已经进入大模微调的时代,但是学习pytorch,对后续学习rasa框架有一定帮助吧。文章来源:https://www.toymoban.com/news/detail-826715.html
<!-- 给出一系列的点作为线性回归的数据,使用numpy来存储这些点。 -->
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
<!-- 转化tensor格式。 -->
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
<!-- 这里的nn.Linear表示的是 y=w*x b,里面的两个参数都是1,表示的是x是1维,y也是1维。当然这里是可以根据你想要的输入输出维度来更改的。 -->
class linearRegression(nn.Module):
def __init__(self):
super(linearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # input and output is 1 dimension
def forward(self, x):
out = self.linear(x)
return out
model = linearRegression()
<!-- 定义loss和优化函数,这里使用的是最小二乘loss,之后我们做分类问题更多的使用的是cross entropy loss,交叉熵。优化函数使用的是随机梯度下降,注意需要将model的参数model.parameters()传进去让这个函数知道他要优化的参数是那些。 -->
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
<!-- 开始训练 -->
num_epochs = 1000
for epoch in range(num_epochs):
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs) # 前向传播
loss = criterion(out, target) # 计算loss
# backward
optimizer.zero_grad() # 梯度归零
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch 1) % 20 == 0:
print(f'Epoch[{epoch+1}/{num_epochs}], loss: {loss.item():.6f}')
<!--训练完成之后我们就可以开始测试模型了-->
model.eval()
predict = model(Variable(x_train))
predict = predict.data.numpy()
<!-- 显示图例 -->
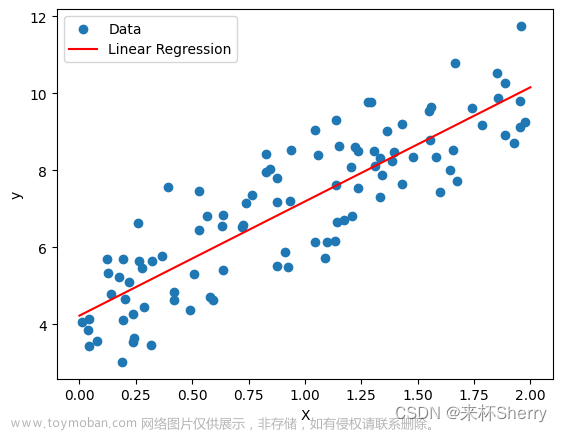
fig = plt.figure(figsize=(10, 5))
plt.plot(x_train.numpy(), y_train.numpy(), 'ro', label='Original data')
plt.plot(x_train.numpy(), predict, label='Fitting Line')
plt.legend()
plt.show()
<!-- 保存模型 -->
torch.save(model.state_dict(), './linear.pth')
 文章来源地址https://www.toymoban.com/news/detail-826715.html
文章来源地址https://www.toymoban.com/news/detail-826715.html
到了这里,关于PyTorch-线性回归的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!