Python爬虫开发中有两个非常流行的工具:Scrapy框架和Requests库。它们各自有自己的优点和适用场景。
Scrapy
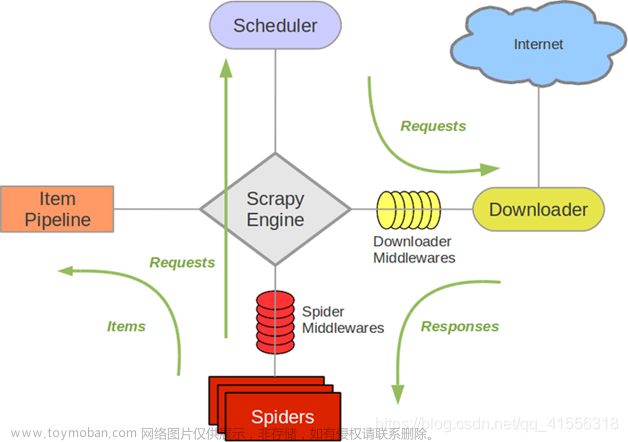
Scrapy是一个为了爬取网站并提取结构化数据而编写的应用框架,可以非常方便地实现网页信息的抓取。Scrapy提供了多种可配置、可重用的组件,如调度器、下载器、爬虫和管道等,使得开发者可以快速地构建出稳定、高效的网络爬虫。
Scrapy的主要特点包括:
- 异步处理:Scrapy基于Twisted异步网络库,可以处理网络I/O的非阻塞,提高爬取效率。
- 数据抽取:Scrapy内置了XPath和CSS选择器,可以方便地提取HTML或XML文档中的数据。
- 中间件:Scrapy提供了下载器中间件和爬虫中间件,可以方便地处理请求和响应,如设置代理、重试、重定向等。
- 管道:Scrapy的管道组件可以对爬取到的数据进行进一步的处理,如清洗、验证、持久化等。
- 调度器:Scrapy的调度器可以自动管理请求的优先级和去重,避免重复爬取和死循环。
- 可扩展性:Scrapy的架构和设计都非常灵活,可以通过自定义组件和插件来满足各种特殊需求。
Requests
相比于Scrapy,Requests库则更加轻量级和简洁,它是一个基于Python的HTTP客户端库,可以非常方便地发送HTTP请求和处理HTTP响应。Requests库对Python的标准库urllib进行了封装和优化,使得发送HTTP请求变得更加简单和人性化。
Requests的主要特点包括:
- 简洁易用:Requests的API设计非常简洁和直观,可以快速地发送GET、POST等HTTP请求,并获取响应内容。
- 自动化处理:Requests可以自动处理cookies、会话、重定向等HTTP特性,无需手动处理。
- 定制请求:Requests允许定制HTTP请求头、请求体、超时时间等参数,满足各种特殊需求。
- 异常处理:Requests提供了丰富的异常处理机制,可以方便地处理网络错误、超时等问题。
- 支持文件上传:Requests支持文件上传功能,可以方便地上传文件到服务器。
- 兼容性好:Requests兼容Python 2和Python 3,可以在不同的环境下使用。
适用场景
对于需要爬取大量数据、处理复杂逻辑、实现分布式爬取等场景,Scrapy框架更加适合。因为它提供了完整的爬虫框架和丰富的组件,可以快速地构建出稳定、高效的网络爬虫。同时,Scrapy还支持异步处理和多线程爬取,可以进一步提高爬取效率。文章来源:https://www.toymoban.com/news/detail-827939.html
而对于简单的HTTP请求处理和数据抓取场景,Requests库则更加适合。因为它轻量级、简洁易用,可以快速地发送HTTP请求并获取响应内容。同时,Requests还支持定制请求和异常处理等功能,可以满足各种特殊需求。文章来源地址https://www.toymoban.com/news/detail-827939.html
到了这里,关于Python爬虫开发:Scrapy框架与Requests库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!