1.背景介绍
人工智能(Artificial Intelligence, AI)和机器学习(Machine Learning, ML)是当今最热门的技术领域之一,它们在各个行业中发挥着越来越重要的作用。然而,在实际应用中,将人工智能和机器学习技术融入到数据产品中仍然面临着许多挑战。这篇文章将探讨如何将人工智能和机器学习技术融入到数据产品中,以及相关的核心概念、算法原理、实例代码和未来发展趋势等方面。
2.核心概念与联系
2.1 数据产品
数据产品是指通过对数据进行处理、分析和挖掘,为用户提供价值的软件产品。数据产品通常包括数据收集、数据存储、数据处理、数据分析和数据可视化等多个环节。数据产品的核心是数据,数据是企业和组织运营的基础和驱动力。数据产品化是指将数据作为企业竞争的核心资源,通过数据产品提供商业价值的过程。
2.2 人工智能与机器学习
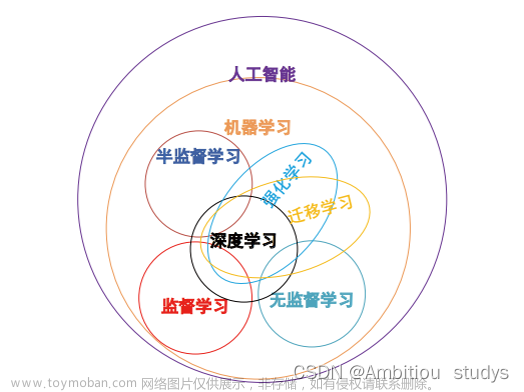
人工智能是指使用计算机程序模拟人类智能的科学和技术。人工智能包括知识工程、自然语言处理、机器学习、深度学习等多个领域。机器学习是人工智能的一个子领域,它涉及到计算机程序通过数据学习规律,自主地改善自己的行为和性能的技术。机器学习的主要方法包括监督学习、无监督学习、半监督学习、强化学习等。
2.3 数据产品化的人工智能与机器学习
数据产品化的人工智能与机器学习是将人工智能和机器学习技术融入到数据产品中,以提高数据产品的智能化程度和自主化程度的过程。这种融合可以帮助数据产品更好地理解用户需求,提高数据产品的准确性、可靠性和效率。同时,数据产品化的人工智能与机器学习也可以帮助企业和组织更好地理解市场趋势,提高竞争力。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 监督学习
监督学习是机器学习的一个主要方法,它需要预先标记的数据集来训练模型。监督学习的主要任务是根据输入变量(特征)和输出变量(标签)的关系,学习一个模型,以便在新的输入变量时预测输出变量。监督学习的常见任务包括分类、回归、推荐等。
3.1.1 逻辑回归
逻辑回归是一种用于二分类问题的监督学习算法。逻辑回归模型假设输入变量的线性组合加上一个偏差项可以预测输出变量。逻辑回归的目标是最小化损失函数,常用的损失函数有对数损失函数和平滑对数损失函数等。
$$ L(y, \hat{y}) = -\frac{1}{N}\sum{i=1}^{N}[yi\log(\hat{yi}) + (1 - yi)\log(1 - \hat{y_i})] $$
逻辑回归的具体操作步骤如下:
- 数据预处理:将原始数据转换为特征向量和标签。
- 训练模型:使用梯度下降法或其他优化算法最小化损失函数。
- 预测:使用训练好的模型预测输出变量。
3.1.2 支持向量机
支持向量机(SVM)是一种用于二分类和多分类问题的监督学习算法。支持向量机的核心思想是找到一个最大化边界分类器的超平面,使其与不同类别的样本距离最远。支持向量机通常使用核函数将原始特征空间映射到高维特征空间,以实现更好的分类效果。
支持向量机的具体操作步骤如下:
- 数据预处理:将原始数据转换为特征向量和标签。
- 训练模型:使用顺序最短路径算法或其他优化算法最大化边界分类器的边界距离。
- 预测:使用训练好的模型预测输出变量。
3.2 无监督学习
无监督学习是机器学习的另一个主要方法,它不需要预先标记的数据集来训练模型。无监督学习的主要任务是根据输入变量的关系,自动发现数据的结构和模式。无监督学习的常见任务包括聚类、降维、异常检测等。
3.2.1 聚类
聚类是一种无监督学习算法,它的目标是将数据集划分为多个群集,使得同一群集内的数据点相似度高,不同群集间的数据点相似度低。常见的聚类算法有基于距离的聚类(如K均值聚类)和基于密度的聚类(如DBSCAN)等。
K均值聚类的具体操作步骤如下:
- 数据预处理:将原始数据转换为特征向量。
- 初始化:随机选择K个数据点作为聚类中心。
- 分类:将数据点分配到与其距离最近的聚类中心。
- 更新:更新聚类中心。
- 迭代:重复步骤3和步骤4,直到聚类中心不再变化或达到最大迭代次数。
3.2.2 降维
降维是一种无监督学习算法,它的目标是将高维数据映射到低维空间,以保留数据的主要结构和模式。常见的降维算法有主成分分析(PCA)和欧几里得距离量化(ISOMAP)等。
主成分分析的具体操作步骤如下:
