解释器模式
1.简介
解释器模式(Interpreter Pattern)是一种行为设计模式,它用于定义语言的文法,并且解释语言中的表达式。在Java中,解释器模式可以用于构建解释器以解析特定的语言或表达式,如数学表达式、查询语言等。
优点:
-
灵活性: 解释器模式可以
灵活地添加新的表达式和规则,因此适用于处理不断变化的语言或表达式。 - 易扩展性: 可以轻松地扩展文法,添加新的解释器,而不会影响现有的解释器。
-
简化语法分析: 将文法规则
分解成一个个小的解释器,使得语法分析更加简单和清晰。 -
易于实现: 每个表达式都可以由一个简单的解释器实现,
降低了系统的复杂度,易于实现和维护。
缺点:
- 复杂度高: 对于复杂的文法规则,需要创建大量的解释器对象,可能会导致类爆炸问题,增加系统的复杂度。
- 执行效率低: 解释器模式通常采用递归调用的方式进行解释,可能会导致解释过程比较耗时,执行效率低下。
- 维护困难: 随着文法的变化和解释器的增加,维护成本可能会增加,特别是在处理复杂语言时。
使用场景:
-
特定领域语言(DSL)解析: 适用于需要解析和执行特定领域语言的场景,如
数学表达式、正则表达式、查询语言等。 -
规则引擎: 用于
构建规则引擎,根据不同的规则执行相应的操作。 - 编译器和解释器设计: 可用于编写编译器和解释器,将源代码转换成目标代码或执行相应的操作。
-
配置文件解析: 适用于解析配置文件,
将配置信息转换成相应的对象或操作。
2.案例-生成SQL建表语句
需求描述:
假设我们需要开发一个简单的数据库表生成工具,它可以根据用户提供的列信息生成相应的 SQL 建表语句。用户可以指定表名、列名、数据类型等信息,并且可以选择是否设置列为主键、非空等约束。
用户需求:
- 用户希望能够指定表名以及列的详细信息,包括列名、数据类型、长度等。
- 用户希望能够选择是否将某列设置为主键、非空等约束。
- 用户希望能够生成符合特定数据库类型的建表语句,例如 PostgreSQL、MySQL 等。
实现思路:
-
定义抽象表达式接口:
- 创建一个接口,定义解释方法
interpret(),该方法将返回解释后的结果。
- 创建一个接口,定义解释方法
-
创建终结符表达式类:
- 实现抽象表达式接口的类,用于表示文法中的最小单元。
- 包含需要解释的数据和解释方法的具体实现。
-
创建非终结符表达式类:
- 实现抽象表达式接口的类,用于表示文法中的复合结构。
- 包含其他表达式对象或者其他操作的组合,并实现解释方法。
-
创建环境类(Context):
- 封装解释器需要的数据和方法。
- 提供执行解释器的方法,并返回结果。
- 解耦解释器与客户端代码:
Context提供统一接口,客户端代码不需要直接操作解释器,降低了耦合度。 - 封装解释器的创建逻辑:
Context封装解释器的创建逻辑,使客户端代码更简洁,只需调用Context方法即可执行解释器。 - 统一的异常处理机制:
Context提供统一异常处理,捕获解释器执行过程中的异常,进行统一处理,如记录日志、返回错误信息。 - 支持扩展和替换解释器: 可以通过修改
Context中的创建逻辑来引入新的解释器实现或替换现有实现,提高系统的灵活性和可扩展性。
-
客户端代码:
- 创建具体的终结符和非终结符表达式对象。
- 创建环境对象,将表达式对象传递给环境对象。
- 调用环境对象的解释方法,获取解释结果。
2.1.实现
2.1.1.抽共享表达式接口
/**
* 定义抽象表达式接口
* @author 13723
* @version 1.0
* 2024/2/6 10:01
*/
public interface Expression {
/**
* 解释方法
* @return 解释结果
*/
String interpret();
}
2.1.2.终结符表达式类
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
/**
* 终结符实现类
* 终结符(Terminal Symbol):在文法中,终结符是指不能进一步被分解的符号或标记。
* 在语法分析过程中,终结符是输入字符的最小单元。终结符是文法的基本元素,通常代表实际的词汇或标记。
* 文法中的每一个终结符都有一个具体终结表达式与之相对应。
*/
@Getter @Setter
@NoArgsConstructor
public class ColumnExpression implements Expression {
/**
* 列名
*/
private String name;
/**
* 列类型
*/
private String type;
/**
* 列长度
*/
private String length;
/**
* 注释
*/
private String comment;
/**
* 是否是主键
*/
private Boolean primaryKey = false;
/**
* 是否是非空
*/
private Boolean notNull = false;
public ColumnExpression(String name, String type, String length) {
this.name = name;
this.type = type;
this.length = length;
}
public ColumnExpression(String name, String type, String length, String comment) {
this.name = name;
this.type = type;
this.length = length;
this.comment = comment;
}
public ColumnExpression(String name, String type, String length, String comment, Boolean notNull) {
this.name = name;
this.type = type;
this.length = length;
this.comment = comment;
this.notNull = notNull;
}
public ColumnExpression(String name, String type, String length, String comment, Boolean primaryKey, Boolean notNull) {
