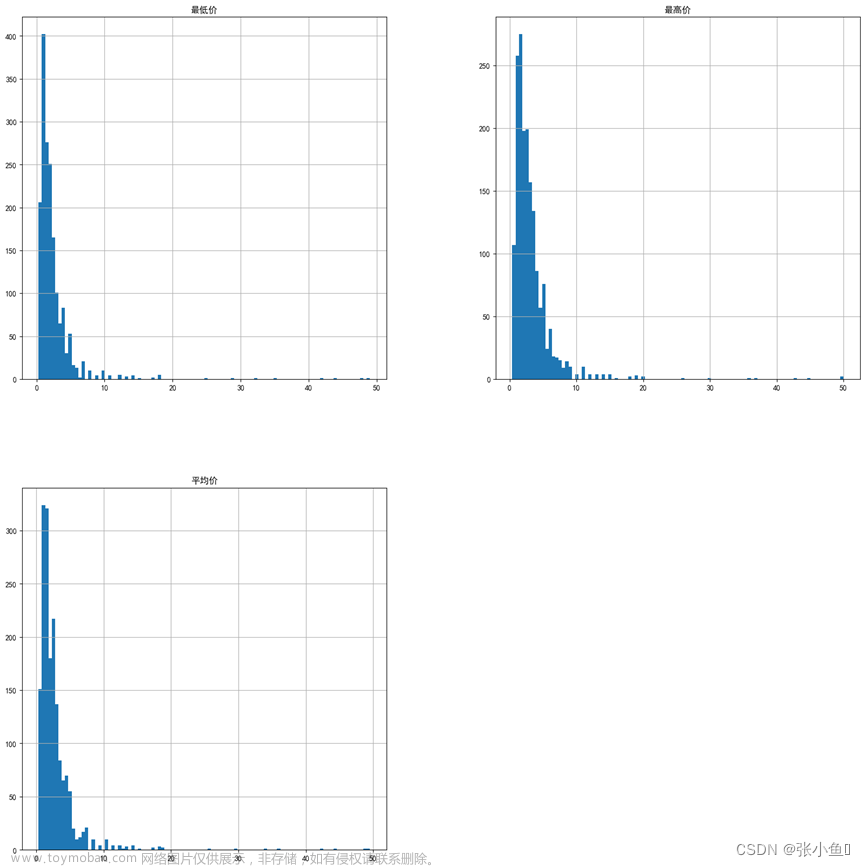
简介
Python 的 pandas 包用于数据操作和分析,旨在让您以直观的方式处理带标签或关联数据。
pandas 包提供了电子表格功能,但由于您正在使用 Python,因此它比传统的图形电子表格程序要快得多且更高效。
在本教程中,我们将介绍如何设置一个大型数据集,pandas 的 groupby() 和 pivot_table() 函数,以及如何可视化数据。
要熟悉 pandas 包,您可以阅读我们的教程《Python 3 中 pandas 包及其数据结构的介绍》。
先决条件
本指南将介绍如何在本地桌面或远程服务器上使用 pandas 处理数据。处理大型数据集可能会占用大量内存,因此在任何情况下,计算机都需要至少 2GB 内存 来执行本指南中的一些计算。
在本教程中,我们将使用 Jupyter Notebook 来处理数据。如果您尚未安装,请按照我们的教程安装并设置 Python 3 的 Jupyter Notebook。
设置数据
在本教程中,我们将使用美国社会保障网站上提供的有关婴儿姓名的数据,该数据以 8MB 的压缩文件形式提供。
让我们在本地计算机上激活我们的 Python 3 编程环境,或者在服务器上从正确的目录开始:
cd environments
. my_env/bin/activate
现在让我们为我们的项目创建一个新目录。我们可以称之为 names,然后进入该目录:
mkdir names
cd names
在该目录中,我们可以使用 curl 命令从社会保障网站获取 zip 文件:
curl -O https://www.ssa.gov/oact/babynames/names.zip
文件下载完成后,让我们验证我们将要使用的所有软件包是否已安装:
-
numpy用于支持多维数组 -
matplotlib用于可视化数据 -
pandas用于数据分析 -
seaborn用于美化我们的 matplotlib 统计图形
如果您尚未安装任何软件包,请使用 pip 安装它们,例如:
pip install pandas
pip install matplotlib
pip install seaborn
如果您尚未安装 numpy 包,它也将被安装。
现在我们可以启动 Jupyter Notebook:
jupyter notebook
一旦您进入 Jupyter Notebook 的 Web 界面,您将在那里看到 names.zip 文件。
要创建一个新的笔记本文件,请从右上角的下拉菜单中选择 New > Python 3:
!创建一个新的 Python 3 笔记本
这将打开一个笔记本。
让我们从导入我们将要使用的软件包开始。在我们的笔记本顶部,我们应该写入以下内容:
import numpy as np
import matplotlib.pyplot as pp
import pandas as pd
import seaborn
我们可以运行此代码,并通过键入 ALT + ENTER 进入新的代码块。
让我们还告诉 Python Notebook 在线保留我们的图形:
matplotlib inline
让我们运行代码,并通过键入 ALT + ENTER 继续。
从这里,我们将继续解压缩 zip 存档,将 CSV 数据集加载到 pandas 中,然后连接 pandas 数据帧。
解压缩 Zip 存档
要将 zip 存档解压缩到当前目录中,我们将导入 zipfile 模块,然后使用文件名(在我们的情况下是 names.zip)调用 ZipFile 函数:
import zipfile
zipfile.ZipFile('names.zip').extractall('.')
