SpringBoot 整合 Spring Data Solr
测试类使用 solrClient 进行添加、查询、删除文档的操作在这篇的代码基础上继续演示的
两篇文章的区别:
上一篇是通过SolrClient 连接 Solr,然后用 SolrClient 来调用查询方法进行全文检索
这一篇是 自定义dao组件,通过继承CrudRepository 接口,用 dao 接口来调用查询方法进行全文检索
Spring Data Solr的功能(生成DAO组件):
这种方式在Spring Boot 2.5已经不再推荐使用了,需要手动添加@EnableSolrRepositories来启动DAO组件。
通过这种方式访问Solr索引库,确实不如直接用SolrClient那么灵活。
Spring Data Solr大致包括如下几方面功能:
DAO接口只需继承 CrudRepository,Spring Data Solr 就能为DAO组件提供实现类。
1、Spring Data Solr 支持方法名关键字查询,只不过Solr查询都是全文检查查询。
2、Spring Data Solr 同样支持用 @Query注解指定自定义的查询语句 。
3、Spring Data Solr 同样支持 DAO组件添加自定义的查询方法。
通过添加额外的父接口,并为额外的该接口提供实现类,Spring Data Solr 就能该实现类中的方法“移植”到DAO组件中。
4、不支持Example查询和Specification查询。
【说明:】
与前面介绍的NoSQL技术不同的是,Solr属于全文检索引擎,因此它的方法名关键字查询也是基于全文检索的。
例如对于findByName(String name)方法,假如传入参数为“疯狂”,
这意味着查询name字段中包含“疯狂”关键字的文档,而不是查询name字段值等于“疯狂”的文档。
@SolrDocument注解 可指定一个collection属性,用于指定该实体类映射哪个索引库(单机就是Core或集群模式就是Collection)。
@Query查询(属于半自动)
@Query注解所指定的就是标准的 Lucene 的查询语法
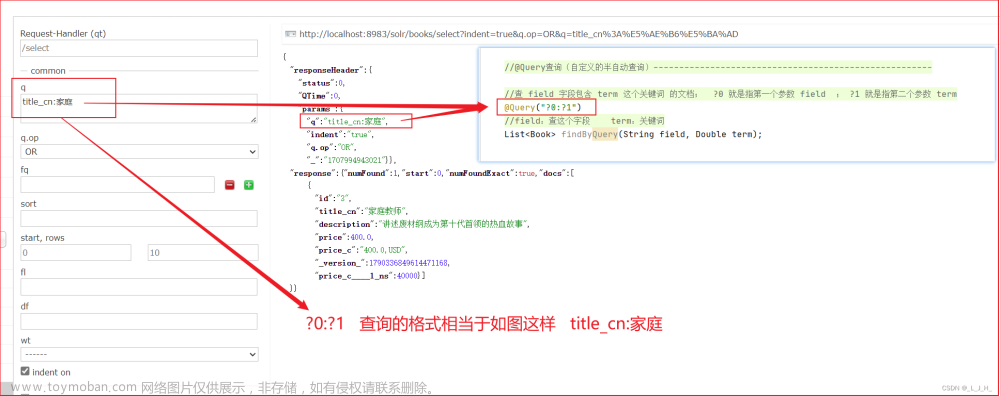
@Query("?0:?1")
List<Book> findByQuery(String field, Double term);
代码演示:
代码是基于:使用 SolrClient 连接 Solr 这篇文章来修改的
1、演示通过dao组件来保存文档
1、实体类指定索引库
指定该 Book 类映射到 books 索引库里面

2、修改日志级别
日志级别,可以用来看sql具体的执行语句
3、创建 Dao 接口
DAO接口只需继承 CrudRepository,Spring Data Solr 就能为DAO组件提供实现类。
此时写的方法还不需要用到。
只是需要用到这个BookDao接口。