this.name = name;
this.type = type;
this.length = length;
this.primaryKey = primaryKey;
this.notNull = notNull;
this.comment = comment;
}
@Override
public String interpret() {
StringBuilder sb = new StringBuilder();
sb.append("\t").append("\"").append(name).append("\"").append(" ").append(type).append("(").append(length).append(")");
// 如果设置了不为空,根据数据类型添加 NOT NULL
if (notNull) {
if ("VARCHAR".equals(type) || "CHAR".equals(type) || "TEXT".equals(type) || "BLOB".equals(type) || "CLOB".equals(type) || "NCLOB".equals(type)){
sb.append(" COLLATE \"pg_catalog\".\"default\" NOT NULL" );
}else {
sb.append(" NOT NULL");
}
}
return sb.toString();
}
}
2.1.3.非终结符表达式类
package com.hrfan.java_se_base.pattern.Interpreter_pattern.se;
import lombok.Getter;
import lombok.Setter;
import org.apache.commons.lang3.StringUtils;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* 非终结符(Nonterminal Symbol):非终结符是可以被进一步分解的符号或标记,在文法规则中用来描述语言的结构和组织。
* 非终结符通常代表语法结构中的一类元素,可以是语法规则的左侧或右侧的一部分。
* 文法中的每条规则都对应于一个非终结符表达式。
*/
@Getter @Setter
public class TableExpression implements Expression{
private String tableName;
private List<ColumnExpression> columns;
public TableExpression(String tableName) {
this.tableName = tableName;
this.columns = new ArrayList<>();
}
// 添加列
public void addColumn(ColumnExpression column) {
columns.add(column);
}
// 获取设置主键的数据
public List<String> getColumnPrimaryKey(){
List<String> collect = columns.stream().filter(ColumnExpression::getPrimaryKey).map(ColumnExpression::getName).collect(Collectors.toList());
return collect;
}
// 设置注释 和 字段名称
public Map<String,String> getColumnComment(){
Map<String, String> map = columns.stream().filter(it -> StringUtils.isNotBlank(it.getComment())).collect(Collectors.toMap(ColumnExpression::getName, ColumnExpression::getComment));
return map;
}
@Override
public String interpret() {
// 获取主键的列名
List<String> columnPrimaryKey = getColumnPrimaryKey();
StringBuilder sb = new StringBuilder("\nCREATE TABLE \"gwstd\".\"" + tableName + "\" " + "(" + "\n");
for (int i = 0; i < columns.size(); i++) {
// 执行非终结符解释逻辑
sb.append(columns.get(i).interpret());
if (i < columns.size() - 1 || columnPrimaryKey.size() > 0){
sb.append(", \n");
}
}
if (columnPrimaryKey.size() > 0){
sb.append("\tCONSTRAINT ").append("\"").append(tableName).append("_pkey\"").append("PRIMARY KEY (");
for (int i = 0; i < columnPrimaryKey.size(); i++) {
sb.append("\"").append(columnPrimaryKey.get(i)).append("\"");
if (i < columnPrimaryKey.size() - 1) {
sb.append(",");
}
}
sb.append(")\n");
}
sb.append(");");
// 生成输入语句
sb.append("\n");
sb.append("ALTER TABLE \"gwstd\".").append("\"").append(tableName).append("\"").append(" OWNER TO \"postgres\"").append(";");
// 生成注释
Map<String, String> columnComment = getColumnComment();