我们可以运行代码,并通过键入 ALT + ENTER 继续。
现在,如果您回到 names 目录,您将在其中看到以 CSV 格式存储的姓名数据的 .txt 文件。这些文件将对应于文件中的年份数据,从 1881 年到 2015 年。这些文件都遵循类似的命名约定。例如,2015 年的文件名为 yob2015.txt,而 1927 年的文件名为 yob1927.txt。
为了查看其中一个文件的格式,让我们使用 Python 打开一个文件并显示前 5 行:
open('yob2015.txt','r').readlines()[:5]
运行代码,并通过键入 ALT + ENTER 继续。
['Emma,F,20355\n',
'Olivia,F,19553\n',
'Sophia,F,17327\n',
'Ava,F,16286\n',
'Isabella,F,15504\n']
数据的格式是首先是姓名(如 Emma 或 Olivia),然后是性别(女性姓名为 F,男性姓名为 M),然后是当年出生具有该姓名的婴儿数量(2015 年出生的名为 Emma 的婴儿有 20,355 个)。
有了这些信息,我们就可以将数据加载到 pandas 中。
将 CSV 数据加载到 pandas 中
要将逗号分隔值数据加载到 pandas 中,我们将使用 pd.read_csv() 函数,传递文本文件的名称以及我们决定的列名。我们将将其分配给一个变量,本例中为 names2015,因为我们使用的是 2015 年出生文件的数据。
names2015 = pd.read_csv('yob2015.txt', names = ['Name', 'Sex', 'Babies'])
键入 ALT + ENTER 来运行代码并继续。
为了确保这一步成功,让我们显示表的顶部:
names2015.head()
当我们运行代码并继续使用 ALT + ENTER 时,我们将看到以下输出:
!names2015.head 输出
我们的表现在包含了按列组织的名称、性别和每个名称出生的婴儿数量的信息。
连接 pandas 对象
连接 pandas 对象将允许我们处理 names 目录中的所有单独的文本文件。
要连接这些文件,我们首先需要通过将变量分配给未填充的列表数据类型来初始化一个列表:
all_years = []
一旦我们这样做了,我们将使用 for 循环来遍历所有年份的文件,范围从 1880 年到 2015 年。我们将在 2015 年的末尾添加 +1,以便在循环中包括 2015 年。
all_years = []
for year in range(1880, 2015+1):
在循环内部,我们将使用字符串格式化程序将每个文本文件的值附加到列表中。我们将把这些值传递给 year 变量。同样,我们将为 Name、Sex 和 Babies 指定列:
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
此外,我们将为每一年创建一个列,以保持这些列的顺序。我们可以在每次迭代后使用索引 -1 来指向它们。
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = year
最后,我们将使用 pd.concat() 函数将其添加到 pandas 对象中进行连接。我们将使用变量 all_names 存储这些信息。
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = year
all_names = pd.concat(all_years)
我们现在可以使用 ALT + ENTER 运行循环,然后通过调用结果表的尾部(最底部的行)来检查输出:
all_names.tail()
!all_names.tail 输出
我们的数据集现在已经完整,准备在 pandas 中进行进一步处理。
数据分组
使用 pandas,您可以使用 .groupby() 函数按列对数据进行分组。使用我们的 all_names 变量作为完整数据集,我们可以使用 groupby() 将数据拆分为不同的桶。
让我们按性别和年份对数据集进行分组。我们可以这样设置:
group_name = all_names.groupby(['Sex', 'Year'])
我们可以运行代码并继续使用 ALT + ENTER。
此时,如果我们只调用 group_name 变量,我们将得到以下输出:
<pandas.core.groupby.DataFrameGroupBy object at 0x1187b82e8>
这向我们显示它是一个 DataFrameGroupBy 对象。该对象包含如何对数据进行分组的指令,但它不提供如何显示值的指令。
要显示值,我们需要提供指令。我们可以计算 .size()、.mean() 和 .sum(),例如,以返回一个表。
让我们从 .size() 开始:
group_name.size()
当我们运行代码并继续使用 ALT + ENTER 时,我们的输出将如下所示:
Sex Year
F 1880 942
1881 938
1882 1028
1883 1054
1884 1172
...