4、先删除所有文档
用前面写的测试方法,先把前面测试的文档先删除干净。

5、创建测试类

区别:
添加文档的代码都是一样的,只是整合 Spring Data Solr 用到的是 bookDao 接口来实现,之前是使用solrClient来实现。

6、演示结果
成功通过 dao 组件来添加文档。

如果代码出错,因为版本问题显示没有bookDao这个bean,那么就通过注解手动启用Dao组件

我依赖是这个,演示的时候能成功执行代码,所以没有手动启用上面说的注解@EnableSolrRepositories
为了后面方便演示,把文档删了,改成这些。

2、根据 title_cn 字段是否包含关键字来查询

3、查询指定价格范围的文档

4、查询Description 字段中包含关键词的文档
查询Description 字段中包含关键词的文档(Matches 需要正则表达式)
如图:正则表达式里面 ,/故事.+/ 两个字的就查不到,如果是 /故.+/ 一个字就查的到。
/故事.+/ 两个字的就查不到
/故.+/ 一个字就查的到

5、查询集合中的这些id的文档

6、@Query查询(自定义的半自动查询)

Spring Data Solr的功能(实现自定义查询方法):
自定义查询方法(属于全手动)
让DAO接口继承自定义DAO接口、并为自定义DAO接口提供实现类,可以为DAO组件添加自定义查询方法。
Spring Data solr会将自定义DAO组件实现的方法移植DAO组件中。
自定义查询方法可使用SolrClient来实现查询方法,SolrClient 是 Solr本身提供的API,功能比较强大。
代码演示:
自定义查询方法且高亮显示
需求:自定义一个关键字查询的方法,返回的结果中,对关键字进行高亮显示。
代码解释:
下面的代码:
1、先在查询的时候添加实现高亮的代码
2、在查询后返回来的文档中,获取高亮信息
3、将获取到的高亮信息封装回 Book 对象即可。
(其实就是要返回的book对象中的description字段里面的关键字前后多了< span > 标签字符串, 就算是实现了关键字的高亮效果)
1、自定义CustomBookDao组件

同时让 bookDao 也继承这个 CustomBookDao
为了方便统一用 bookDao 来调用查询方法

2、CustomBookDaoImpl 实现类写自定义方法


3、测试:成功实现关键字的高亮显示

4、部分代码解释
1、代码中的设置对应图形界面中的设置
在查询条件中,添加高亮设置。
如图:通过图形界面跟测试代码的相同条件的查询,来演示代码设置高亮效果时对应的样子

2、对获取高亮信息并封装回book对象的解释
对这部分代码进行详细解释

查询时对关键字添加了高亮的操作,此时把具体的高亮信息(就是关键字前后添加了高亮的 < span > 代码,在查询后返回的结果文档里面,生成了如图的这个字符串)拿出来,封装回 description 这个属性里面。
比如查的时候,是查 description 这个字段里面包含“热血” 的关键词,
如果不加高亮的代码,那么返回来的数据是:
“description”:[“讲述废材纲成为第十代首领的热血故事A”]},
如果加高亮的代码,那么返回来的数据是:
“description”:[“讲述废材纲成为第十代首领的<span style=“color:red”>热血< /span >故事A”]},
关键字前后多了 <span style=“color:red”> < /span > 这两个字符串。
所以我们这一步就是要把加高亮后返回的这个多了这两个高亮显示的字符串的数据,给封装到 Book 对象里面的description 字段里面。
如图:通过图形界面跟测试代码的相同条件的查询,来演示代码具体获取到的高亮信息长啥样

如果不封装的话,那么查询后返回来的结果,这个description字段的数据依然是没有加高亮代码的。

所以需要把高亮的信息获取出来,再设置到 Book 对象里面的 description 字段里面,这样再返回这个 book对象,此时Book对象里面的 description 值就有高亮显示的功能了。
(其实就是要返回的book对象中的description字段里面的关键字前后多了< span > 标签字符串, 就算是实现了关键字的高亮效果)

代码优化:
如图:根据上面的代码解释,可以看出此时的 highLightDesc 字符串相当于就是具有高亮效果的 description 的值。
description 的值长这样:
[“讲述废材纲成为第十代首领的热血故事A”]},
highLightDesc 的值长这样
[“讲述废材纲成为第十代首领的<span style=“color:red”>热血< /span >故事A”]},
我们需要把
[“讲述废材纲成为第十代首领的<span style=“color:red”>热血< /span >故事A”]},
这个具有高亮效果的值封装回 Book 对象里面。
但是这个highLightDesc 这个字符串毕竟不是 description ,
所以如图直接把 highLightDesc 作为 description 字段封装进去,其实是不太合逻辑的。
所以可以优化下