if (!columnComment.isEmpty()){
for (Map.Entry<String, String> entry : columnComment.entrySet()) {
sb.append("\n");
// COMMENT ON COLUMN "gwstd"."t_dec_order_head"."sid" IS '主键Sid';
sb.append("COMMENT ON COLUMN \"gwstd\".").append("\"").append(tableName).append("\"").append(".").append("\"").append(entry.getKey()).append("\"").append(" IS '").append(entry.getValue()).append("';");
}
}
return sb.toString();
}
}
2.1.4.创建Context(承上启下)
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.lang.invoke.MethodHandles;
/**
* @author 13723
* @version 1.0
* 2024/2/6 10:17
*/
public class Context {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
/**
* 建表语句表达式
*/
private Expression expression;
public Context(){
}
/**
* 解释方法
*/
public Context(Expression expression){
this.expression = expression;
}
/**
* 执行解释方法
* @return 解释结果
*/
public String interpret(){
return expression.interpret();
}
}
2.1.5.测试类
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.lang.invoke.MethodHandles;
/**
* @author 13723
* @version 1.0
* 2024/2/6 10:20
*/
public class ExpressCreateTest {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
@Test
@DisplayName("测试建表语句解释器")
public void test(){
// 创建表对象(使用建造者模式构建表对象)
TableExpressionBuilder builder = new TableExpressionBuilder("t_dec_erp_test_students");
// 非终结符解释器 中 添加 终结符解释器
// 字段名称,字段类型,字段长度,字段注释,是否为主键,是否为空
builder.addColumn(new ColumnExpression("sid", "VARCHAR", "11","主键sid",true,true))
.addColumn(new ColumnExpression("name", "VARCHAR", "255","姓名"))
.addColumn(new ColumnExpression("age", "NUMERIC", "3","年龄",true))
.addColumn(new ColumnExpression("email", "VARCHAR", "255","邮箱",true))
.addColumn(new ColumnExpression("address", "VARCHAR", "255","联系地址"))
.addColumn(new ColumnExpression("telephone", "VARCHAR", "255","联系电话"));
// 构建表达式
TableExpression expression = builder.build();
// 通过Context执行解释方法,获取解释结果.
String interpret = new Context(expression).interpret();
logger.error("最终生成sql:\n{}",interpret);
}
}
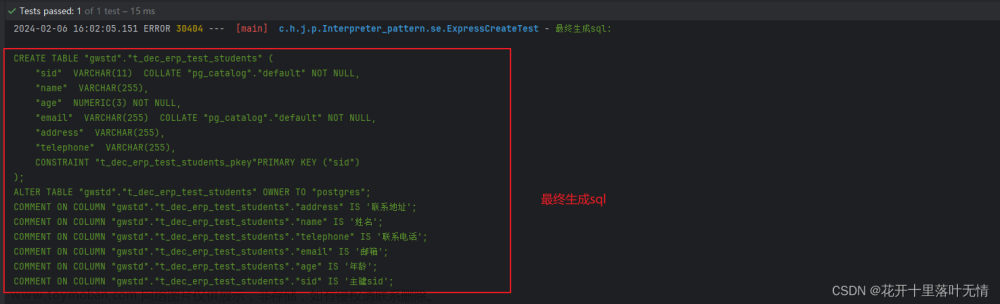
CREATE TABLE "gwstd"."t_dec_erp_test_students" (
"sid" VARCHAR(11) COLLATE "pg_catalog"."default" NOT NULL,
"name" VARCHAR(255),
"age" NUMERIC(3) NOT NULL,
"email" VARCHAR(255) COLLATE "pg_catalog"."default" NOT NULL,
"address" VARCHAR(255),
"telephone" VARCHAR(255),
CONSTRAINT "t_dec_erp_test_students_pkey"PRIMARY KEY ("sid")
);
ALTER TABLE "gwstd"."t_dec_erp_test_students" OWNER TO "postgres";
COMMENT ON COLUMN "gwstd"."t_dec_erp_test_students"."address" IS '联系地址';
COMMENT ON COLUMN "gwstd"."t_dec_erp_test_students"."name" IS '姓名';
COMMENT ON COLUMN "gwstd"."t_dec_erp_test_students"."telephone" IS '联系电话';
COMMENT ON COLUMN "gwstd"."t_dec_erp_test_students"."email" IS '邮箱';
COMMENT ON COLUMN "gwstd"."t_dec_erp_test_students"."age" IS '年龄';
COMMENT ON COLUMN "gwstd"."t_dec_erp_test_students"."sid" IS '主键sid';


