一、《Benchmarking PathCLIP for Pathology Image Analysis》
1、Abstract:
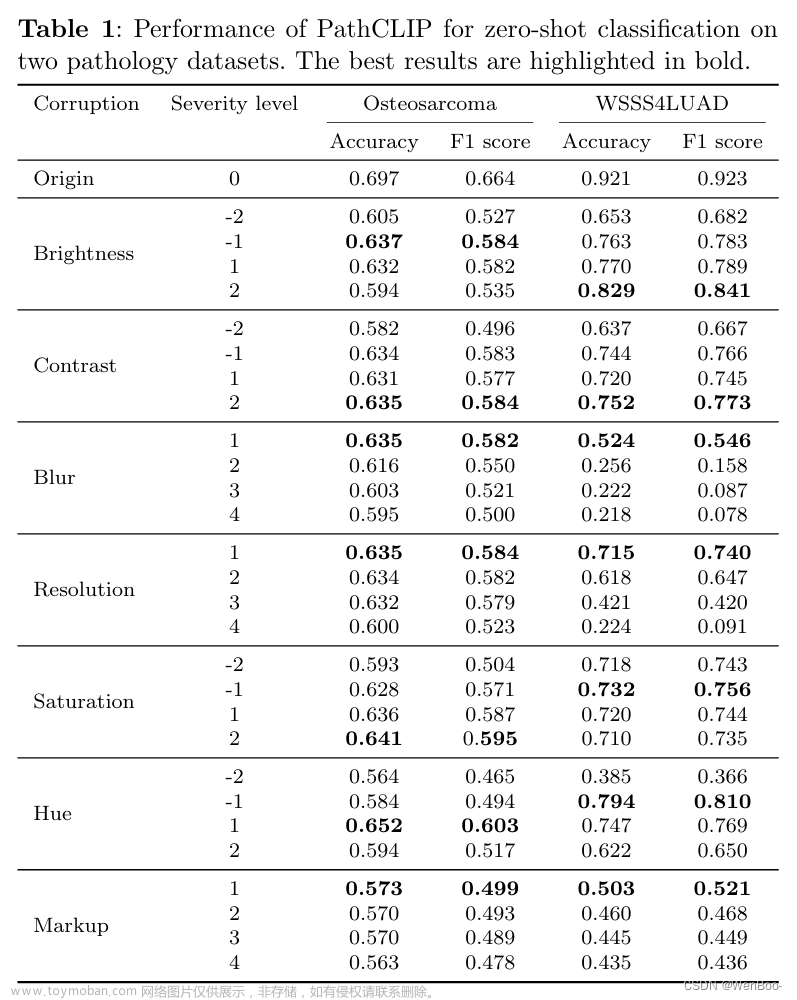
准确的图像分类和检索对于临床诊断和治疗决策具有重要意义。最近的对比语言图像预训练(CLIP)模型在理解自然图像方面表现出了显着的能力。从CLIP中汲取灵感,PathCLIP专为病理学图像分析而设计,在训练中使用超过200,000个图像和文本对。虽然PathCLIP的性能令人印象深刻,但其在各种图像损坏下的鲁棒性仍然未知。因此,我们进行了广泛的评估,以分析PathCLIP在骨肉瘤和WSSS 4LUAD数据集的各种损坏图像上的性能。在我们的实验中,我们引入了七种腐败类型,包括亮度,对比度,高斯模糊,分辨率,饱和度,色调和标记在四个严重程度。
通过实验,我们发现PathCLIP对图像污染具有较强的鲁棒性,在zero-shot分类方面优于OpenAI-CLIP和PLIP。在这七种损坏中,模糊和分辨率会导致PathCLIP的服务器性能下降。这表明,在进行临床测试之前,确保图像质量至关重要。此外,我们评估了PathCLIP在图像图像检索任务中的鲁棒性,揭示了PathCLIP在骨肉瘤上的表现不如PLIP有效,但在不同的腐败情况下在WSSS 4LUAD上表现更好。总体而言,PathCLIP提供了令人印象深刻的zero-shot分类和病理图像检索性能,但在使用它时需要适当的照顾。我们希望这项研究提供了一个定性的印象PathCLIP,并有助于了解它与其他CLIP模型的差异。
2、Conclusion:
在这项工作中,我们评估了PathCLIP在病理图像分析中的鲁棒性。具体来说,我们研究了PathCLIP在现实世界中七种常见类型的损坏上的性能。我们的发现表明,PathCLIP对损坏相对鲁棒,在零样本分类中优于OpenAI-CLIP和PLIP。在七种损坏中,模糊和分辨率可以显著影响PathCLIP的性能。因此,在应用临床测试之前确保图像质量很重要。我们还评估了PathCLIP在图像-图像检索任务中的鲁棒性。结果表明,在各种损坏下,PathCLIP在骨肉瘤方面的性能劣于PLIP。实验结果表明,PLIP可能更适合于骨癌的病理图像分析。为了临床应用,建议根据任务灵活使用其中一个CLIP模型。总的来说,PathCLIP作为病理图像中的零样本分类和图像-图像检索的基准模型具有很大的潜力。未来的工作将考虑在模型训练期间进行图像损坏,以实现鲁棒性能。另一个方向将专注于开发PathCLIP和大型语言模型,以实现深度多模态理解,其中AI可以根据文本和视觉输入理解和生成响应或病理诊断。
3、Result:
二、《Clinical-grade computational pathology using weakly supervised deep learning on whole slide images》
from:Nature Medicine 2019
参考文章:http://t.csdnimg.cn/9ZQqThttp://t.csdnimg.cn/9ZQqT
http://t.csdnimg.cn/8Bjzxhttp://t.csdnimg.cn/8Bjzx
http://t.csdnimg.cn/Yo6ZLhttp://t.csdnimg.cn/Yo6ZL
1、Abstract:
病理学决策支持系统的发展以及其在临床实践中的部署受到了对大量手动注释数据集需求的阻碍。为了克服这个问题,我们提出了一种基于多实例学习的深度学习系统,该系统仅使用报告的诊断作为训练标签,从而避免了昂贵且耗时的像素级手动注释。我们在一个规模庞大的数据集上评估了这一框架,该数据集包含44732张全切片图像,来自15187名患者,没有任何形式的数据管理。对前列腺癌、基底细胞癌和乳腺癌转移到腋窝淋巴结的测试结果显示,所有癌症类型的曲线下面积均超过0.98。其临床应用将使病理学家能够排除65-75%的幻灯片,同时保持100%的敏感性。我们的结果表明,该系统有能力以前所未有的规模训练准确的分类模型,为临床实践中部署计算决策支持系统奠定了基础。