优化代码:
假如我不希望改变Book对象的属性值,但是又希望能将高亮的信息传出去,因此可以考虑为Book对象增加一个Map类型的属性,该属性用于保存高亮信息。
1、先添加一个用于保存高亮信息的字段

2、封装对象时,把 highLightDesc 改回正常的 description 字段,此时可以看到,关键字并没有高亮显示。

3、把该id的文档的高亮信息设置到这个字段里面
如图:这样也能实现高亮效果
这种写法的好处:
既不会破坏原来这个 Book 对象的属性值,同时也能将高亮信息传出来

@EnableSolrRepositories 注解解释
该注解其实和Spring Boot的其他 @EnableXxxRepositories注解大同小异。
@EnableSolrRepositories注解用于启用Solr Repository支持。
一旦程序显式使用该注解,那Spring Data Solr 的 Repository自动配置就会失效(Spring Boot 2.5本来就没有启用Repository的自动配置)。
因此,当需要连接多个Solr索引库时或进行更多定制时,可手动使用该注解。
使用@EnableSolrRepositories注解时要指定如下属性:
- basePackages:指定扫描哪个包下的DAO组件(Repository组件)。
- solrClientRef:指定基于哪个 SolrClient 来实现 Repository 组件,默认值是 solrClient。
- solrTemplateRef:指定基于哪个 SolrTemplate 来实现Repository组件,默认是 solrTemplate。
上面 solrClientRef 与 solrTemplateRef 两个属性只要指定其中之一即可。
如图:不过这个注解我暂时没用到。文章来源:https://www.toymoban.com/news/detail-826454.html
 文章来源地址https://www.toymoban.com/news/detail-826454.html
文章来源地址https://www.toymoban.com/news/detail-826454.html
完整代码
SolrConfig 手动配置自定义的SolrClient
package cn.ljh.solrboot.config;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.impl.CloudSolrClient;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.solr.SolrProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.solr.repository.config.EnableSolrRepositories;
import org.springframework.util.StringUtils;
import java.util.Arrays;
import java.util.Optional;
//手动配置自定义的SolrClient
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({HttpSolrClient.class, CloudSolrClient.class})
@EnableConfigurationProperties(SolrProperties.class)
//由于本项目没有配置 SpringBoot 为 Spring Data Solr 提供的 Starter 组件,因此需要手动启用Dao组件
//@EnableSolrRepositories(basePackages = "cn.ljh.solrboot.dao",solrClientRef = "solrClient")
public class SolrConfig
{
//把配置文件中的属性值注入到这个成员变量里面
@Value("${spring.data.solr.username}")
private String username;
@Value("${spring.data.solr.password}")
private String password;
//此处需要配置一个 SolrClient(直接抄SolrAutoConfiguration的源码就可以了)
@Bean
public SolrClient solrClient(SolrProperties properties)
{
//通过系统属性来设置连接Solr所使用的认证信息
// 设置使用基本认证的客户端
System.setProperty("solr.httpclient.builder.factory",
"org.apache.solr.client.solrj.impl.PreemptiveBasicAuthClientBuilderFactory");
// 设置认证的用户名和密码
System.setProperty("basicauth", username + ":" + password);
if (StringUtils.hasText(properties.getZkHost()))
{
return new CloudSolrClient.Builder(Arrays.asList(properties.getZkHost()), Optional.empty()).build();
}
return new HttpSolrClient.Builder(properties.getHost()).build();
}
}
Book 实体类
package cn.ljh.solrboot.domain;
import lombok.Data;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.solr.core.mapping.SolrDocument;
import java.util.List;
import java.util.Map;
/**
* author JH
*/
@Data
//指定该 Book 类映射到 books 索引库里面
@SolrDocument(collection = "books")
public class Book
{
//该id字段会被映射到索引库的 id field,而在索引库中 ,id field 被自定为标志属性
//@Id
//添加这个 @Field 注解,就能自动映射到索引库中同名的field
@Field
private Integer id;
//这就表示这个 title ,映射到索引库中的 title_cn 这个字段
@Field("title_cn")
private String title;
@Field
private String description;
@Field
private Double price;
//用于保存高亮信息
private Map<String, List<String>> highLight;
//构造器
