一、 窗口函数知识点
1.1 窗户函数的定义
窗口函数可以拆分为【窗口+函数】。窗口函数官网指路:
LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageManual%20WindowingAndAnalytics
- 窗口:over(),指明函数要处理的数据范围
- 函数:指明函数计算逻辑
1.2 窗户函数的语法
<窗口函数>window_name over ( [partition by 字段...] [order by 字段...] [窗口子句] )
- window_name:给窗口指定一个别名。
- over:用来指定函数执行的窗口范围,如果后面括号中什么都不写,即over() ,意味着窗口包含满足where 条件的所有行,窗口函数基于所有行进行计算。
- 符号[] 代表:可选项; | : 代表二选一
- partition by 子句: 窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行。分组间互相独立。
- order by 子句:每个partition内部按照哪些字段进行排序,如果没有partition ,那就直接按照最大的窗口排序,且默认是按照升序(asc)排列。
- 窗口子句:显示声明范围(不写窗口子句的话,会有默认值)。常用的窗口子句如下:
1.3 窗口子句范围大小的控制
rows 或 range子句往往来控制窗口的边界范围,其语法如下:

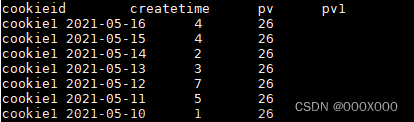
rows between unbounded preceding and unbounded following; -- 上无边界到下无边界(一般用于求 总和)
rows between unbounded preceding and current row; --上无边界到当前记录(累计值)
rows between 1 preceding and current row; --从上一行到当前行
rows between 1 preceding and 1 following; --从上一行到下一行
rows between current row and 1 following; --从当前行到下一行1.4 rows与range的区别
- rows:rows是真实的行数,也就是我们实际中所说的1,2,3...连续的行数。
- range:range是逻辑上的行数,需要通过计算才能知道是哪一行。
ps: over()里面有order by子句,但没有窗口子句时 ,即: <窗口函数> over ( partition by 字段... order by 字段... ),此时窗口子句是有默认值的 --> rows between unbounded preceding and current row (上无边界到当前行)。 此时窗口函数语法:
<窗口函数> over ( partition by 字段... order by 字段... ) 等价于 <窗口函数> over ( partition by 字段... order by 字段... rows between unbounded preceding and current row)
需要注意有个特殊情况:当order by 后面跟的某个字段是有重复行的时候, <窗口函数> over ( partition by 字段... order by 字段... ) 不写窗口子句的情况下,窗口子句的默认值是:range between unbounded preceding and current row(上无边界到当前相同行的最后一行)。
因此,遇到order by 后面跟的某个字段出现重复行,且需要计算【上无边界到当前行】,那就需要手动指定窗口子句 rows between unbounded preceding and current row ,偷懒省略窗口子句会出问题~
总结如下:
1、窗口子句不能单独出现,必须有order by子句时才能出现。
2、当省略窗口子句时:
a) 如果存在order by则默认的窗口是unbounded preceding and current row --当前组的第一行到当前行,即在当前组中,第一行到当前行
b) 如果没有order by则默认的窗口是unbounded preceding and unbounded following --整个组
口诀:
- 有partition by 且有order by,窗口范围:分组中第一行到当前行
- 有partition by 无order by ,窗口范围:整个分组
- 无partition by 且有order by 窗口范围:整个表中第一行到当前行
- 无partition by 无order by,窗口范围:整个分组,即over()
1.5 窗口函数执行顺序
一般而言:sql 执行顺序
from ->
join ->
on ->
where ->
group by->
with (可以在分组后面加上 with rollup,在分组之后对每个组进行全局汇总) ->
select 后面的普通字段,聚合函数->
having(having中可以使用select 字段别名) ->
distinct ->
order by ->
limit窗口函数的执行顺序: 窗口函数是作用于select后的结果集。即:select 的结果集作为窗口函数的输入。窗口函数的执行结果只是在原有的列中单独添加一列,形成新的列,它不会对已有的行或列做修改。窗口函数简化版的执行顺序:

窗口函数具体实现原理解析:
select channel,
month,
sum(amount) as sum,
dense_rank() over (partition by channel order by sum(amount) desc) as dr,
row_number() over(partition by channel order by sum(amount) desc) as rn
from sales
group by channel,
month;上述代码执行过程有两个阶段:
step1 : 计算除窗口函数以外的其他运算,如 from 、join 、where、group by、having等。上面的代码的第一阶段:
select channel,
month,
sum(amount) as sum
from sales
group by channel, month;step2:将step1 的输出作为 WindowingTableFunction窗口函数的输入,计算对应的窗口函数值。

