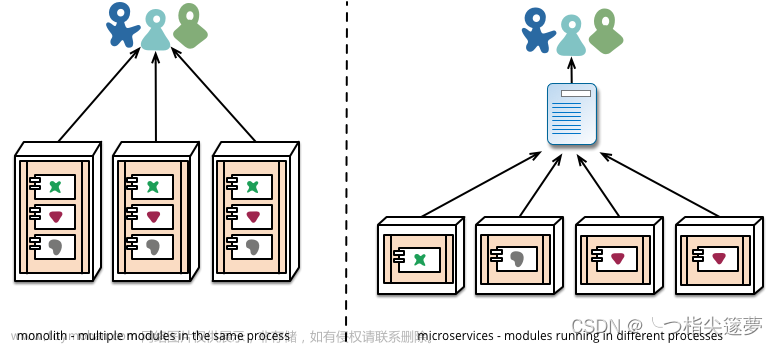
众所周知,微服务架构解决了很多问题,通过分解复杂的单体式应用,在功能不变的情况下,使应用被分解为多个可管理的服务,为采用单体式编码方式很难实现的功能提供了模块化的解决方案。同时,每个微服务独立部署、独立扩展,使得持续化集成成为可能。由此,单个服务很容易开发、理解和维护。
微服务架构为开发带来了诸多好处的同时,也引发了很多问题。比如服务运维变得更复杂,服务之间的依赖关系更复杂,数据一致性难以保证。
本篇文章将讨论和介绍Choerodon猪齿鱼是如何保障微服务架构的数据一致性的。
主要内容包括 :
- 传统应用使用本地事务保持一致性
- 多数据源下的分布式事务
- 微服务架构中应满足数据最终一致性原则
- 使用Event Sourcing保证微服务的最终一致性
- 使用可靠事件模式保证微服务的最终一致性
- 使用Saga保证微服务的最终一致性
下面将通过一个实例来分别介绍这几种模式。
在Choerodon 猪齿鱼的 DevOps流程中,有这样一个步骤。
- 用户在Choerodon 平台上创建一个项目;
- DevOps 服务对应创建一个项目;
- DevOps 为该项目 在 Gitlab 上创建对应的group。
传统应用使用本地事务保持一致性
在讲微服务架构的数据一致性之前,先介绍一下传统关系型数据库是如何保证一致性的,从关系型数据库中的ACID理论讲起。
ACID 即数据库事务正确执行的四个基本要素。分别是:
- 原子性(Atomicity):要么全部完成,要么全部不完成,不存在中间状态
- 一致性(Consistency):事务必须始终保持系统处于一致的状态
- 隔离性(Isolation):事务之间相互隔离,同一时间仅有一个请求用于同一数据
- 持久性(Durability):事务一旦提交,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
可以通过使用数据库自身的ACID Transactions,将上述步骤简化为如下伪代码:
transaction.strat();
createProject();
devopsCreateProject();
gitlabCreateGroup();
transaction.commit();
这个过程可以说是十分简单,如果在这一过程中发生失败,例如DevOps创建项目失败,那么该事务做回滚操作,使得最终平台创建项目失败。由于传统应用一般都会使用一个关系型数据库,所以可以直接使用 ACID transactions。 保证了数据本身不会出现不一致。为保证一致性只需要:开始一个事务,改变(插入,删除,更新)很多行,然后提交事务(如果有异常时回滚事务)。
随着业务量的不断增长,单数据库已经不足以支撑庞大的业务数据,此时就需要对应用和数据库进行拆分,于此同时,也就出现了一个应用需要同时访问两个或者两个以上的数据库或多个应用分别访问不同的数据库的情况,数据库的本地事务则不再适用。
为了解决这一问题,分布式事务应运而生。
多数据源下的分布式事务
想象一下,如果很多用户同时对Choerodon 平台进行创建项目的操作,应用接收的流量和业务数据剧增。一个数据库并不足以存储所有的业务数据,那么我们可以将应用拆分成IAM服务和DevOps服务。其中两个服务分别使用各自的数据库,这样的情况下,我们就减轻了请求的压力和数据库访问的压力,两个分别可以很明确的知道自己执行的事务是成功还是失败。但是同时在这种情况下,每个服务都不知道另一个服务的状态。因此,在上面的例子中,如果当DevOps创建项目失败时,就无法直接使用数据库的事务。
那么如果当一个事务要跨越多个分布式服务的时候,我们应该如何保证事务呢?