这些数据看起来不错,但它可能更易读。我们可以通过附加 .unstack 函数使其更易读:
group_name.size().unstack()
现在当我们运行代码并继续输入 ALT + ENTER 时,输出将如下所示:
!group_name.size().unstack() 输出
这些数据告诉我们每年有多少个女性和男性的名字。例如,在 1889 年,有 1,479 个女性名字和 1,111 个男性名字。在 2015 年,有 18,993 个女性名字和 13,959 个男性名字。这显示随着时间的推移,名字的多样性更大。
如果我们想要获得出生的总婴儿数,我们可以使用 .sum() 函数。让我们将其应用于较小的数据集,即我们之前创建的单个 yob2015.txt 文件的 names2015 集:
names2015.groupby(['Sex']).sum()
让我们键入 ALT + ENTER 来运行代码并继续:

这显示了 2015 年出生的男性和女性婴儿的总数,尽管数据集中只计算了那一年至少使用了 5 次的名字的婴儿。
pandas 的 .groupby() 函数允许我们将数据分成有意义的组。
透视表
透视表对于总结数据非常有用。它们可以自动对存储在一个表中的数据进行排序、计数、求和或求平均值。然后,它们可以在一个新的表中显示这些操作的结果。
在 pandas 中,使用 pivot_table() 函数来创建透视表。
要构建一个透视表,我们首先会调用我们想要处理的 DataFrame,然后是我们想要显示的数据,以及它们如何分组。
在这个例子中,我们将使用 all_names 数据,并按照一个维度中的名称和另一个维度中的年份来显示婴儿数据:
pd.pivot_table(all_names, 'Babies', 'Name', 'Year')
当我们键入 ALT + ENTER 来运行代码并继续时,我们将看到以下输出:
!pd.pivot_table(all_names, ‘Babies’, ‘Name’, ‘Year’) 输出
因为这显示了很多空值,我们可能希望将名称和年份保留为列,而不是在一个情况下作为行,在另一个情况下作为列。我们可以通过在方括号中对数据进行分组来实现:
pd.pivot_table(all_names, 'Babies', ['Name', 'Year'])
当我们键入 ALT + ENTER 来运行代码并继续时,这个表现在只会显示每个名称记录的年份的数据:
Name Year
Aaban 2007 5.0
2009 6.0
2010 9.0
2011 11.0
2012 11.0
2013 14.0
2014 16.0
2015 15.0
Aabha 2011 7.0
2012 5.0
2014 9.0
2015 7.0
Aabid 2003 5.0
Aabriella 2008 5.0
2014 5.0
2015 5.0
此外,我们可以将数据分组为名称和性别作为一个维度,年份作为另一个维度,如下所示:
pd.pivot_table(all_names, 'Babies', ['Name', 'Sex'], 'Year')
当我们运行代码并继续使用 ALT + ENTER 时,我们将看到以下表格:
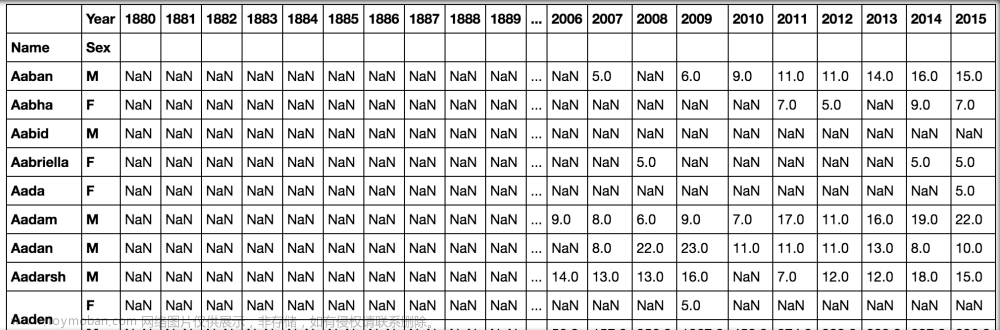
透视表让我们可以从现有表格中创建新表格,从而决定我们希望如何对数据进行分组。
可视化数据
通过使用 pandas 与其他包如 matplotlib,我们可以在笔记本中可视化数据。
我们将要可视化有关特定名称多年来的受欢迎程度的数据。为了做到这一点,我们需要设置和排序索引,以重新处理数据,从而可以看到特定名称受欢迎程度的变化。
pandas 包让我们可以进行分层或多级索引,这使我们能够存储和操作具有任意数量维度的数据。
我们将使用性别、名称和年份的信息来索引我们的数据。我们还希望对索引进行排序:
all_names_index = all_names.set_index(['Sex','Name','Year']).sort_index()
键入 ALT + ENTER 来运行并继续到我们的下一行,我们将让笔记本显示新的索引 DataFrame:
all_names_index
运行代码并继续使用 ALT + ENTER,输出将如下所示:
!all_names_index 输出
接下来,我们将编写一个函数,用于绘制名称随时间的受欢迎程度。我们将命名该函数为 name_plot,并将 sex 和 name 作为参数传递,我们将在运行函数时调用这些参数。