1.6 条件判断语句嵌套window子句的执行顺序
HiveSQL——条件判断语句嵌套windows子句的应用-CSDN博客文章浏览阅读1.4k次,点赞42次,收藏21次。HiveSQL——条件判断语句嵌套windows子句的应用https://blog.csdn.net/SHWAITME/article/details/136079305?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170763988016800180626588%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170763988016800180626588&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-136079305-null-null.nonecase&utm_term=%E6%9D%A1%E4%BB%B6&spm=1018.2226.3001.4450 结论:
- case when(或 if)语句中嵌套窗口函数时,条件判断语句的执行顺序在窗口函数之后
- 窗口函数partition by子句中是可以嵌套条件判断语句的 case when(或 if)
1.7 窗口函数中的partition by分组与group by的区别
-
group by 汇总后行数减少,partition by汇总后原表中的行数没变。
-
group by分组后,一组中只返回一个结果。窗口函数中partition by分组,每组每行中都会有一个分析结果。


-
group by分组后,select中的字段必须是group by的字段、sum()等聚合函数或常量;但是窗口函数中的partition by 分组就没有此限制,窗口函数分析的结果可以与表中其他字段并列,其相当于在原表每个分组中新增了一列。
举例:
CREATE TABLE t_order (
oid int ,
uid int ,
otime string,
oamount int
)
ROW format delimited FIELDS TERMINATED BY ",";
load data local inpath "/opt/module/hive_data/t_order.txt" into table t_order;with tmp as (
select
oid,
uid,
otime,
oamount,
date_format(otime, 'yyyy-MM') as dt,
---计算rk的目的是为了获取记录中的第一条
row_number() over (partition by uid,date_format(otime, 'yyyy-MM') order by otime) rk
from t_order
order by uid
)
select
uid,
--每个用户一月份的订单数
sum(if(dt = '2018-01', 1, 0)) as m1_count,
--每个用户二月份的订单数
sum(if(dt = '2018-02', 1, 0)) as m2_count,
--每个用户三月份的订单数(当月订单金额超过10元的订单个数)
sum(if(dt = '2018-03' and oamount > 10, 1, 0)) m3_count,
--当月(3月份)首次下单的金额
sum(if(dt = '2018-03' and rk = 1, oamount, 0)) m3_first_amount,
-- 开窗函数
row_number() over (partition by uid order by sum(if(dt = '2018-01', 1, 0)))rk
from tmp
group by uid
having m1_count >0 and m2_count=0;

-
根据HiveSQL的执行顺序得到,窗口函数的执行是在group by,having之后进行,是与select同级别的。如果SQL中既使用了group by又使用了partition by,那么此时partition by的分组是基于group by分组之后的结果集进行的再次分组,即窗口函数分析的数据范围也是基于group by后的数据。

-
窗口中的partition by分组后,并没有去重功能,而group by具有去重功能
二、窗口函数运用案例
聚合窗口函数-——聚合开窗求累积汇总值
HiveSQL题——聚合函数(sum/count/max/min/avg)-CSDN博客文章浏览阅读1.1k次,点赞19次,收藏19次。HiveSQL题——聚合函数(sum/count/max/min/avg)https://blog.csdn.net/SHWAITME/article/details/135918264排序窗口函数——排序开窗求topN
HiveSQL题——排序函数(row_number/rank/dense_rank)-CSDN博客文章浏览阅读1.3k次,点赞20次,收藏16次。HiveSQL题——排序函数(row_number/rank/dense_rank)https://blog.csdn.net/SHWAITME/article/details/135909662前后窗口函数
HiveSQL题——前后函数(lag/lead)_sql hive lead-CSDN博客文章浏览阅读1.2k次,点赞23次,收藏21次。HiveSQL题——前后函数(lag/lead)_sql hive leadhttps://blog.csdn.net/SHWAITME/article/details/135902998注:参考文章:文章来源:https://www.toymoban.com/news/detail-827682.html
窗口函数应用之移动范围计算【详细剖析窗口函数】(HiveSql面试题4详解)-CSDN博客文章浏览阅读3.5k次,点赞17次,收藏53次。本文通过案例来引出对窗口函数的认识,总结了窗口函数的用法及使用规律,该案例主要是对窗口函数在移动计算中的应用,类似于滑动窗口,所谓的滑动窗口也就是指每一行对应对应的数据窗口都不同,通过窗口子句类实现移动计算时数据的范围,也就是窗口每次按行滑动时长度大小,但窗口中每一次对应的数据总是在变化。通过本文你可以获得如下知识: (1)窗口函数的使用规则及用法 (2)窗口子句的使用规则 (3)窗口函数的意义 (4)窗口函数在移动计算中的应用_窗口函数应用之移动范围计算【详细剖析窗口函数】https://blog.csdn.net/godlovedaniel/article/details/106542519文章来源地址https://www.toymoban.com/news/detail-827682.html
到了这里,关于(07)Hive——窗口函数详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!