点插进去

//按位置插入 插入的第几个有效结点
bool Insert_Pos(PList plist, int pos, ElemType val)
{
assert(plist != NULL);
if(pos<1||pos>plist->size+1)
return false;
Node* newnode = BuyNode(val, NULL);
assert(newnode != NULL);
Node* p = plist->head;
for (int i = 0; i < pos - 1; i++)
{
p = p->next;
}
newnode->next = p->next;
p->next = newnode;
plist->cursize++;
return true;
}3.11 在指定结点之前插入数据元素
思想:
注意事项:
3.12 在指定结点之后插入数据元素
思想:
注意事项:
3.13 头删数据
思想:
只需要删除第一个有效结点,贯穿即可!
注意事项:
头删数据前需要进行判空,或者直接对空链表单独判断
//10.头删
bool Pop_Front(PList plist)
{
assert(plist != NULL);
if (plist->cursize == 0) //空链表需要进行单独判断,防止出现指针崩溃
return false;
//1.结点指针保存待删除结点的地址
Node* p = plist->head->next;
//2.进行贯穿
plist->head->next = p->next;
//3.释放待删结点
free(p);
plist->cursize--;
return true;
}3.14 尾删数据
思想:
注意事项:
3.15 任意位置删除数据
思想:
注意事项:
3.16 删除指定结点的前驱结点
3.17 删除指定结点的后继结点
3.18 删除与val值相等的所有数据结点
3.19 打印链表元素
思想:
打印链表元素有两种,初始位置从头结点开始或者从第一个有效结点开始,选其一。文章来源地址https://www.toymoban.com/news/detail-826357.html
//15.打印链表中的数据元素
//第一种
void PrintList(const PList plist)
{
assert(plist != NULL);
for (Node* p = plist->head; p->next != NULL; p = p->next)
{
printf("%5d", p->next->data);
}
}
//第二种
void PrintList(const PList plist)
{
assert(plist != NULL);
for (Node* p = plist->head->next; p!= NULL; p = p->next)
{
printf("%5d", p->data);
}
}3.20 .返回与val值相等的结点
3.21 返回与val值相等的前驱结点
3.22 返回与val值相等的后继结点
3.23 返回pos位置的结点
3.24 返回pos位置的前驱结点
3.25 返回pos位置的后继结点
到了这里,关于数据结构三:线性表之单链表(带头结点单向)的设计与实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[数据结构]链表之单链表(详解)](https://imgs.yssmx.com/Uploads/2024/01/400368-1.png)