为了保证该事务可以满足ACID,一般采用2PC或者3PC。 2PC(Two Phase Commitment Protocol),实现分布式事务的经典代表就是两阶段提交协议。2PC包括准备阶段和提交阶段。在此协议中,一个或多个资源管理器的活动均由一个称为事务协调器的单独软件组件来控制。
我们为DevOps服务分配一个事务管理器。那么上面的过程可以整理为如下两个阶段:
准备阶段:
提交/回滚阶段:
2PC 提供了一套完整的分布式事务的解决方案,遵循事务严格的 ACID 特性。
但是,当在准备阶段的时候,对应的业务数据会被锁定,直到整个过程结束才会释放锁。如果在高并发和涉及业务模块较多的情况下,会对数据库的性能影响较大。而且随着规模的增大,系统的可伸缩性越差。同时由于 2PC引入了事务管理器,如果事务管理器和执行的服务同时宕机,则会导致数据产生不一致。虽然又提出了3PC 将2PC中的准备阶段再次一分为二的来解决这一问题,但是同样可能会产生数据不一致的结果。
微服务架构中应满足数据最终一致性原则
不可否认,2PC 和3PC 提供了解决分布式系统下事务一致性问题的思路,但是2PC同时又是一个非常耗时的复杂过程,会严重影响系统效率,在实践中我们尽量避免使用它。所以在分布式系统下无法直接使用此方案来保证事务。
对于分布式的微服务架构而言,传统数据库的ACID原则可能并不适用。首先微服务架构自身的所有数据都是通 过API 进行访问。这种数据访问方式使得微服务之间松耦合,并且彼此之间独立非常容易进行性能扩展。其次 不同服务通常使用不同的数据库,甚至并不一定会使用同一类数据库,反而使用非关系型数据库,而大部分的 非关系型数据库都不支持2PC。
在这种情况下,又如何解决事务一致性问题呢?
一个最直接的办法就是考虑数据的强一致性。根据Eric Brewer提出的CAP理论,只能在数据强一致性(C)和可用性(A)之间做平衡。
CAP 是指在一个分布式系统下,包含三个要素:Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),并且三者不可得兼。
- 一致性(Consistency),是指对于每一次读操作,要么都能够读到最新写入的数据,要么错误,所有数据变动都是同步的。
- 可用性(Availability),是指对于每一次请求,都能够得到一个及时的、非错的响应,但是不保证请求的结果是基于最新写入的数据。即在可以接受的时间范围内正确地响应用户请求。
- 分区容错性(Partition tolerance),是指由于节点之间的网络问题,即使一些消息丢包或者延迟,整个系统仍能够提供满足一致性和可用性的服务。
关系型数据库单节点保证了数据强一致性(C)和可用性(A),但是却无法保证分区容错性(P)。
然而在分布式系统下,为了保证模块的分区容错性(P),只能在数据强一致性(C)和可用性(A)之间做平衡。具体表现为在一定时间内,可能模块之间数据是不一致的,但是通过自动或手动补偿后能够达到最终的一致。
可用性一般是更好的选择,但是在服务和数据库之间维护事务一致性是非常根本的需求,微服务架构中应该选择满足最终一致性。
那么我们应该如何实现数据的最终一致性呢?
使用Event Sourcing保证微服务的最终一致性
什么是Event Sourcing(事件溯源)?