2、Conclusion:
使用大规模的弱标签训练集训练得到的模型,其效果远好于使用少量像素级别专家标注训练集训练的效果,能够达到临床水平。
三、《PathAsst: Redefining Pathology through Generative Foundation AI Assistant for Pathology》
1、Abstract:
随着大型语言模型(LLM)和多模态技术的不断成熟,通用多模态大型语言模型(MLLM)的发展已经蓬勃发展,在自然图像解释方面具有显著的应用。然而,病理学领域在这方面仍未得到充分开发,尽管对准确、及时和个性化的诊断需求日益增长。为了弥补病理学MLLM领域的差距,我们在这项研究中提出了PathAsst,这是一个用于革新病理诊断和预测分析的生成式基础AI助手。为了开发PathAsst,我们从各种可靠来源收集了超过142K个高质量的病理图像-文本对,包括PubMed、全面的病理学教科书、著名的病理学网站以及由病理学家注释的私有数据。利用ChatGPT/GPT-4的先进功能,我们生成了超过180K个遵循指令的样本。此外,我们还设计了额外的遵循指令数据,专门针对病理学特定模型的调用,使PathAsst能够根据输入图像和用户意图有效地与这些模型进行交互,从而增强模型的诊断能力。随后,我们的PathAsst基于Vicuna-13B语言模型与CLIP视觉编码器进行训练。PathAsst的结果表明,利用AI驱动的生成式基础模型提高病理学诊断和治疗过程的潜力。我们致力于开源我们精心策划的数据集,以及旨在帮助研究人员广泛收集和预处理他们自己的数据集的综合工具包。
2、Conclusion:
3、Result:



四、《Task-specificFine-tuningviaVariationalInformationBottleneckfor Weakly-supervisedPathologyWholeSlideImageClassification》
from:CVPR 2023
1、Abstract:
虽然多实例学习(MIL)在数字病理学全切片图像(WSI)分析中表现出有前途的结果,但这种范式仍然面临着性能和泛化问题,因为计算成本高昂,而且对吉兆像素(Gigapixel)WSIs的监督有限。为了解决计算问题,之前的方法利用从ImageNet预训练得到的冷冻模型来获得表示,然而,由于领域差距大,可能会丢失关键信息,而且没有进行图像级别的训练时间数据增强,从而阻碍了泛化能力。尽管自监督学习(SSL)提出了可行的表示学习方案,但下游任务特定的特征通过部分标签调整并没有得到探索。为了缓解这个问题,我们提出了一种基于信息瓶颈理论的WSI微调框架。该理论使框架能够找到WSI的最小充分统计量,从而支持我们仅根据WSI级别的弱标签将主干微调为特定任务的表示。我们对WSI-MIL问题进行了进一步分析,从理论上推导出了我们的微调方法。我们在五个病理学WSI数据集上对各种WSI头进行了实验评估。实验结果表明,与之前的工作相比,该方法在准确性和泛化方面均取得了显著改进。
2、Conclusion:
在这项工作中,我们提出了一种基于弱监督的幻灯片级别标签的WSI分类微调方法。首先,我们引入了一个有效的信息瓶颈(IB)模块来降低Gigapixel WSI的训练成本,该模块将过大的数据包精简为稀疏数据包。然后,实例的主干能够在MIL框架中进行端到端训练,通过学习并对精简的数据包进行分类。因此,通过保留主要任务特定信息,WSI分类性能得到了提高。此外,自监督学习(SSL)可以与提出的框架相结合以实现进一步的改进。与完全监督学习相比,我们的方法可以利用极其微弱的WSI标签实现具有竞争力的准确度。此外,我们的训练方案可以为具有领域变化的数据库引入多种训练时间增强,这是之前工作不可避免的挑战。实验结果反映了我们的方法在准确性和泛化方面的进展。总的来说,我们提出的方法在真实世界病理诊断的MIL应用中具有很大的潜力,具有更好的性能、更快的收敛速度和注释效率。
3、Result:

五、《Color-S4L: Self-supervised Semi-supervised Learning with Image Colorization》
1、Abstract:
这项工作解决了半监督图像分类任务的问题,集成了几个有效的自我监督的预训练任务。与半监督学习中广泛使用的一致性正则化不同,本文提出了一种新的自监督半监督学习框架(Color-S4L),特别是图像着色代理任务,并深入评估了各种网络结构在这种特殊管道中的性能。此外,我们证明了它的有效性和最佳性能CIFAR-10,SVHN和CIFAR-100数据集相比,以前的监督和半监督的最佳方法。
2、Conclusion:
我们提出了一种新颖的Color-S4L模型,该模型将多个自监督的预训练任务与半监督学习框架相结合。此外,我们将自训练的有效图像着色模型嵌入到SSL管道中,与图像旋转和地理变换一起建立新的监督。此外,我们探索了6种CNN架构在SESEMI [22]和Color-S4L模型中的性能,甚至发现我们首次应用的Shake-WRN神经网络在SVHN数据集上超过了其他主干。
总的来说,我们深入研究了快速发展的自监督学习和半监督学习的整合,甚至提供了与之前半监督学习最先进方法相比具有竞争力的最佳结果。在未来的研究中,我们可以探索更多利用自监督表示学习为其他学习范式(如少样本学习和强化学习)的可能性。
3、Result:

六、《Analysis and Validation of Image Search Engines in Histopathology》
1、Abstract:
在组织学和组织病理学图像档案中搜索相似图像是一项至关重要的任务,可以帮助患者匹配各种目的,从分类和诊断到预后和预测。全载玻片图像(WSI)是安装在载玻片上的组织标本的高度详细的数字表示。将WSI与WSI匹配可以作为患者匹配的关键方法。在这篇论文中,我们对四种搜索方法(BoVW、Yottixel、SISH、RetCCL)及其一些潜在变种进行了广泛的分析和验证。我们分析了它们的算法和结构,并评估了它们的性能。为了进行这项评估,我们使用了四个内部数据集(1269名患者)和三个公开数据集(1207名患者),共计来自38个不同类别/亚类的超过200,000个补丁,覆盖五个主要站点。例如,某些搜索引擎,如BoVW,表现出显著的效率和速度,但准确率较低。相反,像Yottixel这样的搜索引擎表现出效率和速度,提供了适度准确的结果。最近提出的建议,包括SISH,表现出效率低下且结果不一致,而像RetCCL这样的替代方案在准确性和效率方面都表现不足。因此,进一步的研究对于解决病理组织学图像搜索中准确性和最小存储要求这两个方面的问题至关重要。
2、Conclusion:
该论文主要是解决WSI图像的匹配问题,能否从大量的历史数据中搜索出与新数据匹配的数据,从而更好地进行诊断。
在算法结构、搜索能力、训练和测试数据方面,我们对选定的四种搜索方法进行了比较。更重要的是,我们进行了广泛的实验,以比较它们的搜索性能。在算法结构比较方面,我们比较了它们用于分解WSI进行索引和匹配的切块方法。总体而言,通过比较它们的搜索能力,我们确定了它们是否能够处理/搜索补丁和WSI匹配。训练和测试数据的比较包括详细记录每个搜索引擎所用的训练或验证数据。最后,我们使用高质量的临床数据集和著名的公开数据集来量化每种方法的搜索性能。我们主要通过准确性、索引和搜索的时间测量、鲁棒性和存储要求来评估性能基准。
3、Result:

七、《 RudolfV: A Foundation Model by Pathologists for Pathologists》
1、Abstract:
组织学在临床医学和生物医学研究中起着核心作用。虽然人工智能在许多病理任务上显示出有希望的结果,但在训练数据稀缺的情况下,泛化和处理罕见疾病仍然是一个挑战。在从潜在有限的标记数据中学习之前,从未标记数据中提取知识到基础模型中,为解决这些挑战提供了一条可行的途径。在这项工作中,我们通过半自动数据管理和结合病理学家领域知识来扩展数字病理学全切片图像的基础模型的最新技术。具体而言,我们结合了计算和病理学家领域知识(1)来管理103k载玻片的多样化数据集,对应于7.5亿个图像块,涵盖来自不同固定、染色和扫描方案的数据以及来自欧盟和美国不同适应症和实验室的数据,(2)用于对语义相似的载玻片和组织块进行分组,以及(3)在训练期间增强输入图像。我们在一组公共和内部基准上评估了生成的模型,并表明尽管我们的基础模型是用数量级更少的幻灯片训练的,但它的性能与竞争模型相当或更好。我们预计,将我们的方法扩展到更多的数据和更大的模型将进一步提高其性能和能力,以处理诊断和生物医学研究中日益复杂的现实世界任务。
2、Conclusion:
这篇论文主要解决的是组织病理图像中的训练数据稀缺的问题;
这项工作表明,通过仔细整合病理领域知识,可以大幅提高性能,尽管使用幻灯片数量和模型参数数量比竞争模型少一个数量级,但当时表现最好的病理学基础模型。我们假设增加数据量、多样性和模型参数的数量将进一步提高我们的方法的性能。在后续工作中,我们将通过增加基准测试、消融研究以及增加数据和模型大小来扩展这篇论文。我们希望指出的是,虽然目前的工作重点是机器学习研究,但我们期望这些结果在未来的实际诊断和生物医学研究中发挥重要作用。因此,未来的研究将探索RudolfV在协助临床常规诊断和更复杂的任务(包括多模态建模)中的作用。
3、Result:



八、《Learn From Zoom: Decoupled Supervised Contrastive Learning For WCE Image Classification》
1、Abstract:
在无线胶囊内窥镜(WCE)图像中对病变进行准确的分类,对于胃肠道(GI)癌症的早期诊断和治疗至关重要。然而,这项任务面临诸多挑战,如病变很小以及背景干扰等。此外,WCE图像还表现出较高的类内方差和类间相似性,这增加了复杂性。为了解决这些挑战,我们提出了用于WCE图像分类的解耦监督对比学习(Decoupled Supervised Contrastive Learning),该方法通过注意力增强器生成的放大WCE图像来学习稳健的表示。具体而言,我们使用均匀下采样的WCE图像作为锚点,并将相同类别的WCE图像,特别是其放大图像作为正样本。这种方法利用解耦监督对比学习使特征提取器能够从同一图像的各种视图捕获丰富的表示。通过在10个周期内对这些表示训练一个线性分类器,实现了令人印象深刻的92.01%的整体准确率,在两个公开可用的WCE数据集的混合数据上超过了之前的最佳水平(SOTA)0.72%。
2、Conclusion:
在这篇论文中,我们提出了一种新颖的DSCL方法,以解决WCE领域中固有的挑战,包括较高的类内方差和类间相似性。通过利用注意力图放大病变区域,我们的方法促进了特征提取,使得在不同的类别中的WCE图像中捕获丰富且具有区分性的信息。我们在两个公开可用的WCE数据集的组合上进行了广泛的实验,证明了我们的方法的有效性和优越性与其他方法相比。
3、Result:


九、《LEGO:Language Enhanced Multi-modal Grounding Model》
from:ByteDance & Fudan University
1、Abstract:
多模态大型语言模型在不同模态的各种任务中表现出令人印象深刻的性能。然而,现有的多模态模型主要强调捕捉每个模态内的全局信息,而忽略了感知跨模态的局部信息的重要性。因此,这些模型缺乏有效理解输入数据的细粒度细节的能力,限制了它们在需要更细致理解的任务中的性能。为了解决这一限制,迫切需要开发能够跨多种模式进行细粒度理解的模型,从而增强其对广泛任务的适用性。在本文中,我们提出了LEGO,语言增强的多模态接地模型。除了像其他多模态模型一样捕获全局信息之外,我们提出的模型还擅长于需要详细了解输入中的局部信息的任务。它可以精确识别和定位图像中的特定区域或视频中的时刻。为了实现这一目标,我们设计了一个多样化的数据集构建管道,从而产生了一个用于模型训练的多模态、多粒度数据集。

2、Conclusion:
在这篇论文中,我们提出了一种名为LEGO的统一端到端多模态接地模型。通过在多样化多模态和多粒度数据集上进行训练,LEGO能够更好地感知多模态输入,并在需要精细理解的各项任务中表现出更好的性能。为了解决相关数据稀缺的问题,我们创建了一个多模态接地数据集,涵盖了各种模态、任务和粒度。为了鼓励这一领域的进一步发展,我们将公开提供我们的模型、代码和数据集。
在未来的工作中,我们计划扩展LEGO以适应更多的输入和输出模态,同时探索更复杂的接地方法。
3、Result:


十、《Enhancing Contrastive Learning with Efficient Combinatorial Positive Pairing》
1、Abstract:
在过去的几年中,对比学习在视觉无监督表示学习的成功中发挥了核心作用。大约在同一时间,高性能的非对比学习方法也得到了发展。尽管大多数工作只使用两个视图,但我们仔细回顾了现有的多视图方法,并提出了一个通用的多视图策略,可以加快任何对比或非对比方法的学习速度和性能。我们首先分析了CMC的全图范式,并从经验上表明,对于小学习率和早期训练,K-views的学习速度可以提高KC2倍。然后,我们通过混合由裁剪增强创建的视图、采用与SwAV多裁剪相同的小尺寸视图以及修改负采样来升级CMC的全图。最终的多视图策略被称为ECPP(高效组合正对配对)。我们通过将ECPP应用于SimCLR,并评估其在CIFAR-10和ImageNet-100上的线性评估性能,探讨了ECPP的有效性。对于每个基准测试,我们都取得了最佳性能。在ImageNet-100的情况下,ECPP提升了SimCLR的性能,超过了监督学习。
2、Conclusion:
在这项工作中,我们仔细研究了K-views的基本优势,并提出了高效的组合正对配对(ECPP)方法,这是一种简单的附加方法,可以增强对比学习和非对比学习方法的训练速度和效率。尽管对比学习和非对比学习被广泛应用于各种无监督表示学习任务中,但我们的实验仅限于视觉任务。我们的方法可以使用相对较小的计算量训练高性能的网络。这一特性对研究社区有所帮助。
3、Result:


十一、《Self-supervised Learning of Dense Hierarchical Representations for Medical Image Segmentation》
1、Abstract:
本文展示了一个自监督框架,用于学习为密集下游任务量身定制的体素式粗到细表示。我们的方法源于观察到,现有的分层表示学习的方法往往优先考虑全球功能的本地功能,由于固有的架构偏见。为了应对这一挑战,我们设计了一种训练策略,该策略平衡了多个尺度的特征的贡献,确保学习的表示能够捕获粗粒度和细粒度的细节。我们的策略包括3方面的改进:(1)本地数据增强,(2)分层平衡的架构,以及(3)混合对比恢复损失函数。我们在CT和MRI数据上评估了我们的方法,并证明了我们的新方法特别有利于有限注释数据的微调,并且在线性评估设置中始终优于基线对应物。
2、Conclusion:
我们提出了一种自监督框架,用于从无标签数据中学习层次平衡的体素级表示。我们的方法有效地缓解了基于FPN的嵌入所固有的不平衡问题,确保高分辨率和低分辨率特征对学到的体素表示做出同等贡献。我们证明,在线性评估设置中,我们的方法优于基线,并证明在标签数据有限的情况下,它在微调设置中具有特别的优势。
3、Result:

十二、《A Study on Self-Supervised Pretraining for Vision Problems in Gastrointestinal Endoscopy》
1、Abstract:
胃肠道内窥镜检查(GIE)中视觉任务的解决方案通常使用以ImageNet-1 k作为backbone的监督方式预训练的图像编码器。然而,使用现代自监督预训练算法和最近的10万个未标记GIE图像数据集(Hyperkvasir-unlabeled)可能会有所改进。在这项工作中,我们研究了在一系列GIE视觉任务中,使用ImageNet-1 k和Hyperkvasir-unlabeled(仅限自监督)以自监督和监督方式预训练ResNet 50和ViT-B骨干的模型的微调性能。除了为每个任务确定最合适的预训练管道和骨干架构之外,我们的研究结果还表明:自监督预训练通常比监督预训练为GIE视觉任务产生更合适的骨干;使用ImageNet-1 k的自监督预训练通常比使用Hyperkvasir-unlabeled的预训练更合适,但结肠镜检查中的单眼深度估计除外; ViT-B更适合于结肠镜检查中的息肉分割和单眼深度估计,ResNet 50更适合于息肉检测,并且两种架构在解剖标志识别和病理发现表征方面表现相似。我们希望这项工作引起人们对GIE视觉任务预训练的复杂性的关注,为这种比公约更合适的方法的发展提供信息,并激发对这一主题的进一步研究,以帮助推动这一发展
2、Conclusion:
在这项工作中,我们研究了图像编码器的预训练,以便将其用作GIE视觉任务解决方案中的骨干网络。我们考虑了编码器架构、预训练管道(数据和算法)和下游任务的变化。这是由于最近有机会改进使用ImageNet-1k进行监督预训练骨干网络的传统方法,即现代自监督预训练算法和Hyperkvasir-unlabelled(一个相对较大的未标记GIE图像数据集)。我们主要确定了考虑到的每个任务的最佳预训练管道和架构,通过调整编码器以适应任务,使用最先进的解码器对模型进行微调,并在包含任务合适注释的数据集上对结果模型进行微调,然后使用完善的度量标准在测试集上评估性能。总体而言,我们发现使用MAE算法和ImageNet-1k预训练的ViT-B骨干网络最为稳健。此外,我们的发现就GIE视觉任务解决方案中用作骨干的编码器的预训练提出了三条一般性原则,这些原则是通过分析下游性能得出的。这些原则包括:
• 自监督预训练通常比监督预训练产生更合适的骨干网络。这一结果具有重要意义,因为目前仍然采用在ImageNet-1k上进行监督预训练的骨干网络——这意味着可以通过自监督预训练改进当前的技术水平。此外,这一结果与涉及日常图像的任务的结果形成对比,在这些任务中,监督预训练通常会带来更好的性能。
• 使用ImageNet-1k进行自监督预训练通常比使用Hyperkvasir-unlabelled进行自监督预训练产生更合适的骨干网络,但结肠镜检查中的单眼深度估计除外。在这种情况下,使用Hyperkvasir-unlabelled进行自监督预训练产生更合适的骨干网络。
• ResNet50骨干网通常更适合息肉检测,而ViT-B骨干通常更好用于息肉分割和单目深度估计在结肠镜检查中,这两种架构的表现相似解剖标志识别和病理找到特征。
我们希望这篇论文能进一步鼓励对预训练图像编码器主题的研究,将其作为GIE视觉任务解决方案的骨干网络。首先,这项工作的范围可以扩展到更多的任务和数据集,以及解码器架构和微调程序。例如,我们考虑了更快的R-CNN对象检测管道,它是一个两阶段检测器,值得探讨的是我们的发现是否也适用于一阶段检测器。此外,我们还考虑了在结肠镜检查中对单目深度进行监督微调的情况,而对于单目深度进行自我监督微调也是一条有前途的研究途径,可能会受益于对预训练的探究。我们认为这样的研究应该为GIE任务提供更合适的骨干网络的发展奠定基础,这应该能够促进当前最佳状态的重大进步。除了扩展这项研究范围以及进一步探究现有预训练算法之外,我们还建议未来的工作应专门针对这个领域以及其他编码器架构研究预训练算法的发展。
3、Result:


十三、《Artificial Intelligence for Digital and Computational Pathology》
1、Abstract:
数字化组织切片的进步和人工智能(包括深度学习)的快速发展推动了计算病理学领域的发展。该领域在自动化临床诊断、预测患者预后和对治疗的反应以及从组织图像中发现新的形态学生物标志物方面具有巨大的潜力。其中一些基于人工智能的系统现在已被批准用于辅助临床诊断;然而,它们作为研究工具的广泛临床应用和集成仍然存在技术障碍。本文综述了计算病理学在预测全切片图像临床终点方面的最新方法学进展,并强调了这些进展如何实现临床实践的自动化和发现新的生物标志物。然后,随着该领域扩展到更广泛的临床和研究任务,临床数据的形式越来越多样化,我们提供了未来的前景。
2、Conclusion:
加速CPath领域进展的因素没有消退的迹象,从进展来看在将常规临床工作流程数字化以推进人工智能方面。尽管自动化劳动力的前景CPath已经对密集的手动工作和减少病理学家之间的诊断差异很感兴趣。通过使以下研究成为可能,具有成为病理学研究主要组成部分的潜力发现反映分子改变、患者预后和疾病进展的形态学生物标志物,预测治疗反应。CPath对临床实践和生物医学都有影响研究时,必须牢记两个目标:建立大规模、多样化和多模式的队列,以及使用更好的深度学习框架推进组织表征学习。这些目标不太可能实现在单个组织的范围内是可实现的。只有通过多方协调努力机构数据收集倡议、开源软件包和持续的技术灵感,能否实现上述目标取决于计算机视觉和人工智能研究的进步。
3、Result:

十四、《Attention-based Deep Multiple Instance Learning》
from:ICML 2018
1、Abstract:
多实例学习(MIL)是监督学习的一种变体,其中将单个类标签分配给一组实例。在本文中,我们将MIL问题描述为学习袋标签的伯努利分布,其中袋标签的概率由神经网络完全参数化。在此基础上,我们提出了一种基于神经网络的与注意力机制相对应的排列不变聚合算子。值得注意的是,所提出的基于注意力的算子的应用程序提供了对每个实例对袋标签的贡献的洞察。我们的经验表明,我们的方法在基准MIL数据集上实现了与最佳MIL方法相当的性能,并且在基于mist的MIL数据集和两个真实组织病理学数据集上优于其他方法,而不牺牲可解释性
2、Conclusion:
在本文中,我们提出了一种灵活且可解释的MIL方法,该方法是由神经网络完全参数化的。
我们概述了深度学习在对称函数基本定理中对置换不变袋分数函数建模的有用性。此外,我们提出了一种基于(门控)注意力机制的可训练MIL池。我们在五个MIL数据集、一个图像语料库和两个现实生活中的组织病理学数据集上进行了实证研究,结果表明我们的方法与表现最好的方法相当,或者在不同的评估指标方面表现最好。此外,我们表明,我们的方法通过呈现roi提供了对决策的解释,这在许多实际应用中非常重要。
我们坚信,目前的研究方向值得进一步研究。这里我们关注的是一个二元MIL问题,然而,多类MIL更有趣,也更具挑战性(Feng & Zhou, 2017)。此外,在某些应用中,值得考虑排斥点(Scott et al ., 2005),即一个包总是负的实例,或者假设一个包内实例之间的依赖关系(Zhou et al ., 2009)。我们把这些问题留给未来的研究。
3、Result:文章来源:https://www.toymoban.com/news/detail-827813.html
 文章来源地址https://www.toymoban.com/news/detail-827813.html
文章来源地址https://www.toymoban.com/news/detail-827813.html
到了这里,关于研一第二十一周论文阅读情况的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!