1.下载 安装包
Apache HBase – Apache HBase Downloads
选择版本
https://dlcdn.apache.org/hbase/2.4.17/hbase-2.4.17-bin.tar.gz
2.集群环境准备
2.1 概念说明
Hbase是一个分布式系统
其中有一个管理角色:HMaster(一般2台 ,一台active、一台backup)
其它的数据节点角色:HRegionServer(很多台,看数据容量)
客户端要查数据,
2.2 上传安装包&解压
[root@node1 ~]# tar -zxvf hbase-2.4.17-bin.tar.gz -C /app/

2.3 修改conf 配置文件
2.3.1 修改hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_251
#用我们自己的zk集群
export HBASE_MANAGES_ZK=false
2.3.2 修改hbase-site.xml
<!--指定hbase在HDFS上的存储路径-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<!--指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--使用本地文件系统设置为false,使用hdfs设置为true-->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>true</value>
</property>
</configuration>参数注解说明
hbase.tmp.dir:本地文件系统的临时目录,默认是${java.io.tmpdir}/hbase-${user.name};
hbase.rootdir:hbase持久化的目录,被所有regionserver共享,默认${hbase.tmp.dir}/hbase,一般设置为hdfs://namenode.example.org:9000/hbase类似,带全限定名;
hbase.cluster.distributed:hbase集群模式运作与否的标志,默认是false,开启需要设置为true,false时启动hbase会在一个jvm中运行hbase和zk;
hbase.zookeeper.quorum:重要的也是必须设置的,启动zk的服务器列表,逗号分隔,cluster模式下必须设置,默认是localhost,hbase客户端也需要设置这个值去访问zk;
hbase.zookeeper.property.dataDir:ZooKeeper的zoo.conf中的配置。快照的存储位置,默认是:${hbase.tmp.dir}/zookeeper;
hbase.unsafe.stream.capability.enforce:控制HBase是否检查流功能(hflush / hsync),如果您打算在rootdir表示的LocalFileSystem上运行,那就禁用此选项
hbase.local.dir:本地文件系统被用在本地存储的目录,默认${hbase.tmp.dir}/local/;
hbase.master.port:hbase master绑定的端口,默认是60000;
hbase.master.info.port:hbase master web 界面的端口,默认是60010,设置为-1可以禁用ui;
hbase.master.info.bindAddress:master web界面的绑定地址,默认是0.0.0.0;2.3.3 配置regionservers 启动机器
需要在哪些机器启动regionservers 把机器添加到regionservers文件中
[root@node1 conf]# more regionservers
node1
node2
node3
2.4 拷贝修改后的安装包到node2、node3 机器
[root@node1 app]# scp -r hbase-2.4.17/ node2:$PWD
[root@node1 app]# scp -r hbase-2.4.17/ node3:$PWD
3. 启动Hbase集群
启动前要检查hdfs 、和zk 集群是否正常
[root@node1 app]# hdfs dfsadmin -report #hdfs的报告状态
#启动hbase
[root@node1 app]# ./hbase-2.4.17/bin/start-hbase.sh

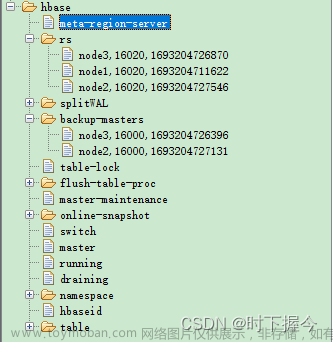
hbase region角色之间的信息通信是通过zk完成的
可以去zk 查看节点信息
[root@node1 app]# ./zookeeper-3.7.1/bin/zkCli.sh

停机出现卡住
[root@node1 app]# ./hbase-2.4.17/bin/stop-hbase.sh stopping hbase.....................................................................................................................
解决方法1:先输入
hbase-daemon.sh stop master
hbase-daemons.sh stop regionserver命令
再输入stop-hbase.sh命令。
这样hbase就可以成功关闭。
4.web 控制台

16010 端口是对外访问的
http://192.168.6.130:16010/文章来源:https://www.toymoban.com/news/detail-827090.html
 文章来源地址https://www.toymoban.com/news/detail-827090.html
文章来源地址https://www.toymoban.com/news/detail-827090.html
到了这里,关于Hbase 集群搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!