- 数据预处理:将原始数据转换为特征向量。
- 计算协方差矩阵:计算特征之间的相关性。
- 计算特征向量:通过特征值和特征向量求解协方差矩阵的特征分解。
- 选择主成分:选择使得数据变化最大的特征向量。
- 映射:将高维数据映射到低维空间。
4.具体代码实例和详细解释说明
在本节中,我们将通过一个简单的例子来演示如何将人工智能和机器学习技术融入到数据产品中。我们将使用Python的Scikit-learn库来实现逻辑回归和K均值聚类。
4.1 逻辑回归
4.1.1 数据准备
首先,我们需要准备一个二分类数据集。我们将使用Scikit-learn库中的make_classification数据集作为示例。
python from sklearn.datasets import make_classification X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
4.1.2 模型训练
接下来,我们使用逻辑回归算法训练模型。
python from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y)
4.1.3 预测
最后,我们使用训练好的模型进行预测。
python y_pred = model.predict(X)
4.2 K均值聚类
4.2.1 数据准备
同样,我们需要准备一个聚类数据集。我们将使用Scikit-learn库中的make_blobs数据集作为示例。
python from sklearn.datasets import make_blobs X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=42)
4.2.2 模型训练
接下来,我们使用K均值聚类算法训练模型。
python from sklearn.cluster import KMeans model = KMeans(n_clusters=4) model.fit(X)
4.2.3 预测
最后,我们使用训练好的模型进行预测。
python labels = model.predict(X)
5.未来发展趋势与挑战
随着数据产品化的人工智能与机器学习技术的不断发展,我们可以预见以下几个方面的发展趋势和挑战:
- 数据产品化的人工智能与机器学习将更加强大和智能,能够更好地理解用户需求,提供更个性化的服务。
- 数据产品化的人工智能与机器学习将面临更多的数据安全和隐私问题,需要更加严格的法规和技术措施来保护用户数据。
- 数据产品化的人工智能与机器学习将面临更多的算法解释和可解释性问题,需要更加清晰的解释和可解释性标准来评估算法效果。
- 数据产品化的人工智能与机器学习将面临更多的数据质量和数据准确性问题,需要更加严格的数据质量控制和数据验证标准来保证数据准确性。
6.附录常见问题与解答
在本节中,我们将回答一些常见问题:
Q: 数据产品化的人工智能与机器学习有哪些应用场景? A: 数据产品化的人工智能与机器学习可以应用于各个行业和领域,例如金融、医疗、零售、物流、人力资源等。
Q: 如何选择合适的人工智能与机器学习算法? A: 选择合适的人工智能与机器学习算法需要考虑多个因素,例如问题类型、数据特征、算法复杂性和效率等。通常情况下,可以尝试多种算法,并通过对比评估算法效果来选择最佳算法。
Q: 如何保护数据产品化的人工智能与机器学习模型的知识产权? A: 可以通过专利、知识产权法和商业秘密等法律手段保护数据产品化的人工智能与机器学习模型的知识产权。同时,也可以通过技术文章、专利申请和知识产权注册等手段公开和保护技术创新。文章来源:https://www.toymoban.com/news/detail-826419.html
Q: 如何评估数据产品化的人工智能与机器学习模型的效果? A: 可以通过多种评估指标来评估数据产品化的人工智能与机器学习模型的效果,例如准确率、召回率、F1分数、AUC等。同时,也可以通过对比不同算法和模型的效果来选择最佳模型。文章来源地址https://www.toymoban.com/news/detail-826419.html
到了这里,关于数据产品化的人工智能与机器学习:如何融合到数据产品中的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!