一个对象从创建开始到消亡会经历很多事件,传统的方式是保存这个业务对象当前的状态。但更多的时候,我们也许更关心这个业务对象是怎样达到这一状态的。Event Sourcing从根本上和传统的数据存储不同,它存储的不是业务对象的状态,而是有关该业务对象一系列的状态变化的事件。只要一个对象的状态发生变化,服务就需要自动发布事件来附加到事件的序列中。这个操作本质上是原子的。
现在将上面的订单过程用Event Sourcing 进行改造,将订单变动的一个个事件存储起来,服务监听事件,对订单的状态进行修改。
可以看到 Event Sourcing 完整的描述了对象的整个生命周期过程中所经历的所有事件。由于事件是只会增加不会修改,这种特性使得领域模型十分的稳定。
Event sourcing 为整体架构提供了一些可能性,但是将应用程序的每个变动都封装到事件保存下来,并不是每个人都能接受的风格,而且大多数人都认为这样很别扭。同时这一架构在实际应用实践中也不是特别的成熟。
使用可靠事件模式保证微服务的最终一致性
可靠事件模式属于事件驱动架构,微服务完成操作后向消息代理发布事件,关联的微服务从消息代理订阅到该 事件从而完成相应的业务操作,关键在于可靠事件投递和避免事件重复消费。
可靠事件投递有两个特性:
- 每个服务原子性的完成业务操作和发布事件;
- 消息代理确保事件投递至少一次 (at least once)。避免重复消费要求消费事件的服务实现幂等性。
有两种实现方式:
1. 本地事件表
本地事件表方法将事件和业务数据保存在同一个数据库中,使用一个额外的“事件恢复”服务来恢 复事件,由本地事务保证更新业务和发布事件的原子性。考虑到事件恢复可能会有一定的延时,服务在完成本 地事务后可立即向消息代理发布一个事件。
使用本地事件表将事件和业务数据保存在同一个数据库中,会在每个服务存储一份数据,在一定程度上会造成代码的重复冗余。同时,这种模式下的业务系统和事件系统耦合比较紧密,额外增加的事件数据库操作也会给数据库带来额外的压力,可能成为瓶颈。
2. 外部事件表
针对本地事件表出现的问题,提出外部事件表方法,将事件持久化到外部的事件系统,事件系统 需提供实时事件服务以接收微服务发布的事件,同时事件系统还需要提供事件恢复服务来确认和恢复事件。
借助Kafka和可靠事件,可以通过如下代码实现订单流程。
// IAM ProjectService
@Service
@RefreshScope
public class ProjectServiceImpl implements ProjectService {
private ProjectRepository projectRepository;
private UserRepository userRepository;
private OrganizationRepository organizationRepository;
@Value("${choerodon.devops.message:false}")
private boolean devopsMessage;
@Value("${spring.application.name:default}")
private String serviceName;
private EventProducerTemplate eventProducerTemplate;
public ProjectServiceImpl(ProjectRepository projectRepository,
UserRepository userRepository,
OrganizationRepository organizationRepository,
EventProducerTemplate eventProducerTemplate) {
this.projectRepository = projectRepository;
this.userRepository = userRepository;
this.organizationRepository = organizationRepository;
this.eventProducerTemplate = eventProducerTemplate;
}
@Transactional(rollbackFor = CommonException.class)
@Override
public ProjectDTO update(ProjectDTO projectDTO) {
ProjectDO project = ConvertHelper.convert(projectDTO, ProjectDO.class);
if (devopsMessage) {
ProjectDTO dto = new ProjectDTO();
CustomUserDetails details = DetailsHelper.getUserDetails();
UserE user = userRepository.selectByLoginName(details.getUsername());
ProjectDO projectDO = projectRepository.selectByPrimaryKey(projectDTO.getId());
OrganizationDO organizationDO = organizationRepository.selectByPrimaryKey(projectDO.getOrganizationId());
ProjectEventPayload projectEventMsg = new ProjectEventPayload();
projectEventMsg.setUserName(details.getUsername());
projectEventMsg.setUserId(user.getId());
if (organizationDO != null) {
projectEventMsg.setOrganizationCode(organizationDO.getCode());
projectEventMsg.setOrganizationName(organizationDO.getName());
}
projectEventMsg.setProjectId(projectDO.getId());
projectEventMsg.setProjectCode(projectDO.getCode());
Exception exception = eventProducerTemplate.execute("project", EVENT_TYPE_UPDATE_PROJECT,
serviceName, projectEventMsg, (String uuid) -> {
ProjectE projectE = projectRepository.updateSelective(project);
projectEventMsg.setProjectName(project.getName());