public Book(Integer id, String title, String description, Double price)
{
this.id = id;
this.title = title;
this.description = description;
this.price = price;
}
}
BookDao 组件
package cn.ljh.solrboot.dao;
import cn.ljh.solrboot.domain.Book;
import org.springframework.data.repository.CrudRepository;
import org.springframework.data.solr.repository.Query;
import java.util.List;
// DAO接口只需继承 CrudRepository,Spring Data Solr 就能为DAO组件提供实现类
//参数1:指定要进行数据访问的实体类是 Book, 也就是指定要操作的实体是 Book 参数2:Book 实体的主键的类型将被映射为整数类型
public interface BookDao extends CrudRepository<Book,Integer>,CustomBookDao
{
//这些基于方法名关键字查询,都是全文检索的查询---------------------------------------------
//根据 title_cn 字段是否包含关键字来查询
List<Book> findByTitle(String term);
//查询指定价格范围的文档
List<Book> findByPriceBetween(Double start , Double end);
//查询Description 字段中包含关键词的文档(Matches 需要正则表达式)
List<Book> findByDescriptionMatches(String descPattern);
//查询集合中的这些id的文档
List<Book> findByIdIn(List<Integer> ids);
//@Query查询(自定义的半自动查询)------------------------------------------------------
//查 field 字段包含 term 这个关键词 的文档; ?0 就是指第一个参数 field ; ?1 就是指第二个参数 term
@Query("?0:?1")
//field:查这个字段 term:关键词
List<Book> findByQuery(String field, String term);
}
CustomBookDao 自定义dao组件
package cn.ljh.solrboot.dao;
import cn.ljh.solrboot.domain.Book;
import java.util.List;
/**
* author JH 2024-02
*/
public interface CustomBookDao
{
//通过关键字查询并高亮显示
List<Book> highLightFindByDescription(String term);
}
CustomBookDaoImpl 自定义查询方法
package cn.ljh.solrboot.dao.impl;
import cn.ljh.solrboot.dao.CustomBookDao;
import cn.ljh.solrboot.domain.Book;
import lombok.SneakyThrows;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* author JH 2024-02
*/
public class CustomBookDaoImpl implements CustomBookDao
{
// 借助于 SolrClient ,可以实现 solr 的所有功能,比如: 高亮功能
private final SolrClient solrClient;
//通过构造器进行依赖注入
public CustomBookDaoImpl(SolrClient solrClient)
{
this.solrClient = solrClient;
}
//通过关键字查询并高亮显示
@SneakyThrows
@Override
public List<Book> highLightFindByDescription(String term)
{
//定义查询
SolrQuery solrQuery = new SolrQuery("description:" + term);
//开启高亮显示功能(对应图形界面中的 hl 复选框)
solrQuery.setHighlight(true);
//所谓高亮,就是在关键词前面和后面设置要添加的字符串片段
//(对应图形界面中的 hl.simple.pre)
solrQuery.setHighlightSimplePre("<span style=\"color:red\">");
//(对应图形界面中的 hl.simple.post)
solrQuery.setHighlightSimplePost("</span>");
//设置对哪个字段进行高亮显示(对应图形界面中的 hl.fl)
solrQuery.addHighlightField("description");
//执行查询 参数1:到“books”索引库查询 , 参数2:查询的条件
QueryResponse response = solrClient.query("books", solrQuery);
//获取查询后返回的文档列表
SolrDocumentList docLists = response.getResults();
//获取高亮信息
//该Map的key就是文档的id
Map<String, Map<String, List<String>>> high = response.getHighlighting();
//创建一个集合,用来存放封装了高亮信息的Book对象
List<Book> bookList = new ArrayList<>();
for (SolrDocument doc : docLists)
{
//此处就要将 SolrDocument 文档中的信息提取出来,封装到 Book 对象中
String id = (String) doc.getFieldValue("id");
String title = (String) doc.getFieldValue("title_cn");
String description = (String) doc.getFieldValue("description");
double price = (Float) doc.getFieldValue("price");
//获取高亮后的字段值
//通过文档的id,获取该文档的高亮信息
Map<String, List<String>> highLightDoc = high.get(id);
//再通过description这个key获取对应的value值(List类型)