2.2.Spring使用场景
2.2.1.Spring-SpEL
Spring表达式语言(SpEL)允许在运行时动态计算值,它可以用于配置文件、注解等多种场景中。在SpEL的背后,实际上就是使用了解释器模式。
Spring框架中,与Spring EL(表达式语言)相关的类位于org.springframework.expression包下。以下是几个与Spring EL密切相关的类的简要介绍:
-
SpelExpression: 代表一个EL表达式,它在内部通过抽象语法树(AST)来表示表达式。EL表达式的求值是通过调用
this.ast.getValue(expressionState);来实现的。 -
ExpressionParser: 表达式解析器接口,定义了解析EL表达式的方法。Spring提供了
SpelExpressionParser作为默认的表达式解析器实现。 - StandardEvaluationContext: 标准的评估上下文,用于在表达式求值期间存储变量和函数。它提供了用于设置变量和函数的方法,这些变量和函数可以在EL表达式中使用。
-
EvaluationContext: 评估上下文接口,用于在表达式求值期间提供变量和函数的访问。
StandardEvaluationContext是EvaluationContext接口的实现之一。 - SpelNode: SpEL语法树的节点,代表了EL表达式的各个部分。每个节点都有自己的类型和操作,用于实现EL表达式的解析和求值。
2.2.1.1.案例代码
@Test
@DisplayName("测试@Value")
public void test2(){
// 1. 构建解析器
ExpressionParser parser = new SpelExpressionParser();
// 2. 解析表达式
Expression expression = parser.parseExpression("100 * 2 + 200 * 1 + 100000");
// 3. 获取结果
int result = (Integer) expression.getValue();
// 4. 打印结果
logger.error("result:{}",result);
}

语法树
抽象语法树(Abstract Syntax Tree,AST)是一种用于表示编程语言代码结构的树形数据结构。
在编译器和解释器中,AST是一种常见的数据结构,用于表示程序代码的语法结构和语义信息。
在Java中,AST抽象语法树是指代表Java源代码结构的树形数据结构。它由多个节点组成,每个节点代表源代码中的一个语法元素,例如表达式、语句、方法调用等。AST的根节点表示整个程序的起始点,而子节点则代表程序中的具体语法结构。
# 语法树
+
/ \
* +
/ \ / \
100 2 * 100000
/ \
200 1
2.2.1.2.SpelExpression
SpelExpression 是 Spring 表达式语言(SpEL)中的一个组成部分,用于表达特定的表达式。它内部采用抽象语法树(AST)来表示表达式的结构。计算表达式的值是通过调用 this.ast.getValue(expressionState); 实现的。在这个过程中,AST被用来解释和执行表达式,最终得到表达式的计算结果。
public class SpelExpression implements Expression {
@Nullable
public Object getValue() throws EvaluationException {
CompiledExpression compiledAst = this.compiledAst;
if (compiledAst != null) {
try {
EvaluationContext context = this.getEvaluationContext();
return compiledAst.getValue(context.getRootObject().getValue(), context);
} catch (Throwable var4) {
if (this.configuration.getCompilerMode() != SpelCompilerMode.MIXED) {
throw new SpelEvaluationException(var4, SpelMessage.EXCEPTION_RUNNING_COMPILED_EXPRESSION, new Object[0]);
}
}
this.compiledAst = null;
this.interpretedCount.set(0);
}
ExpressionState expressionState = new ExpressionState(this.getEvaluationContext(), this.configuration);
Object result = this.ast.getValue(expressionState);
this.checkCompile(expressionState);
return result;
}
}
2.2.1.2.SpelNodeImpl
SpelNodeImpl 是 Spring 表达式语言(SpEL)中的关键类,用于表示已解析的表达式在抽象语法树(AST)中的节点。
在解释器模式中,AST 的节点充当了终结符和非终结符的角色,帮助构建表达式的结构。
SpelNodeImpl 的子类包括以下几种类型:
- Literal: 代表各种类型值的父类。
- Operator: 代表各种操作符的父类。
- Indexer 等:代表其他类型的节点。
public abstract class SpelNodeImpl implements SpelNode, Opcodes {
private static final SpelNodeImpl[] NO_CHILDREN = new SpelNodeImpl[0];
protected SpelNodeImpl[] children;
@Nullable
private SpelNodeImpl parent;
@Nullable
