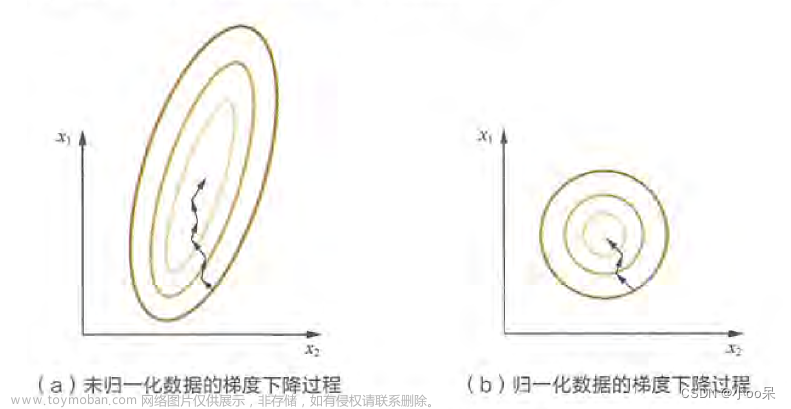
在机器学习中,梯度下降是一种常用的优化算法,用于寻找损失函数的最小值。我们可以用一个简单的爬山场景来类比梯度下降的过程。
假设你被困在山上,需要找到一条通往山下的路。由于你是第一次来到这座山,对地形不熟悉,你只能通过尝试和观察周围环境来找到下山的路。梯度下降就是这个过程中的“尝试和观察”方法。
梯度下降的步骤如下:
-
你站在山上的一个随机位置,并观察周围的地形。你发现某个方向的地势较低,说明这个方向可能是下山的路。
-
你沿着这个方向走一步,然后再次观察周围的地形。如果地势继续降低,说明你走的方向是正确的,你可以继续沿着这个方向走。
-
如果地势不再降低,甚至开始上升,说明你走错了方向。这时,你需要重新观察周围的地形,寻找一个新的方向。
-
重复这个过程,直到你找到通往山下的路,或者到达一个足够接近山下的位置。
在机器学习中,这个过程是这样的:
-
你有一个损失函数,表示模型预测值与真实值之间的差距。损失函数的值越大,说明模型的预测越不准确。
-
你随机初始化模型参数,然后计算损失函数的值。这相当于站在山上的一个随机位置,并观察周围的地形。
-
你计算损失函数的梯度,梯度告诉你应该朝着哪个方向调整模型参数,以便在下次预测时减少损失,更接近真实值。这相当于寻找地势较低的方向。
-
你沿着梯度的方向调整模型参数,然后再次计算损失函数的值。如果损失函数的值降低,说明你走的方向是正确的,你可以继续沿着这个方向调整模型参数。
-
如果损失函数的值不再降低,甚至开始上升,说明你走错了方向。这时,你需要重新计算梯度,寻找一个新的方向。
-
重复这个过程,直到损失函数的值足够小,或者达到一个预设的迭代次数。
通过梯度下降,模型可以在每次迭代中逐步调整参数,使损失函数的值越来越小,从而提高预测的准确性。这个过程就像在山上寻找下山的路,通过不断地尝试和观察,最终找到通往山下的最佳路径。文章来源:https://www.toymoban.com/news/detail-827453.html
 文章来源地址https://www.toymoban.com/news/detail-827453.html
文章来源地址https://www.toymoban.com/news/detail-827453.html
到了这里,关于机器学习中为什么需要梯度下降的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!