BeanUtils.copyProperties(projectE, dto);
});
if (exception != null) {
throw new CommonException(exception.getMessage());
}
return dto;
} else {
return ConvertHelper.convert(
projectRepository.updateSelective(project), ProjectDTO.class);
}
}
}
// DEVOPS DevopsEventHandler
@Component
public class DevopsEventHandler {
private static final String DEVOPS_SERVICE = "devops-service";
private static final String IAM_SERVICE = "iam-service";
private static final Logger LOGGER = LoggerFactory.getLogger(DevopsEventHandler.class);
@Autowired
private ProjectService projectService;
@Autowired
private GitlabGroupService gitlabGroupService;
private void loggerInfo(Object o) {
LOGGER.info("data: {}", o);
}
/**
* 创建项目事件
*/
@EventListener(topic = IAM_SERVICE, businessType = "createProject")
public void handleProjectCreateEvent(EventPayload<ProjectEvent> payload) {
ProjectEvent projectEvent = payload.getData();
loggerInfo(projectEvent);
projectService.createProject(projectEvent);
}
/**
* 创建组事件
*/
@EventListener(topic = DEVOPS_SERVICE, businessType = "GitlabGroup")
public void handleGitlabGroupEvent(EventPayload<GitlabGroupPayload> payload) {
GitlabGroupPayload gitlabGroupPayload = payload.getData();
loggerInfo(gitlabGroupPayload);
gitlabGroupService.createGroup(gitlabGroupPayload);
}
}
使用Saga保证微服务的最终一致性 – Choerodon的解决方案
Saga是来自于1987年Hector GM和Kenneth Salem论文。在他们的论文中提到,一个长活事务Long lived transactions (LLTs) 会相对较长的占用数据库资源。如果将它分解成多个事务,只要保证这些事务都执行成功, 或者通过补偿的机制,来保证事务的正常执行。这一个个的事务被他们称之为Saga。
Saga将一个跨服务的事务拆分成多个事务,每个子事务都需要定义一个对应的补偿操作。通过异步的模式来完 成整个Saga流程。
在Choerodon中,将项目创建流程拆分成多个Saga。
// ProjectService
@Transactional
@Override
@Saga(code = PROJECT_CREATE, description = "iam创建项目", inputSchemaClass = ProjectEventPayload.class)
public ProjectDTO createProject(ProjectDTO projectDTO) {
if (projectDTO.getEnabled() == null) {
projectDTO.setEnabled(true);
}
final ProjectE projectE = ConvertHelper.convert(projectDTO, ProjectE.class);
ProjectDTO dto;
if (devopsMessage) {
dto = createProjectBySaga(projectE);
} else {
ProjectE newProjectE = projectRepository.create(projectE);
initMemberRole(newProjectE);
dto = ConvertHelper.convert(newProjectE, ProjectDTO.class);
}
return dto;
}
private ProjectDTO createProjectBySaga(final ProjectE projectE) {
ProjectEventPayload projectEventMsg = new ProjectEventPayload();
CustomUserDetails details = DetailsHelper.getUserDetails();
projectEventMsg.setUserName(details.getUsername());
projectEventMsg.setUserId(details.getUserId());
ProjectE newProjectE = projectRepository.create(projectE);
projectEventMsg.setRoleLabels(initMemberRole(newProjectE));
projectEventMsg.setProjectId(newProjectE.getId());
projectEventMsg.setProjectCode(newProjectE.getCode());
projectEventMsg.setProjectName(newProjectE.getName());
OrganizationDO organizationDO =
organizationRepository.selectByPrimaryKey(newProjectE.getOrganizationId());
projectEventMsg.setOrganizationCode(organizationDO.getCode());
projectEventMsg.setOrganizationName(organizationDO.getName());
try {
String input = mapper.writeValueAsString(projectEventMsg);