protected final <T> T getValue(ExpressionState state, Class<T> desiredReturnType) throws EvaluationException {
return ExpressionUtils.convertTypedValue(state.getEvaluationContext(), this.getValueInternal(state), desiredReturnType);
}
// 抽象方法子类实现,获取对象值
public abstract TypedValue getValueInternal(ExpressionState expressionState) throws EvaluationException;
}
2.2.1.3.IntLiteral
IntLiteral 表示整型文字的表达式语言的ast结点
public class IntLiteral extends Literal {
private final TypedValue value;
public IntLiteral(String payload, int startPos, int endPos, int value) {
super(payload, startPos, endPos);
this.value = new TypedValue(value);
this.exitTypeDescriptor = "I";
}
public TypedValue getLiteralValue() {
return this.value;
}
//
}
2.2.1.4.OpPlus
OpPlus 表示加法的ast结点,在 getValueInternal 方法中对操作符两边进行相加操作
public class OpPlus extends Operator {
private static final int MAX_CONCATENATED_STRING_LENGTH = 100000;
public OpPlus(int startPos, int endPos, SpelNodeImpl... operands) {
super("+", startPos, endPos, operands);
Assert.notEmpty(operands, "Operands must not be empty");
}
public TypedValue getValueInternal(ExpressionState state) throws EvaluationException {
SpelNodeImpl leftOp = this.getLeftOperand();
if (this.children.length < 2) {
Object operandOne = leftOp.getValueInternal(state).getValue();
if (operandOne instanceof Number) {
if (operandOne instanceof Double) {
this.exitTypeDescriptor = "D";
} else if (operandOne instanceof Float) {
this.exitTypeDescriptor = "F";
} else if (operandOne instanceof Long) {
this.exitTypeDescriptor = "J";
} else if (operandOne instanceof Integer) {
this.exitTypeDescriptor = "I";
}
return new TypedValue(operandOne);
} else {
return state.operate(Operation.ADD, operandOne, (Object)null);
}
} else {
// 递归调用leftOp的 getValueInternal(state) ,获取操作符左边的值
TypedValue operandOneValue = leftOp.getValueInternal(state);
Object leftOperand = operandOneValue.getValue();
// 递归调用children[1]的 getValueInternal(state) ,获取操作符右边的值
TypedValue operandTwoValue = this.getRightOperand().getValueInternal(state);
Object rightOperand = operandTwoValue.getValue();
// 如果操作符左右都是数值类型,则将它们相加
if (leftOperand instanceof Number && rightOperand instanceof Number) {
Number leftNumber = (Number)leftOperand;
Number rightNumber = (Number)rightOperand;
if (!(leftNumber instanceof BigDecimal) && !(rightNumber instanceof BigDecimal)) {
if (!(leftNumber instanceof Double) && !(rightNumber instanceof Double)) {
if (!(leftNumber instanceof Float) && !(rightNumber instanceof Float)) {
if (!(leftNumber instanceof BigInteger) && !(rightNumber instanceof BigInteger)) {
if (!(leftNumber instanceof Long) && !(rightNumber instanceof Long)) {
if (!CodeFlow.isIntegerForNumericOp(leftNumber) && !CodeFlow.isIntegerForNumericOp(rightNumber)) {
return new TypedValue(leftNumber.doubleValue() + rightNumber.doubleValue());
} else {