List<String> stringList = highLightDoc.get("description");
//因为该list集合中只有一个元素,所以只获取第一个元素即可
String highLightDesc = stringList.get(0);
//将从 SolrDocument 文档中取出的高亮信息再封装回Book对象就可以了
//这里是把 highLightDesc 作为 description 这个属性的值封装进去,其实不太好。
//Book book = new Book(Integer.parseInt(id),title,highLightDesc,price);
//假如我不希望改变Book对象的属性值,但是又希望能将高亮的信息传出去,因此可以考虑为Book对象增加一个Map类型的属性,该属性用于保存高亮信息
Book book = new Book(Integer.parseInt(id),title,description,price);
//把该id的文档的高亮信息设置到这个字段里面
book.setHighLight(highLightDoc);
bookList.add(book);
}
return bookList;
}
}
application.properties 配置文件
# 现在演示的是单机模式,所以先指定这个host
spring.data.solr.host=http://127.0.0.1:8983/solr
# 连接 Solr 索引库的用户名和密码(就是Solr的图形界面)
spring.data.solr.username=root
spring.data.solr.password=123456
# 日志级别,可以用来看sql具体的执行语句
logging.level.org.springframework.data.solr=debug
BookDaoTest 基于DAO组件测试
package cn.ljh.solrboot;
import cn.ljh.solrboot.dao.BookDao;
import cn.ljh.solrboot.domain.Book;
import lombok.SneakyThrows;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.solr.repository.Query;
import java.util.List;
/**
* author JH 2024-02
*/
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class BookDaoTest
{
//依赖注入
@Autowired
private BookDao bookDao;
//添加文档到books索引库的测试类
@ParameterizedTest
//这些参数相当于一个个文档
@CsvSource({
"1,火影忍者,讲述鸣人成为村长的事情,200",
"2,七龙珠,讲述赛亚人的成长故事,300",
"3,家庭教师A,讲述废材纲成为第十代首领的热血故事A,400",
"4,家庭教师B,讲述废材纲成为第十代首领的热血故事B,500"
})
public void testSave(Integer id, String title, String description, Double price)
{
Book book = new Book(id, title, description, price);
//使用bookDao来保存数据对象时,无需如之前一样指定索引库的名称,
//因为Book类上面有@SolrDocument(collection = "books")修饰,已经指定了该数据类所映射的索引库
bookDao.save(book);
}
//根据 title_cn 字段是否包含关键字来查询
@ParameterizedTest
//测试时只需要一个参数用这个注解
@ValueSource(strings = {
"龙珠",
"家庭"
})
public void testFindByTitle(String term){
//查询
List<Book> books = bookDao.findByTitle(term);
//打印
books.forEach(System.err::println);
}
//查询指定价格范围的文档
@ParameterizedTest
//测试时需要多个参数用这个注解,多个参数在一个双引号里面用逗号隔开
@CsvSource({
"100,200",
"200,300"
})
public void testFindByPriceBetween(Double start , Double end){
List<Book> books = bookDao.findByPriceBetween(start, end);
books.forEach(System.err::println);
}
//查询Description 字段中包含关键词的文档(Matches 需要正则表达式)
@ParameterizedTest
//正则表达式必须放在两个斜杠//里面, . 这个点表示匹配任意字符 , + 号表示出现 1 到多次
@ValueSource(strings = {
"/故.+/",
"/热.+/"
})
public void testFindByDescriptionMatches(String descPattern){
List<Book> books = bookDao.findByDescriptionMatches(descPattern);
books.forEach(System.err::println);
}
//查询集合中的这些id的文档
@ParameterizedTest
@CsvSource({
"1,2",
"1,3"
})
public void testFindByIdIn(Integer id1 , Integer id2){
List<Integer> ids = List.of(id1, id2);
List<Book> books = bookDao.findByIdIn(ids);
books.forEach(System.err::println);
}
//@Query查询(自定义的半自动查询)------------------------------------------------------
@ParameterizedTest
@CsvSource({
"title_cn,家庭",
"description,故事*"
})
public void testFindByQuery(String field, String term){
List<Book> books = bookDao.findByQuery(field, term);
books.forEach(System.err::println);
}
//自定义查询方法且高亮显示
@ParameterizedTest
@ValueSource(strings = {
"热*",
"村*"
})