def name_plot(sex, name):
现在,我们将设置一个名为 data 的变量来保存我们创建的表。我们还将使用 pandas DataFrame 的 loc 来根据索引的值选择我们的行。在我们的情况下,我们希望 loc 基于 MultiIndex 中的字段组合,涉及到 sex 和 name 数据。
让我们将这个构造写入我们的函数中:
def name_plot(sex, name):
data = all_names_index.loc[sex, name]
最后,我们将使用 matplotlib.pyplot 来绘制值,我们将其导入为 pp。然后,我们将性别和名称数据的值绘制到索引上,对于我们的目的来说,索引是年份。
def name_plot(sex, name):
data = all_names_index.loc[sex, name]
pp.plot(data.index, data.values)
键入 ALT + ENTER 来运行代码并移动到下一个单元格。现在,我们可以使用我们选择的性别和名称调用函数,比如使用给定名称 Danica 的女性名称 F。
name_plot('F', 'Danica')
当你现在键入 ALT + ENTER,你将收到以下输出:
!Danica 名称绘图 输出
请注意,根据您使用的系统,您可能会收到有关字体替换的警告,但数据仍将正确绘制。
通过查看可视化,我们可以看到女性名称 Danica 在 1990 年左右有一小波动,并在 2010 年之前达到了高峰。
我们创建的函数可以用于绘制多个名称的数据,以便我们可以看到不同名称随时间的趋势。
让我们首先将我们的绘图稍微放大一点:
pp.figure(figsize = (18, 8))
接下来,让我们创建一个包含我们想要绘制的所有名称的列表:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
现在,我们可以通过 for 循环遍历列表,并绘制每个名称的数据。首先,我们将尝试将这些性别中性名称作为女性名称:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)
为了使这些数据更容易理解,让我们包括一个图例:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)
pp.legend(names)
我们将键入 ALT + ENTER 来运行代码并继续,然后我们将收到以下输出:
!名称绘图,女性名称 输出
尽管每个名称作为女性名称的受欢迎程度都在缓慢增长,但在 1980 年左右,名称 Jamie 作为女性名称非常受欢迎。
让我们以相同的名称绘制相同的名称,但这次作为男性名称:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('M', name)
pp.legend(names)
再次键入 ALT + ENTER 来运行代码并继续。图表将如下所示:
!名称绘图,男性名称 输出
这些数据显示了更多名称的受欢迎程度,Jesse 通常是最受欢迎的选择,并且在 1980 年代和 1990 年代特别受欢迎。
从这里,您可以继续使用名称数据,创建关于不同名称及其受欢迎程度的可视化,并创建其他脚本来查看不同数据以进行可视化。
结论
本教程介绍了处理大型数据集的方法,从设置数据开始,到使用 groupby() 和 pivot_table() 对数据进行分组,使用 MultiIndex 对数据进行索引,并使用 matplotlib 包可视化 pandas 数据。
许多组织和机构提供数据集,您可以继续学习 pandas 和数据可视化。例如,美国政府通过 data.gov 提供数据。文章来源:https://www.toymoban.com/news/detail-827354.html
您可以通过阅读我们的指南了解如何使用 matplotlib 可视化数据,包括《如何使用 matplotlib 在 Python 3 中绘制数据》和《如何使用 Python 3 和 matplotlib 绘制词频图表》。文章来源地址https://www.toymoban.com/news/detail-827354.html
到了这里,关于Python 3 中使用 pandas 和 Jupyter Notebook 进行数据分析和可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!