1.终端运行scrapy startproject movie,创建项目
2.接口查找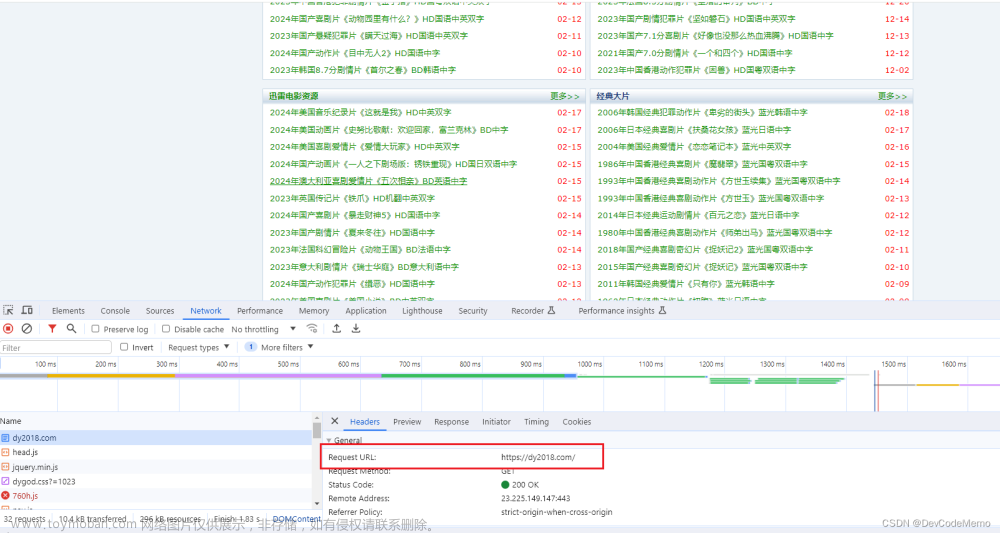
3.终端cd到spiders,cd scrapy_carhome/scrapy_movie/spiders,运行 scrapy genspider mv https://dy2018.com/
4.打开mv,编写代码,爬取电影名和网址

5.用爬取的网址请求,使用meta属性传递name ,callback调用自定义的parse_second
6.导入ScrapyMovieItem,将movie对象传递给管道下载
7.settings开启管道

8.下载爬取的movie对象存储到movie.json中

9.爬取的结果文章来源:https://www.toymoban.com/news/detail-827716.html
 文章来源地址https://www.toymoban.com/news/detail-827716.html
文章来源地址https://www.toymoban.com/news/detail-827716.html
到了这里,关于爬虫学习笔记-scrapy爬取电影天堂(双层网址嵌套)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!