public void testHighLightFindByDescription(String term){
List<Book> books = bookDao.highLightFindByDescription(term);
books.forEach(System.err::println);
}
}
SolrClientTest 基于SolrClient测试
package cn.ljh.solrboot;
import cn.ljh.solrboot.domain.Book;
import lombok.SneakyThrows;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.params.SolrParams;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
// SpringBootTest.WebEnvironment.NONE: 指定测试的web环境为非Web环境。
// 通常情况下,我们会将该参数设置为NONE,表示不需要启动内嵌的Web容器,从而更加快速地执行测试
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class SolrClientTest
{
@Autowired
private SolrClient solrClient;
//添加文档到books索引库的测试类
@SneakyThrows
@ParameterizedTest
//这些参数相当于一个个文档
@CsvSource({
"1,火影忍者,讲述成为村长的故事,200",
"2,七龙珠,讲述赛亚人的成长故事,300",
"3,家庭教师,讲述废材纲成为第十代首领的热血故事,400"
})
public void testSave(Integer id, String title, String description, Double price)
{
Book book = new Book(id, title, description, price);
//向 books 逻辑索引库添加文档 ; 参数1:索引库的名字 , 参数2:映射文档的实体对象 ,参数3 :500 毫秒的提交时间
solrClient.addBean("books", book, 500);
}
//查询索引库中的文档的测试类
@SneakyThrows
@ParameterizedTest
//这个注解用来进行多次测试,一个字符串代表一次测试方法。
@CsvSource({
"title_cn,忍者",
"description,成为",
"description,成*"
})
//参数1:要查询的字段 参数2:要查询的关键词
public void testQuery(String field, String term)
{
//创建查询,表明在 field 字段中查询 term 关键字
SolrParams params = new SolrQuery(field + ":" + term);
//执行查询操作,去 books 这个索引库里面查询,得到响应
QueryResponse queryResponse = solrClient.query("books", params);
//返回所得到的文档
SolrDocumentList docList = queryResponse.getResults();
//遍历所有的文档
for (SolrDocument doc : docList)
{
System.err.println("获取所有 field 的名字:" + doc.getFieldNames());
//遍历文档中的每个字段名
for (String fn : doc.getFieldNames())
{
//通过字段名获取字段值
System.err.println("filed名称:【 " + fn + " 】,field 的值:【" + doc.getFieldValue(fn) + " 】");
}
}
}
//根据文档的id来删除文档
@SneakyThrows
@ParameterizedTest
@ValueSource(strings = {"1"})
public void testDeleteById(String id)
{
//根据文档的id来删除
//参数1:指定删除哪个索引库的文档 参数2:删除这个id的文档 参数3:指定多久提交执行这个删除操作,这里是500毫秒
solrClient.deleteById("books",id,500);
}
//根据提供的字段和关键词,通过查询,如果该字段包含该关键词,则该文档会被删除掉
@SneakyThrows
@ParameterizedTest
@CsvSource({
//"title_cn,龙珠"
//匹配所有的文档,也就是删除所有文档
"*,*"
})
//这个字段包含这个关键词的则会被删除掉
public void testDeleteByQuery(String field, String term)
{
//因为 参数2 需要的类型是String,所以这里不用创建SolrQuery查询对象
//str 打印出来 ===> q=title_cn:龙珠
String str = field + ":" + term;
//参数1:指定删除哪个索引库的文档 参数2:字段名+关键词 参数3:指定多久提交执行这个删除操作,这里是500毫秒
solrClient.deleteByQuery("books",str,500);
}
}
pom.xml 依赖文档
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
</parent>
<groupId>cn.ljh</groupId>
<artifactId>solrboot</artifactId>
<version>1.0.0</version>
<name>solrboot</name>
<properties>
<java.version>11</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 最基础的Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- SpringBoot 2.5.3 不再为 Spring Data Solr 提供 Starter,因此只能手动添加 Spring Data Solr 依赖 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
<version>4.3.11</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.9</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
到了这里,关于09、全文检索 -- Solr -- SpringBoot 整合 Spring Data Solr (生成DAO组件 和 实现自定义查询方法)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!