sagaClient.startSaga(PROJECT_CREATE, new StartInstanceDTO(input, "project", newProjectE.getId() + ""));
} catch (Exception e) {
throw new CommonException("error.organizationProjectService.createProject.event", e);
}
return ConvertHelper.convert(newProjectE, ProjectDTO.class);
}
// DevopsSagaHandler
@Component
public class DevopsSagaHandler {
private static final Logger LOGGER = LoggerFactory.getLogger(DevopsSagaHandler.class);
private final Gson gson = new Gson();
@Autowired
private ProjectService projectService;
@Autowired
private GitlabGroupService gitlabGroupService;
private void loggerInfo(Object o) {
LOGGER.info("data: {}", o);
}
/**
* 创建项目saga
*/
@SagaTask(code = "devopsCreateProject",
description = "devops创建项目",
sagaCode = "iam-create-project",
seq = 1)
public String handleProjectCreateEvent(String msg) {
ProjectEvent projectEvent = gson.fromJson(msg, ProjectEvent.class);
loggerInfo(projectEvent);
projectService.createProject(projectEvent);
return msg;
}
/**
* 创建组事件
*/
@SagaTask(code = "devopsCreateGitLabGroup",
description = "devops 创建 GitLab Group",
sagaCode = "iam-create-project",
seq = 2)
public String handleGitlabGroupEvent(String msg) {
ProjectEvent projectEvent = gson.fromJson(msg, ProjectEvent.class);
GitlabGroupPayload gitlabGroupPayload = new GitlabGroupPayload();
BeanUtils.copyProperties(projectEvent, gitlabGroupPayload);
loggerInfo(gitlabGroupPayload);
gitlabGroupService.createGroup(gitlabGroupPayload, "");
return msg;
}
}
可以发现,Saga和可靠事件模式很相似,都是将微服务下的事务作为一个个体,然后通过有序序列来执行。但是在实现上,有很大的区别。
可靠事件依赖于Kafka,消费者属于被动监听Kafka的消息,鉴于Kafka自身的原因,如果对消费者进行横向扩展,效果并不理想。
而在 Saga 中,我们为 Saga 分配了一个orchestrator作为事务管理器,当服务启动时,将服务中所有的 SagaTask 注册到管理器中。当一个 Saga 实例通过sagaClient.startSaga启动时,服务消费者就可以通过轮询的方式主动拉取到该实例对应的Saga数据,并执行对应的业务逻辑。执行的状态可以通过事务管理器进行查看,展现在界面上。
通过Choerodon的事务定义界面,将不同服务的SagaTask 收集展示,可以看到系统中的所有Saga 定义以及所属的微服务。同时,在每一个Saga 定义的详情中,可以详细的了解到该Saga的详细信息:
在这种情况下,当并发量增多或者 SagaTask 的数量很多的时候,可以很便捷的对消费者进行扩展。
Saga的补偿机制
Saga支持向前和向后恢复:
- 向后恢复:如果任意一个子事务失败,则补偿所有已完成的事务
- 向前恢复:如果子事务失败,则重试失败的事务
Choerodon 采用的是向前恢复,通过界面可以很方便的对事务的信息进行检索,当Saga发生失败时,也可以看到失败的原因,并且手动进行重试。
通过Choerodon的事务实例界面,可以查询到系统中运行的所有Saga实例,掌握实例的运行状态,并对失败的实例进行手动的重试:
对于向前恢复而言,理论上我们的子事务最终总是会成功的。但是在实际的应用中,可能因为一些其他的因素,造成失败,那么就需要有对应的故障恢复回滚的机制。
使用Saga的要求
Saga是一个简单易行的方案,使用Saga的两个要求:
- 幂等:幂等是每个Saga 多次执行所产生的影响应该和一次执行的影响相同。一个很简单的例子,上述流程中,如果在创建项目的时候因为网络问题导致超时,这时如果进行重试,请求恢复。如果没有幂等,就可能创建了两个项目。
- 可交换:可交换是指在同一层级中,无论先执行那个Saga最终的结果都应该是一样的。
综合比较
2PC是一个阻塞式,严格满足ACID原则的方案,但是因为性能上的原因在微服务架构下并不是最佳 的方案。
Event sourcing 为整体架构提供了一些可能性。但是如果随着业务的变更,事件结构自身发生一定的变化时,需要通过额外的方式来进行补偿,而且当下并没有一个成熟完善的框架。
基于事件驱动的可靠事件是建立在消息队列基础上,每一个服务,除了自己的业务逻辑之外还需要额外的事件 表来保存当前的事件的状态,所以相当于是把集中式的事务状态分布到了每一个服务当中。虽然服务之间去中 心化,但是当服务增多,服务之间的分布式事务带来的应用复杂度也再提高,当事件发生问题时,难以定位。
而Saga降低了数据一致性的复杂度,简单易行,将所有的事务统一可视化管理,让运维更加简单,同时每一个 消费者可以进行快速的扩展,实现了事务的高可用。
本篇文章出自Choerodon猪齿鱼社区董凡。
作者:Choerodon猪齿鱼文章来源:https://www.toymoban.com/news/detail-827265.html
原文地址:https://segmentfault.com/a/1190000022165222文章来源地址https://www.toymoban.com/news/detail-827265.html
到了这里,关于Choerodon猪齿鱼平台中的微服务数据一致性解决方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!