this.exitTypeDescriptor = "I";
return new TypedValue(leftNumber.intValue() + rightNumber.intValue());
}
} else {
this.exitTypeDescriptor = "J";
return new TypedValue(leftNumber.longValue() + rightNumber.longValue());
}
} else {
BigInteger leftBigInteger = (BigInteger)NumberUtils.convertNumberToTargetClass(leftNumber, BigInteger.class);
BigInteger rightBigInteger = (BigInteger)NumberUtils.convertNumberToTargetClass(rightNumber, BigInteger.class);
return new TypedValue(leftBigInteger.add(rightBigInteger));
}
} else {
this.exitTypeDescriptor = "F";
return new TypedValue(leftNumber.floatValue() + rightNumber.floatValue());
}
} else {
this.exitTypeDescriptor = "D";
return new TypedValue(leftNumber.doubleValue() + rightNumber.doubleValue());
}
} else {
BigDecimal leftBigDecimal = (BigDecimal)NumberUtils.convertNumberToTargetClass(leftNumber, BigDecimal.class);
BigDecimal rightBigDecimal = (BigDecimal)NumberUtils.convertNumberToTargetClass(rightNumber, BigDecimal.class);
return new TypedValue(leftBigDecimal.add(rightBigDecimal));
}
} else {
String rightString;
String leftString;
if (leftOperand instanceof String && rightOperand instanceof String) {
this.exitTypeDescriptor = "Ljava/lang/String";
rightString = (String)leftOperand;
leftString = (String)rightOperand;
this.checkStringLength(rightString);
this.checkStringLength(leftString);
return this.concatenate(rightString, leftString);
} else if (leftOperand instanceof String) {
rightString = (String)leftOperand;
this.checkStringLength(rightString);
leftString = rightOperand == null ? "null" : convertTypedValueToString(operandTwoValue, state);
this.checkStringLength(leftString);
return this.concatenate(rightString, leftString);
} else if (rightOperand instanceof String) {
rightString = (String)rightOperand;
this.checkStringLength(rightString);
leftString = leftOperand == null ? "null" : convertTypedValueToString(operandOneValue, state);
this.checkStringLength(leftString);
return this.concatenate(leftString, rightString);
} else {
return state.operate(Operation.ADD, leftOperand, rightOperand);
}
}
}
}
}
解释器模式相对于其他设计模式确实在实际应用中使用较少,这主要是由于以下几个原因:文章来源:https://www.toymoban.com/news/detail-827284.html
- 复杂性和性能开销: 解释器模式的实现可能会引入较高的复杂性和性能开销。解释器需要对输入进行解析、分析和执行,这可能导致性能上的损失,并且随着解释器规则的增多,代码的复杂度也会增加。
- 不易理解和维护: 解释器模式的实现通常较为复杂,需要设计者对语法和语义有深入的理解,同时需要维护大量的解释器规则。这使得解释器模式在代码的可读性和可维护性方面存在挑战。
- 有限的适用场景: 解释器模式通常适用于特定领域的问题,例如编译器、正则表达式引擎等。在许多常见的软件开发场景中,并不经常需要使用解释器模式来解决问题。
- 其他替代方案: 对于一些需要解释和执行逻辑的问题,通常有更简单、更高效的替代方案,例如使用编译器、脚本引擎、规则引擎等。这些替代方案能够更直接地执行逻辑,而不需要通过解释器的中间层。
尽管解释器模式在一些特定的领域和场景下仍然有其价值,但在许多常见的软件开发任务中,它并不是第一选择。因此,虽然解释器模式是一种重要的设计模式,但其应用相对较少。文章来源地址https://www.toymoban.com/news/detail-827284.html
到了这里,关于解锁Spring Boot中的设计模式—02.解释器模式:探索【解释器模式】的奥秘与应用实践!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!









